







RetNet与ViT完美结合!超越SWin Transformer 5个点的RMT来啦
作者将RetNet和Transformer结合起来,提出了RMT。在所有模型中,当模型的大小相似并采用相同的策略进行训练时,RMT在Top1准确率方面表现最佳。此外,RMT在目标检测、实例分割和语义分割等下游任务中明显优于现有的视觉Backbone模型。
Transformer首次出现在自然语言处理领域,后来迁移到计算机视觉领域,在视觉任务中表现出出色的性能。然而,最近,Retentive Network(RetNet)作为一种有可能取代Transformer的架构出现,引起了自然语言处理社区的广泛关注。因此,作者提出了一个问题,即将RetNet的思想迁移到视觉领域是否也能为视觉任务带来出色的性能。为了解决这个问题,作者将RetNet和Transformer结合起来,提出了RMT。受RetNet启发,RMT在视觉Backbone中引入了显式衰减,将与空间距离相关的先验知识引入到视觉模型中。这种与距离相关的空间先验允许显式控制每个Token可以关注的Token范围。此外,为了降低全局建模的计算成本,作者沿图像的两个坐标轴分解了这个建模过程。
大量的实验表明,RMT在各种计算机视觉任务中表现出色。例如,RMT仅使用4.5G FLOPs在ImageNet-1k上实现了84.1%的Top1准确率。据作者所知,在所有模型中,当模型的大小相似并采用相同的策略进行训练时,RMT在Top1准确率方面表现最佳。此外,RMT在目标检测、实例分割和语义分割等下游任务中明显优于现有的视觉Backbone模型。
自从Transformer在自然语言处理领域提出以来,它在许多下游任务中取得了出色的表现。尽管计算机视觉和自然语言处理之间存在模态差异,研究人员成功地将这种架构迁移到了视觉任务中,再次给作者带来了与以前的自然语言处理任务一样的巨大惊喜。
最近,自然语言处理领域出现了一些强大的架构,然而还没有任何工作尝试将这些自然语言处理架构转移到视觉任务中。与Transformer相比,RetNet在多个自然语言处理任务中表现出更强的性能。因此,作者希望能够将这个强大的自然语言处理架构RetNet转移到视觉领域。
