








Abstract
个性化推荐为用户提供了一个无处不在的渠道来发现适合他们兴趣的信息。然而,传统的推荐模型主要依赖于唯一的ID和分类特征来进行用户与项目的匹配,可能会忽视文本、图像、音频和视频等多种形式的原始项目内容的细微差别。多模式数据的利用率不足对推荐系统构成了限制,特别是在新闻、音乐和短视频平台等多媒体服务中。近年来,大型多模态模型的发展为内容感知推荐系统的开发提供了新的机遇和挑战。本调查旨在全面探索多模式预训练,适应和生成技术的最新进展和未来轨迹,以及它们在增强推荐系统中的应用。此外,我们还讨论了当前开放的挑战和机遇,为未来的研究在这个充满活力的领域。我们相信,这项调查,以及策划的资源1,将提供宝贵的见解,以激发在这个不断变化的景观进一步推进。
目录
1 Introduction
推荐系统已经被广泛应用于各种在线应用中,包括电子商务网站、广告系统、流媒体服务和社交媒体平台,以向用户递送个性化推荐。他们的主要目标是增强用户体验,提高用户参与度,并促进发现针对个人兴趣的项目。然而,传统的推荐模型主要依赖于唯一ID(例如,用户/项目ID)和分类特征(例如,标签)进行用户项匹配[162],可能会忽略跨文本、图像、音频和视频等多种形式的原始项内容的细微差别[149]。多模态数据的这种未充分利用对推荐系统造成了限制,特别是在新闻,音乐和短视频平台等多媒体服务中。
为了解决这个问题,研究人员已经广泛地研究了多通道推荐技术超过十年,导致了大量的研究工作,探索多通道项目功能集成到推荐模型。对于全面的审查,感兴趣的读者可以参考最近的调查[14,73,84,157]。这些调查主要深入研究了推荐模型的多模态特征提取[84]、特征表示[14]、特征交互[73]、特征对齐[14]、特征增强[73]和多模态融合[157]等技术。然而,这些方法中的大多数依赖于提取的多模态特征嵌入,使得多模态预训练和生成的其他方面相对未被探索。如今,预训练的大型模型在自然语言处理(NLP),计算机视觉(CV)和多模态系统(MM)领域中非常流行。GPT [7]和Llama [116]系列等语言模型的出现开创了理解和生成语言能力的新时代,而CV领域则见证了ViT [21]和DINOv 2 [90]等模型的突破。利用这些在单模态领域的成功,多模态社区专注于在不同模态之间对齐内容,例如CLIP [92],CLAP [24]和BLIP-2 [54]。值得注意的是,最近引入的开创性技术,如ChatGPT [88],SD [99]和索拉[80],将预训练的大型模型的生成能力进一步提升到前所未有的水平。这些最新的进展,在预先训练的大型多模态模型提供了新的机遇和挑战,在开发内容感知推荐系统。
