







使用场景
word判断单词是否拼写正确
网络爬虫(不爬相同页面)
垃圾邮件过滤算法
大量数据查询某个字符串是否存在
平衡二叉树
中序遍历有序,增删改查复杂度O(log2n)
10万条数据最多比较20次,换底公式计算log2n = log10n/log102
通过比较达到有序,每次排除一半达到快速索引的目的
散列表(hash+数组)
原理:根据key计算key在表中的位置的数据结构,是key和地址存储位置的映射关系hash(key) = addr
冲突程度描述:负载因子(0-1)
冲突处理:a.链表法:而且是通常头插法(局部性原理),极端情况下,使用红黑树来管理这个冲突链表,降O(n)为O(log2n)
b.开放寻址法(布隆过滤器使用)一个个的向下查找直到空或者平方勘探法
c.双重哈希法(.net使用)与数组size互为质

布隆过滤器
概率型数据结构,确定某个字符串一定不存在或者可能存在 不存储具体数据,误差可控,不支持删除操作
构成:位图+n个hash函数
原理:位图
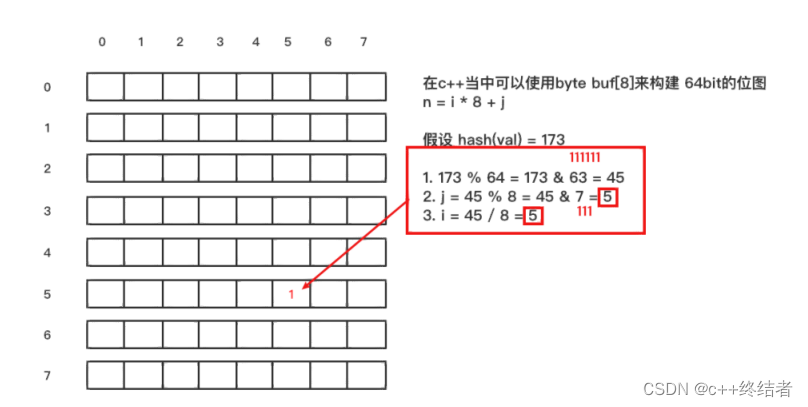
检索原理:见下图k个hash函数将字符串映射到k个点,置为1,然后检索时如果都为1那么可能存在,有不为1那么一定不存在,同时不能删除是因为可能将别人置为1的点也置为0导致删掉其他人的
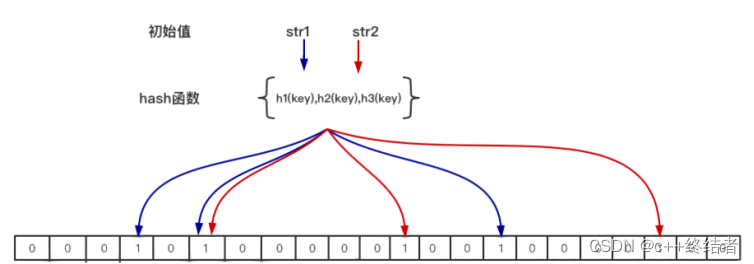
应用场景 判断某个key一定不存在的场景,同时允许判断误差
例子:缓存穿透的解决,热key限流
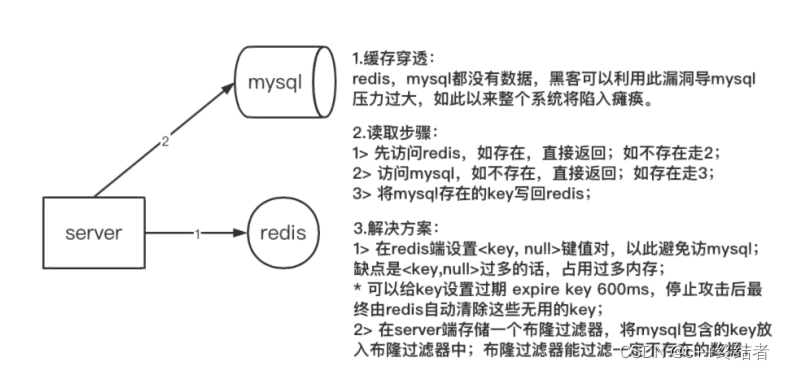
缓存穿透场景:攻击者大量访问不存在的数据,缓存和数据库都不存在这个数据,导致所有的请求全部压到mysql数据库