RetNet中的基本运算符是Retention。Retention和Transformer中的基本的自注意力运算符之间的一个重要区别是引入了衰减系数,这些系数明确地控制每个Token相对于其相邻Token的注意力权重,确保注意力权重随着Token之间的距离增加而衰减。这种衰减有效地将一维距离的先验知识引入到模型中,从而提高了性能。
基于RetNet的研究结果,作者尝试进一步改进Retention机制,使其适应二维形式,并将其引入到视觉任务中。具体来说,原始版本的Retention机制经历了单向衰减,适用于自然语言处理的因果属性。然而,对于没有因果属性的图像,这种单向衰减是不适用的。
因此,作者首先将Retention机制从单向扩展到双向。此外,原始版本的Retention机制设计用于一维顺序信息,不适合在二维空间中使用。因此,考虑到二维空间的空间特性,作者设计了基于二维距离的衰减矩阵。最后,为了解决视觉Backbone早期阶段大量Token带来的高计算负荷问题,作者将二维计算过程分解为沿图像的两个坐标轴分别进行。作者将适用于图像的这种机制命名为Retention自注意力(ReSA)机制。基于ReSA机制,作者构建了RMT系列。
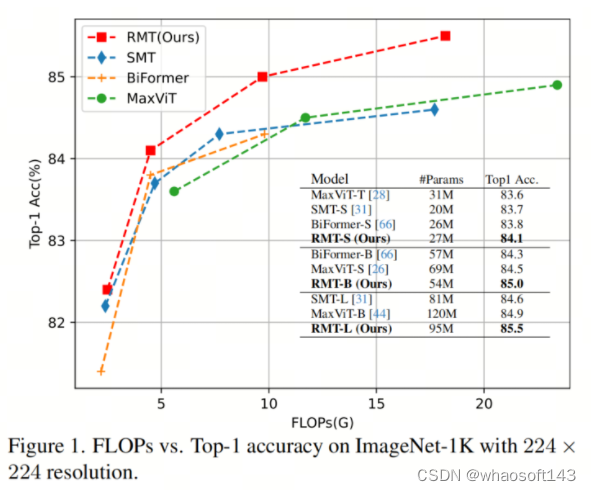
作者通过广泛的实验来证明所提出的方法的有效性。如图1所示,作者的RMT在图像分类任务上明显优于最先进的模型(SOTA)。此外,与其他模型相比,作者的模型在目标检测和实例分割等任务中具有更明显的优势。作者的贡献可以总结如下:
-
作者将Retentive Network的核心机制Retention扩展到了二维情景,引入了与距离相关的空间先验知识到视觉模型中。新的机制被称为Retention自注意力(ReSA)。
-
作者将ReSA沿着两个图像轴进行分解,降低了计算复杂性。这种分解方法有效地减小了计算负担,同时对模型性能的影响最小。
-
广泛的实验证明了RMT的出色性能。特别是在目标检测和实例分割等下游任务中,RMT表现出明显的优势。
相关工作
Transformer
Transformer的提出旨在解决递归模型的训练限制,并在许多自然语言处理任务中取得了巨大成功。通过将图像分割为小的、不重叠的Patch序列,视觉Transformer(ViTs)也引起了广泛关注,并在视觉任务中得到了广泛应用。
