







 本文提出鲁棒关键微调(RiFT),通过针对对抗训练模型的非鲁棒关键模块微调,改善其泛化性,实验证明在CIFAR10等数据集上,RiFT提高了约1.5%的泛化性,同时保持对抗鲁棒性。
本文提出鲁棒关键微调(RiFT),通过针对对抗训练模型的非鲁棒关键模块微调,改善其泛化性,实验证明在CIFAR10等数据集上,RiFT提高了约1.5%的泛化性,同时保持对抗鲁棒性。
本文提出了「鲁棒关键微调」,通过「微调」对抗训练模型的「非鲁棒关键性模块」,充分利用其冗余能力提升泛化性。
对抗训练(Adversarail Training)增强了模型对抗鲁棒性,但其代价往往是泛化能力的下降。本文提出了「鲁棒关键微调」(Robustness Critical Fine-Tuning,RiFT),通过「微调」对抗训练模型的「非鲁棒关键性模块」,充分利用其冗余能力提升泛化性。在 CIFAR10、CIFAR100 和 Tiny-ImageNet 数据集上的实验表明RiFT可以提高模型泛化性约 1.5%,同时保持对抗鲁棒性,达到了对抗鲁棒性和泛化能力更好的 trade-off。
论文标题:Improving Generalization of Adversarial Training via Robust Critical Fine-Tuning
文章链接:https://arxiv.org/abs/2308.02533
代码链接:https://github.com/microsoft/robustlearn
文章作者为中国科学院自动化研究所硕士生朱凯捷,指导老师为王晋东、杨戈,其他作者分别来着微软亚洲研究院、香港城市大学。
随着深度学习模型的能力变得越来越强,泛化性和鲁棒性已经成为深度学习领域的核心议题。这两个特性直接关系到模型是否能在真实世界的多样化环境中稳健、准确地执行其任务。
「泛化性」(Generalization)通常指机器学习模型在未见过的新数据上的性能表现。以数据类型进行分类可以细分为为以下两大类:
-
分布内(In-distribution)泛化:模型在与训练数据同分布的测试数据上的性能。这是深度学习算法的基本,其目标是确保模型能够理解和利用在训练集中存在的模式。
-
分布外(Out-of-distribution)泛化:模型在与训练数据有所差异或完全不同分布的数据上的表现。随着技术的发展,这种泛化能力变得尤为重要,因为现实世界中的数据的分布经常存在着不可预见的变化和偏移。
 分布内泛化和分布外泛化的一个例子。这里分布外泛化指图片的分布从真实世界的小狗图片偏移到了动漫图片。
分布内泛化和分布外泛化的一个例子。这里分布外泛化指图片的分布从真实世界的小狗图片偏移到了动漫图片。
「鲁棒性」(Robustness)则主要关注模型面对各种挑战时的稳定性和可靠性。尤其是,模型需要在面对潜在的对抗攻击(Adversarial Attack)时仍能保持其性能。对抗鲁棒性(Adversarial Robustness)是其中的一个关键方面,涉及模型在面对输入存在微小的对抗扰动时仍然能够正确分类的能力。 对抗鲁棒性的一个例子。给大熊猫图片加入一个肉眼难以分辨的噪声,模型即将其分类为了“长臂猿”。图片来源:[1]
对抗鲁棒性的一个例子。给大熊猫图片加入一个肉眼难以分辨的噪声,模型即将其分类为了“长臂猿”。图片来源:[1]
对抗训练的目标是最小化鲁棒损失(Robust Loss, [2]),即: 对抗鲁棒性和泛化性是否相互矛盾?
对抗鲁棒性和泛化性是否相互矛盾?