在这项调查中,我们的目标是从一个新的角度全面概述多模式推荐技术,重点是利用预训练的多模式模型。我们探讨最新的进展和未来的轨迹,多模式预训练,适应和生成技术,沿着他们的应用程序的推荐系统。与以前的工作不同,我们的调查利用了多模态语言模型[54,89],提示和适配器调整[60,159]以及稳定扩散[99]等生成技术的最新进展。此外,我们深入研究了在将预训练的多模态模型应用于推荐任务方面的最新实践发展和剩余的开放性挑战。
更具体地说,第2节介绍了多模态预训练的任务,强调使用特定领域的数据来增强域内多模态预训练的方法。第3节研究多模态适应推荐,阐明如何预训练的多模态模型可以适应下游的推荐任务,通过技术,如表示转移,模型微调,适配器调整,并提示调整。第4节深入研究了用于推荐的多模态生成的新兴主题,重点关注AI生成内容(AIGC)技术在推荐环境中的应用。在第5节中,我们概述了一系列需要多模式推荐的常见应用,然后在第6节中讨论了未来研究的开放挑战和机遇。最后,我们在第7节中总结了调查。我们希望这项调查,沿着策划的资源,将激发进一步的研究工作,以推进这一不断变化的景观。
2 MULTIMODAL PRETRAINING FOR RECOMMENDATION
与直接在特定领域数据上进行监督学习相比,自监督预训练从大规模未标记语料库中学习,然后将预训练模型适应下游任务。这种方法允许在预训练数据中获取丰富的外部知识,从而导致其有效性的广泛认可。在本节中,我们将首先回顾主要的预训练范例,然后介绍它们如何在推荐领域中使用。图1a展示了多模式预训练技术的概述。
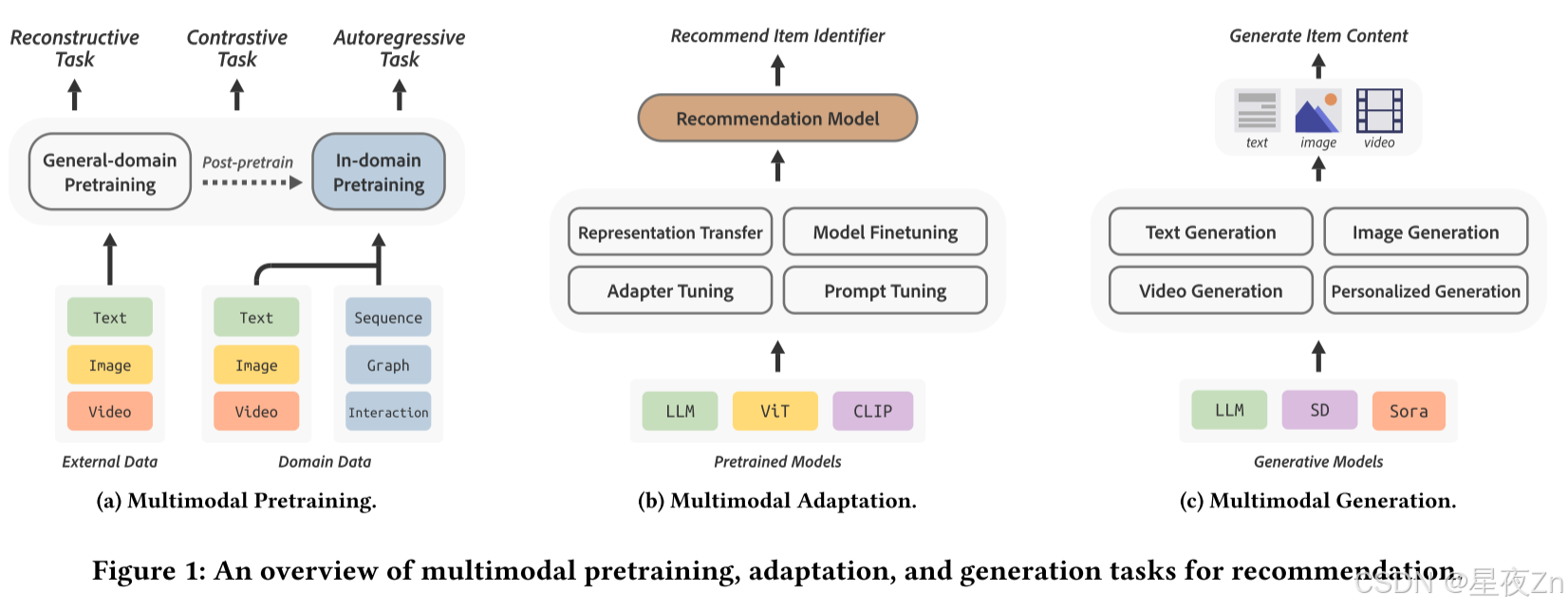
2.1 Self-supervised Pretraining Paradigms
我们根据预训练任务将自我监督预训练范式大致分为三种类型。
Reconstructive Paradigm.
这种预训练范式旨在教导模型在信息瓶颈框架内重建原始输入。示例包括用于部分重建的掩模预测方法和用于完全重建的自动编码器方法。掩码预测方法最初是在BERT [18]中引入的,其中输入令牌被随机掩码,促使模型学习根据周围的上下文来预测它们。相反,自动编码器方法(例如,AE [5],VAE [50])将输入数据编码到一个简洁的潜在空间中,然后学习从这个潜在表示中完全恢复输入。这些方法在各种领域的自我监督预训练中得到了广泛的应用,例如文本[52],视觉[21,36,119],音频[150]和多模态数据[97,99]。在他们的成功之后,研究人员将重构性预训练范式应用于推荐任务。例如,Bert 4 Rec [112]中的掩码项预测,Recformer [55]中的掩码标记预测,基于自动编码器的项标记化[72,96]和PMGT [79]中的掩码节点特征重建等方法已经出现。尽管取得了重大进展,仅仅依靠这种重构范式可能无法有效地从用户-项目交互中捕获接近度信息。因此,在实践中,这些方法通常与对比学习范式相补充。
Contrastive Paradigm.