与过去不同,RNN和CNN分别在自然语言处理和计算机视觉领域占主导地位,而Transformer架构在各种模态和领域中都表现出色。
Transformer中的先验知识
为了增强Transformer模型的性能,已经进行了大量尝试,将先验知识引入其中。最初的Transformer使用三角函数位置编码为每个Token提供位置信息。Swin Transformer提出了使用相对位置编码作为原始的绝对位置编码的替代方法。[Conditional positional encodings]指出卷积层中的零填充也可以为Transformer提供位置感知能力,而这种位置编码方法非常高效。
在许多研究中,ConvFFN已被用来进一步丰富Transformer中的位置信息。此外,在最近的Retentive Network中,引入了显式衰减,为模型提供了基于距离变化的先验知识。
Retentive Network
RetNet提出了用于序列建模的Retention机制。与传统的基于Transformer的模型相比,RetNet中提出的Retention使用显式衰减来建模一维距离的先验知识,这是一种重要区别。它包括三种计算范式,即并行、递归和分块递归。在Retention中,它使用一个衰减矩阵乘以一个权重矩阵,以根据距离先验控制每个Token看到其周围Token的比例。作者也尝试将这一思想扩展到二维空间。
方法
初步的Retentive Network
RetNet是一种强大的语言模型架构。本工作提出了用于序列建模的Retention机制。Retention引入了显式衰减到语言模型中,而Transformer没有这个特性。Retention首先以递归方式考虑序列建模问题。它可以写成如下的等式(式1):
 其中是的复共轭,包含了因果Masking和指数衰减,代表了一维序列中的相对距离,这带来了先验知识。基于Retention中的一维显式衰减,作者尝试将其扩展到二维,并将空间先验知识引入视觉模型中。
其中是的复共轭,包含了因果Masking和指数衰减,代表了一维序列中的相对距离,这带来了先验知识。基于Retention中的一维显式衰减,作者尝试将其扩展到二维,并将空间先验知识引入视觉模型中。
Retention自注意力
从单向到双向