解决方案:server端加上一个布隆过滤器,将mysql的key全部存到里面
应用分析:hash函数个数的选择,分配多少的位图参照下列公式
n-- 预期布隆过滤器中元素的个数,如上图 只有str1和str2 两个元素 那么 n=2
p -- 假阳率,在0-1之间
m -- 位图所占空间
k -- hash函数的个数
公式如下:
n = ceil(m / (-k / log(1 - exp(log(p) / k))))
p = pow(1 - exp(-k / (m / n)), k)
m = ceil((n * log(p)) / log(1 / pow(2, log(2))));
k = round((m / n) * log(2));
hash函数选择
计算速度快,强随机分布,典型murmurhash2,sipgash(redis6.0当中使用,rust等大度数语言使用)
siphash主要解决字符串接近的强随机分布性
实际使用布隆过滤器
确定n和p,算出m和k(直接到相关的网站计算即可)
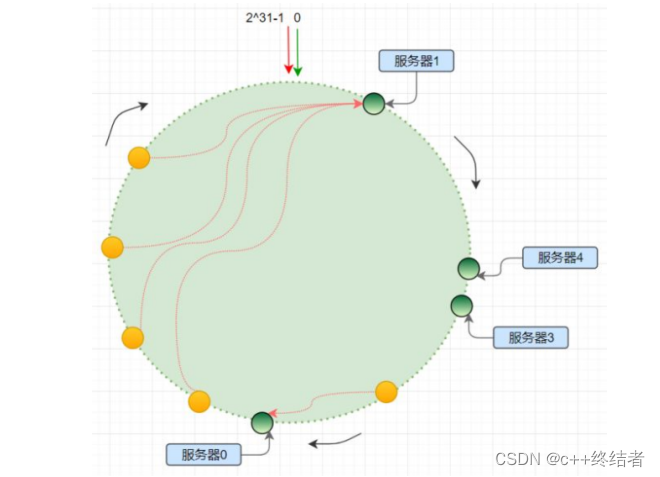
分布式一致hash
解决分布式问题
算法思路:将 2^32的空间映射成一个环
hash(meachine ip + port)->addr(机器hash值)
hash(key)->addr(存储键hash值),得到这个存储键hash值后一个个的查找,第一个就是其存储的位置
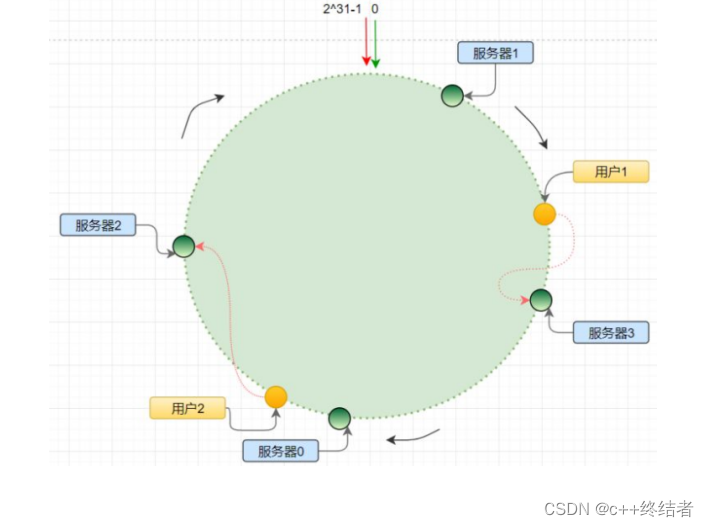
由于hash函数并不保证均匀性,于是加上虚拟节点使得尽量保持hash的均匀性















 1196
1196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