泛化性与鲁棒性二者是否可以兼得,目前仍处于争议中。有研究表明[3],即使在线性分类这样简单的问题,泛化性与鲁棒性都不可兼得。下面的表格数据从RobustBench的摘取:可以看出,对抗训练极大的提升了模型的对抗鲁棒性,但代价是降低了模型的分布内泛化性。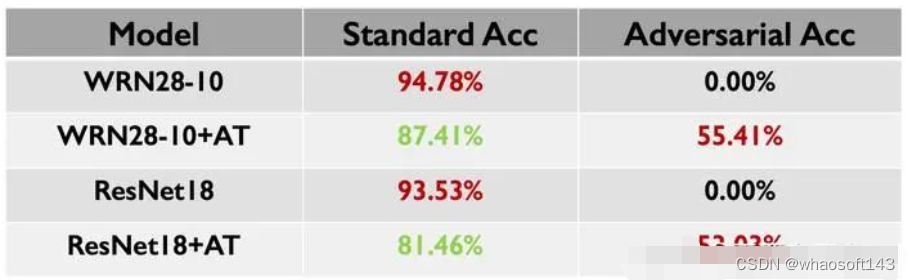 现有研究关注于如何在「对抗训练过程中」缓解该矛盾:
现有研究关注于如何在「对抗训练过程中」缓解该矛盾:
-
为不同训练数据设计不同的权重 [4]
-
增加无标注数据 [5]
-
修改损失函数 [6]
一个自然的问题是:可否通过 「微调」 对抗训练后的模型来进一步缓解鲁棒性与泛化性的矛盾? 这种解决方案有以下两点优势:
-
高效,如果尝试通过修改对抗训练算法来缓解,则需要重新进行对抗训练,费时费力
-
易用,微调方法可以与任意对抗训练算法结合
模型鲁棒关键性(Module Robust Criticality)
有研究表明,完全微调(Fully fine-tuning,即微调所有层的参数)会破坏模型已学习到的鲁棒特征[7, 8]。这就启发我们要选择那些 「对模型鲁棒性不够“关键”的参数」 进行微调。那么如何界定模型参数对鲁棒性的关键程度呢?
在这里先简要介绍一下loss landscape概念,下图是一个二维的例子。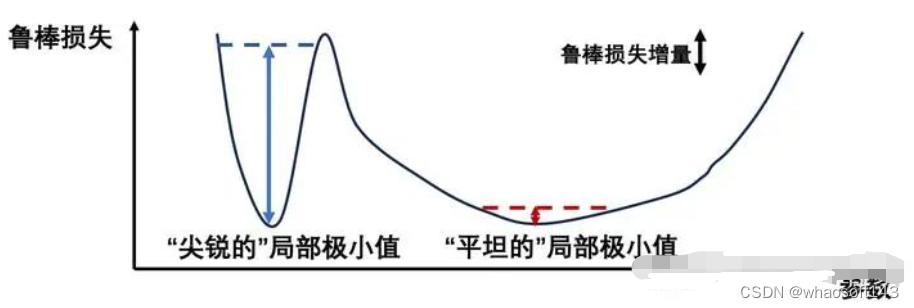 可以看到,不同的局部极小值,同样的扰动范围,鲁棒损失变化大不相同。「平坦的局部极小意味着对参数进行微小改动不会影响模型鲁棒性。」
可以看到,不同的局部极小值,同样的扰动范围,鲁棒损失变化大不相同。「平坦的局部极小意味着对参数进行微小改动不会影响模型鲁棒性。」 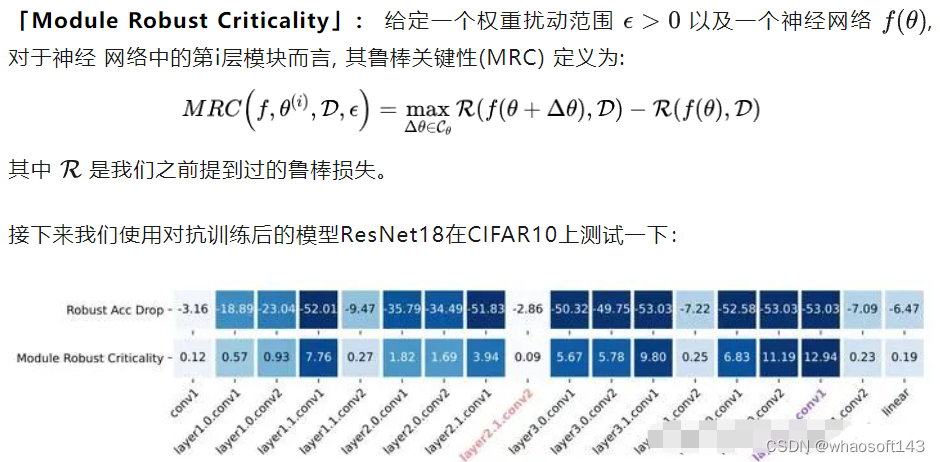 可以看出,不同模块对模型鲁棒性的关键程度是不同的。