这种预训练侧重于成对相似性,通过最大化负对之间的距离并最小化表示空间内的正对来区分相似和不相似的数据样本。它已被证明是有效的,在提高跨不同领域的代表性的质量。例如SimCSE [28]用于文本,Simplified [11]用于图像,CLMR [110]用于音乐,CLIP [92]用于多模态表示,突出了其通用性和适用性。鉴于其捕捉成对相似性的能力,这种范式在调整用户-项目偏好方面有着广泛的用途。像MGCL [69],MMSSL [126],MMCPR [82],MSM 4SR [152]和MISSRec [121]这样的应用程序支持利用对比学习来增强推荐系统中的多模式预训练。
Autoregressive Paradigm.
这种范式最近取得了显著的成功,特别是随着大型语言模型(LLM)的兴起,如GPT家族[7,89,93,94]。它以自回归的方式逐个令牌地生成序列数据,其中每个令牌都是基于先前的观察结果进行预测的。换句话说,这种方法是在一个单向的,从左到右的生成框架,这是不同的重构范式,采用双向上下文来预测掩码令牌。它也在CV领域[98]和多模式领域[151]中得到了快速采用。在推荐系统领域,用户行为序列自然适合顺序处理,促进了许多自回归顺序推荐模型的发展,如SASRec [48]。最近的研究,如P5 [31]和VIP5 [32],已经探索了LLM或预训练的多模态模型到推荐任务中的整合。与此同时,生成式推荐(将推荐框架为自回归序列生成)已成为一个新兴的研究领域[96,123,125]。
2.2 Content-aware Pretraining for Recommendation
内容感知推荐系统努力将项目的语义内容,以提高推荐的准确性。因此,许多研究探索了内容增强的推荐系统的预训练方法。在本节中,我们根据预训练所采用的方式对现有研究进行分类,并讨论它们在一般情况下和推荐系统中的应用。
Text-based Pretraining.
文本是推荐系统中最普遍的内容形式之一,应用于新闻推荐和基于评论的推荐等环境。在自然语言处理(NLP)领域,已经开发了BERT [18]和T5 [95]等预训练语言模型来捕获文本的上下文感知表示。这些模型通常遵循为特定任务量身定制的预训练-微调范式。最近,ChatGPT [88]和LLaMa [115]等大型语言模型(LLM)在语言相关任务中表现出了显著的能力,利用了提示和上下文学习等技术。在他们成功的基础上,文本增强的预训练在推荐系统中获得了牵引力。值得注意的例子包括用于新闻推荐的MINER [56],用于顺序推荐的Recformer [55],用于跨域推荐的UniSRec [38]和用于基于LLM的交互式推荐的P5 [31]。
Audio-based Pretraining.
音乐推荐是一个重要的场景,它严重依赖于音频模态来捕获内容语义。类似于NLP域,各种预训练技术已被用于增强音频表示,包括Wav 2 Vec [101],MusicBert [150],MART [145]和MERT [61]。在音乐推荐的背景下,研究人员探索利用这些音频预训练方法,利用用户-项目交互作为监督信号来微调音乐表示。例如,Chen等人[10]提出通过对比学习技术从音轨数据和用户兴趣中学习用户音频嵌入。此外,Huang et al.[43]将成对文本和音频特征集成到卷积模型中,以联合学习相似性度量中的内容嵌入。感兴趣的读者可以在综合评论论文中找到更多的例子[15]。
Vision-based Pretraining.
