







上面那篇文章,简单的总结了李航老师《统计机器学习》上面的SVM的问题。其中软间隔的SVM主要指的是对那些线性不可分的样本集构建SVM分类的问题,允许一定的误分类,所以优化问题引入了参数C;作为惩罚因子,C越大惩罚越大允许的错误越小。
但是直接使用0/1损失函数的话其非凸、非连续,数学性质不好优化起来比较复杂,因此需要使用其他的数学性能较好的函数进行替换,替代损失函数一般有较好的数学性质。常用的三种替代函数:
1、合页(hinge)损失函数:
l(z) = max(0,1-z);2、指数损失函数:
l(z) = exp(-z);3、对数损失函数:
l(z) = log(1+exp(-z));一般的软间隔SVM采用的是hinge损失函数进行替代,可以得到常见的软件的SVM的优化目标函数。如果采用的是对率损失函数进行替代那么就和逻辑回归的优化目标几乎相同,这就得到了软间隔SVM与逻辑回归的数学上的联系,因此一般来说SVM的性能和逻辑回归的性能差不多。

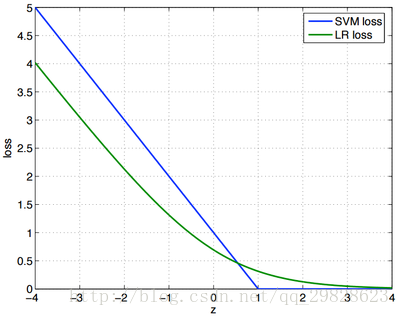
软间隔SVM与逻辑回归的区别
最本质的区别:
这两个损失函数的目的都是增加对分类影响较大的数据点的权重,减少与分类关系较小的数据点的权重。
SVM的处理方法是只考虑 support vectors,也就是和分类最相关的少数点,去学习分类器。
而逻辑回归通过非线性映射,大大减小了离分类平面较远的点的权重,相对提升了与分类最相关的数据点的权重,两者的根本目的都是一样的。
1、逻辑回归通过输出预测概率后根据阈值进行判断类别属于回归问题,SVM则直接输出分割超平面,进行分类,属于分类问题。
(如果需要SVM输出概率值则需要进行特殊处理,可以根据距离的大小进行归一化概率输出。)
2、逻辑回归可以使用多阈值然后进行多分类,SVM则需要进行推广。
3、SVM在训练过程只需要支持向量的,依赖的训练样本数较小,而逻辑回归则是需要全部的训练样本数据,在训练时开销更大。
4,处理的数据规模不同。LR一般用来处理大规模的学习问题。如十亿级别的样本,亿级别的特征
引用:
1、作者:Charles Xiao,链接:https://www.zhihu.com/question/24904422/answer/92164679
2、http://www.cnblogs.com/daguankele/p/6652597.html















 2279
2279

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