例如,layer2.1.conv2模块在最坏扰动(Worst-case weight perturbation)下对模型鲁棒性的影响极小,鲁棒准确率只下降了2.86%,表明该模块存在 「冗余」 的鲁棒能力。相反,对于layer4.1.conv1模块,最坏情况下的权重扰动会产生很大影响,导致鲁棒性准确性下降了53.03%之多。
可以看出,不同模块对模型鲁棒性的关键程度是不同的。例如,layer2.1.conv2模块在最坏扰动(Worst-case weight perturbation)下对模型鲁棒性的影响极小,鲁棒准确率只下降了2.86%,表明该模块存在 「冗余」 的鲁棒能力。相反,对于layer4.1.conv1模块,最坏情况下的权重扰动会产生很大影响,导致鲁棒性准确性下降了53.03%之多。
基于MRC的定义,我们可以证明,模型在\epsilon\epsilon范围内进行微调,其鲁棒损失值不会超过MRC值。从直观上来说很容易理解,因为MRC就是在求\epsilon\epsilon参数范围鲁棒损失的变化最大值,即求一个最坏情况下的权重扰动。因此,微调所造成的鲁棒损失上升值(通常不太可能和最坏情况下的权重扰动方向一致)一定不会超过MRC的值。
需要注意的是,MRC求解需要同时找到最坏情况下的输入扰动(即对抗样本)和最坏情况下的权重扰动,这样的求解是十分复杂且费时的,本文在求解MRC时做了松弛处理,固定了对抗样本,具体请参见论文。
RiFT: Robust Critical Fine-Tuning
定义完模型的鲁棒关键性后,我们就可以对其进行微调了。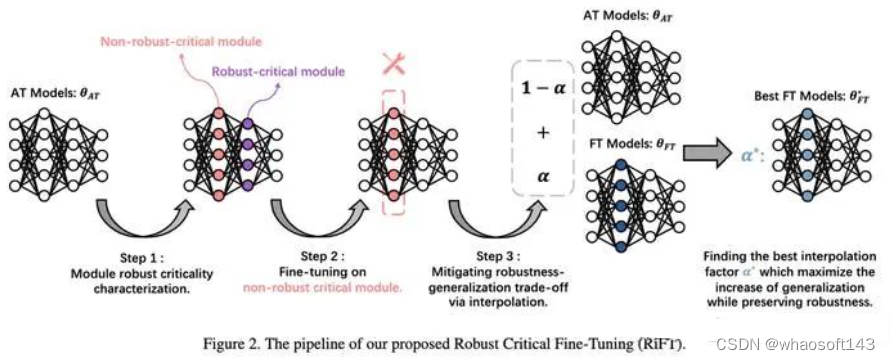 RiFT总共分为3步:
RiFT总共分为3步:
-
「刻画」:刻画不同模块的鲁棒关键性
-
「微调」:对非鲁棒关键性模块进行微调,冻结其他模块的权重
-