由于语言任务的因果性质,RetNet中的Retention是单向的,意味着每个Token只能关注其前面的Token,而不能关注其后的Token。这不适用于没有因果属性的任务,例如图像识别任务。因此,作者首先将Retention扩展到二维,在这种情况下,对于每个Token,其输出变为如下的等式(3):
 其中BiRetention表示具有双向建模能力的Retention。
其中BiRetention表示具有双向建模能力的Retention。
从一维到二维
尽管Retention现在具有双向建模的能力,但这种建模能力仍然局限于一维水平,仍然不适用于二维图像。因此,作者进一步将一维Retention扩展到二维。
对于图像,每个Token在平面内具有唯一的二维坐标。对于第n个Token,作者使用来表示其二维坐标。基于每个Token的二维坐标,作者修改矩阵D中的每个元素,使其成为相应位置的Token对之间的曼哈顿距离,完成了从一维到二维衰减系数的转换。矩阵D转化为等式(5):
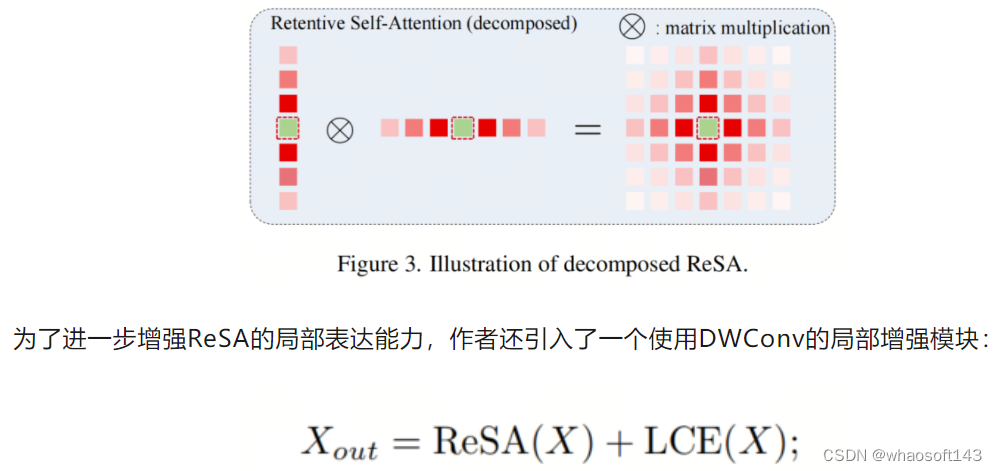
 基于这种ReSA的分解,每个Token的感受野形状如图3所示,与完整ReSA的感受野形状相同。
基于这种ReSA的分解,每个Token的感受野形状如图3所示,与完整ReSA的感受野形状相同。
 整体架构
整体架构
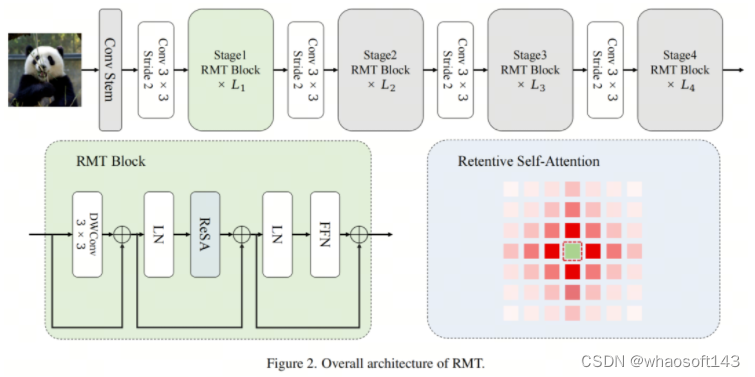 作者整个模型的架构如图2所示。与传统的Backbone网络类似,它分为4个阶段。前3个阶段使用了分解的ReSA,而最后一个阶段使用了原始的ReSA。与许多先前的Backbone网络一样,作者在模型中引入了CPE。
作者整个模型的架构如图2所示。与传统的Backbone网络类似,它分为4个阶段。前3个阶段使用了分解的ReSA,而最后一个阶段使用了原始的ReSA。与许多先前的Backbone网络一样,作者在模型中引入了CPE。
实验
图像分类
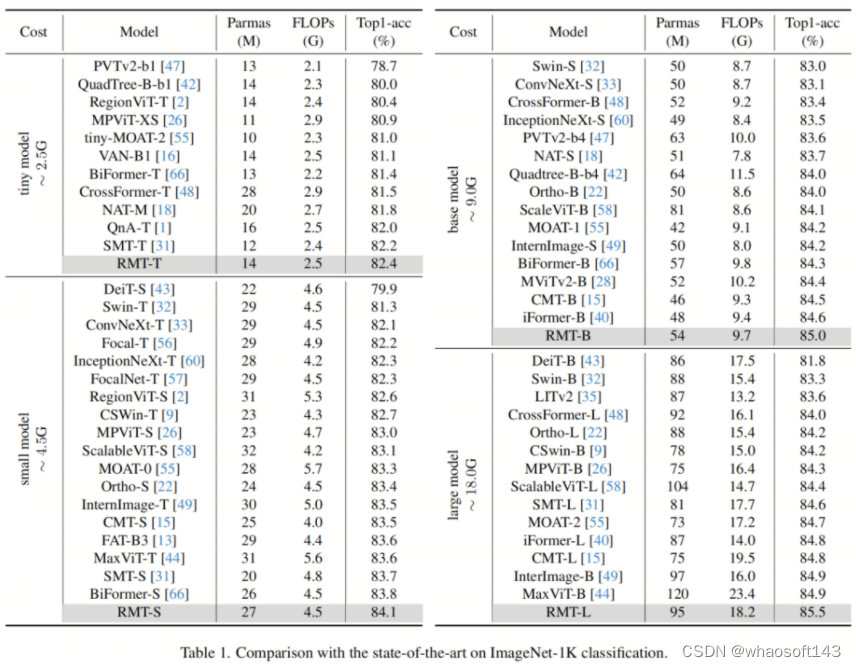
作者在表1中将RMT与许多最先进的模型进行了比较。表中的结果表明,RMT在所有设置下始终优于先前的模型。具体而言,RMT-S仅使用4.5 GFLOPs就实现了84.1%的Top1准确率。RMT-B也在类似的FLOPs下超越了iFormer 0.4%。