「插值」:将微调后的模型参数和原始的对抗训练模型参数进行插值,寻找最优的插值系数
我们在MRC章节提到,如果在给定的\epsilon\epsilon参数范围内对模型进行微调,其鲁棒损失值不会超过MRC值。在第二步,我们没有刻意的约束参数微调的范围,而是选择通过插值来寻找最优的点。 whaosoft aiot http://143ai.com
下图是在CIFAR10数据集上对ResNet18不同模块上进行微调然后插值得到的结果,每个点表示微调得到的最终权重与初始对抗训练权重之间的不同插值点。可以看出,只有对非鲁棒性关键模块(layer2.1.conv2)进行微调才能保持模型的鲁棒性。此外,在初始插值阶段,对非鲁棒性关键模块进行微调还可「提高对抗鲁棒性」约0.3%。
实验结果
我们使用ResNet18, ResNet34和WideResNet34-10在CIFAR10, CIFAR100以及Tiny-ImageNet上进行了实验,可以看出,经过RiFT微调后,模型的对抗鲁棒性保持几乎不变的同时,能提升模型的分布内以及分布外泛化性约1.5%。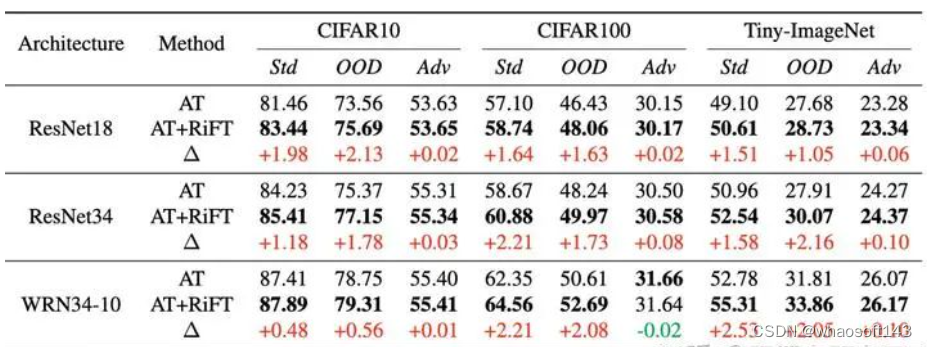 此外,我们还结合了其他对抗训练算法,包括TRADES, MART, AWP以及SCORE。其结果如下。可以看出,我们的方法同时可以结合其他的对抗训练算法,进一步提升对抗训练模型的泛化性。
此外,我们还结合了其他对抗训练算法,包括TRADES, MART, AWP以及SCORE。其结果如下。可以看出,我们的方法同时可以结合其他的对抗训练算法,进一步提升对抗训练模型的泛化性。 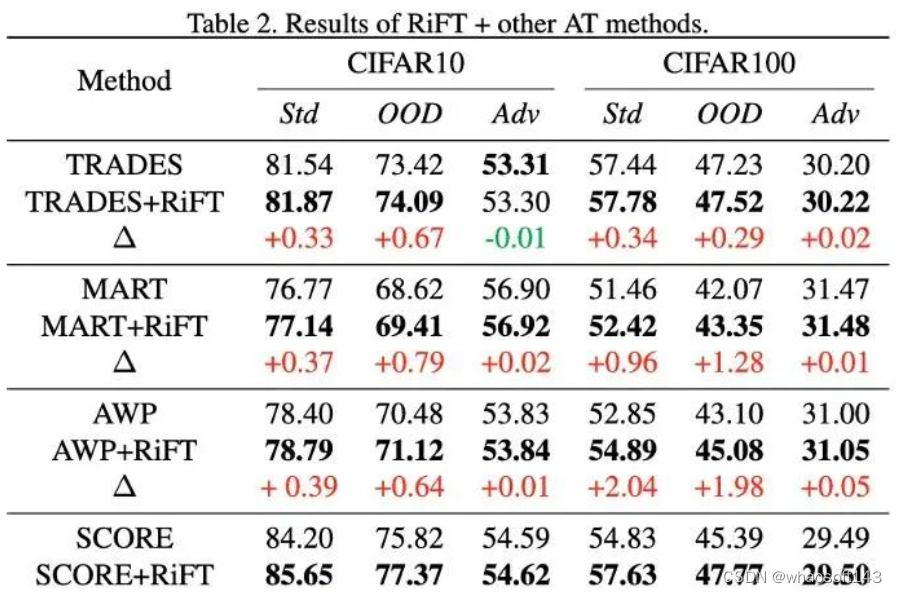

















 2639
2639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