此外,作者的RMT-L模型在使用更少的FLOPs的情况下,将Top1准确率提高了0.6%,超过了MaxViT-B。作者的RMT-T模型也在性能上超越了许多轻量级模型。
目标检测和实例分割
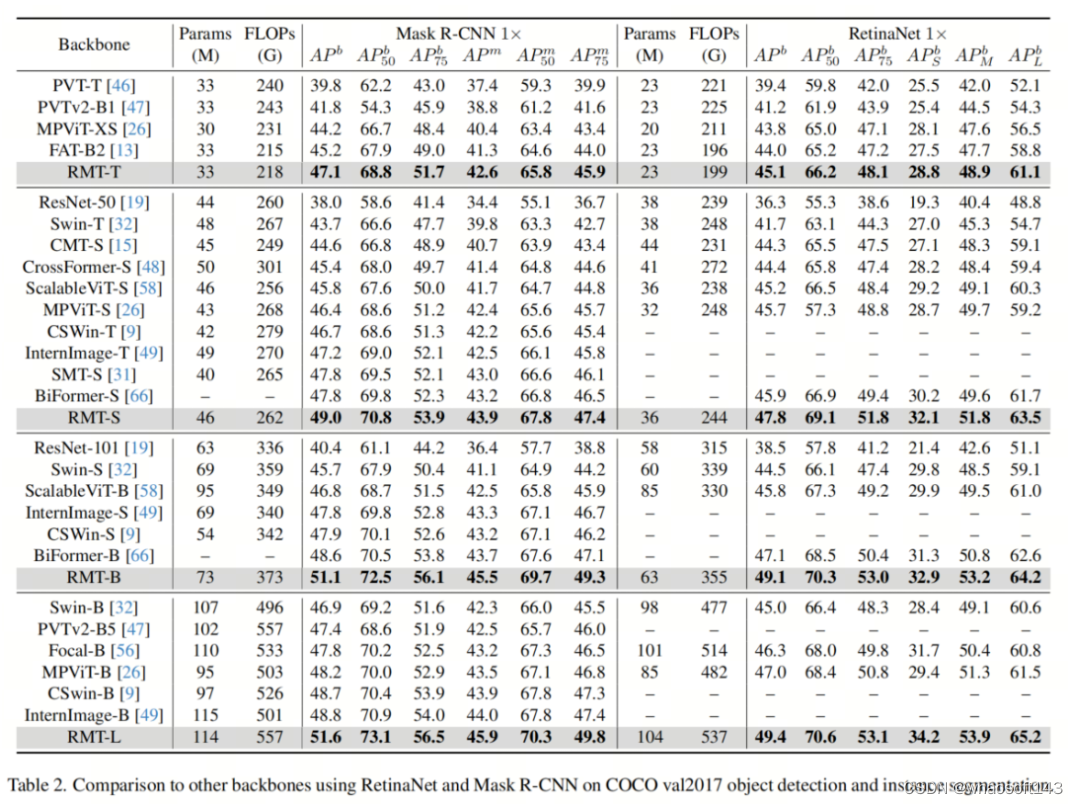
表2和表3显示了在RetinaNet和Mask R-CNN中的结果。结果表明,作者的RMT在所有比较中表现最好。对于RetinaNet框架,作者的RMT-T超越了FAT-B2 +1.1 AP,而S/B/L也优于其他方法。
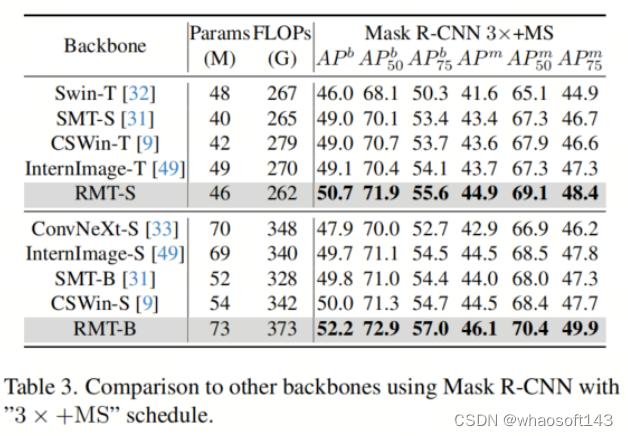
对于具有“1×”schedule的Mask R-CNN,RMT-L超越了最近的InternImage-B +1.8框AP和+1.9maskAP。对于“3× +MS”schedule,RMT-S超越了InternImage-T +1.6框AP和+1.2maskAP。所有以上结果表明,RMT明显优于其同类算法。
语义分割

语义分割的结果可以在表4和表5中找到。所有的FLOPs都是以512×2048的分辨率测量的。作者所有的模型在所有比较中都取得了最佳性能。 whaosoft aiot http://143ai.com

具体而言,作者的RMT-S在Semantic FPN的情况下超越了Shunted-S +1.2 mIoU。此外,作者的RMT-B在最近的InternImage-S +1.3 mIoU。所有以上结果证明了作者模型在密集预测方面的优越性。
消融研究
γ衰减。
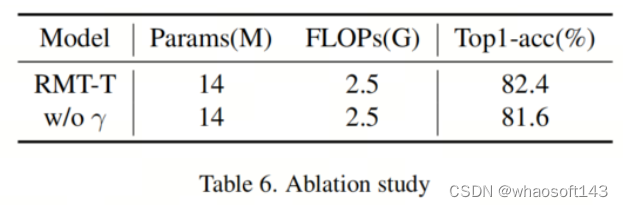
作者验证了明确衰减对模型的影响,如表6所示。明确衰减提高了模型的性能。
结论
作者提出了RMT,这是一个集成了Retentive网络和Vision Transformer的视觉Backbone网络。RMT引入了与距离相关的明确衰减,为视觉模型带来了空间先验知识。新机制称为Retentive自注意力(ReSA)。为了降低模型的复杂性,RMT还采用了将ReSA分解为两个轴的方法。大量实验证实了RMT的有效性,特别是在目标检测等下游任务中,RMT表现出明显的优势。

















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