图像和视频构成了广告、电影和视频等多媒体推荐场景中的主要视觉数据。在CV领域,基于视觉的预训练的发展已经从基于CNN的架构(如ResNet [37])过渡到Transformer架构(如ViT [21]和DINOv 2 [90]),从而能够提取通用的视觉特征。这些预先训练的模型具有显著先进的视觉感知推荐系统。像刘等研究人员。[68]和Chen等人[12]利用具有类别先验的预训练CNN编码器来提取工业推荐任务的图像特征,同时微调图像编码器和推荐模型。类似地,Wang等人[121]和Wei et al.[125]利用预先训练的Transformer编码器,如ViT [92],对图像和用户行为序列进行编码。视觉基础模型继续快速发展,在推荐任务中有前途的未来应用。展望未来,人们对探索使用新的预训练模型进行推荐任务的兴趣越来越大。例如,利用像Video-LLaVA [62]这样的预训练视频转换器仍然是构建视频推荐模型的一个未探索的领域。
Multimodal Pretraining.
在当前的文献中,大多数研究倾向于对内容的主要形式进行建模,例如新闻推荐的文本[56],音乐推荐的音频[10]和电子商务推荐的图像[68]。然而,多媒体内容本质上涉及多种形式。例如,新闻文章通常包括标题、描述和伴随的图像。类似地,视频推荐涉及处理视觉帧、音频信号和字幕。
与单模态技术不同,多模态模型必须通过跨模态对齐和融合等技术捕获多模态数据源的共性和互补信息。近年来,多模态预训练得到了快速发展,导致了过多的预训练模型,包括单流模型(例如,VL-BERT [111])、双流模型(例如,CLIP [92])和混合模型(例如,[106][147][149][149]][149]最近的研究也集中在实现多模态数据的统一表示,例如ImageBind [33],MetaTransformer [154]和UnifiedIO-2 [83]等模型。另一个新兴趋势是将多模态编码器与大型语言模型集成,从而产生多模态大型语言模型,如BLIP-2 [54],Flamingo [1]和Llava [67]。这些进步为构建现代多模式推荐系统提供了有前途的机会。
这方面的初步努力包括MISSRec [121],Rec-GPT 4V [77],MMSSL [126],MSM 4SR [152]和AlignRec [81]等模型。然而,目前的研究主要集中在利用离线预训练的多模式编码器,并将它们与基于序列或基于图形的预训练技术相结合,以处理推荐数据。在如何专门预训练为推荐任务量身定制的特定于领域的多模态模型方面仍然存在差距。在电子商务领域已经做出了开创性的努力,如M5 Product [20],K3 M [165],ECLIP [47]和CommerceMM [148]等模型所证明的那样。未来的研究有望在这一方向上进一步探索和推进。
3 MULTIMODAL ADAPTION FOR RECOMMENDATION
虽然大多数现有的预训练模型都是在一般数据语料库上训练的,但将它们用于推荐系统需要战略方法来充分利用它们所学到的知识。本节总结了四种主要的适配技术:表示转移、模型微调、适配器调优和即时调优。每种技术都提供了一种独特的方法来利用预训练模型的好处。图1b展示了多模态自适应技术的概述。
3.1 Representation Transfer
表示迁移是将预先训练好的知识迁移到推荐模型中最常用的自适应技术之一。具体来说,项目表示是从冻结的预训练模型中提取的,并作为ID嵌入的附加特征。这些表示为推荐系统提供了补充的一般信息,解决了冷启动问题,其中新的或不经常交互的项目可能具有从有限的交互中获得的不充分的ID嵌入[74]。基于表示转移的方法已经被广泛研究,并在各个领域被证明是有效的,例如,基于文本推荐[132]、基于视觉推荐[4,102]、多模式推荐[22,41,64,128,140]。特别是对于多模态场景,已经针对融合来自多个模态的表示进行了大量努力。这包括早期融合[41,75,79,161]、中期融合[22,134,140]和晚期融合[114,130]等技术。另一个研究重点涉及使用内容ID对齐[78,129],项目到项目匹配[44],用户序列建模[38]和图形神经网络[131]等方法在用户行为空间内对齐多模态表示。
然而,由于语义空间和行为空间之间的不对准,直接和有效的表示转移可能会遇到显著的域泛化差距,这可能不会一致地导致实际中的性能改进。模型微调提供了一个直接的解决方案来解决这个问题。此外,正如KDSR [41]所指出的那样,存在遗忘表征中的模态特征的风险,导致它们与那些没有包含这些特征的训练相似。一种可行的方法涉及集成显式约束[41],而另一种潜在的解决方案引入语义标记化技术[46,72,96,107],将项目内容表示转换为离散标记。
3.2 Model Finetuning
模型微调是指在特定于任务的数据上进一步训练预训练模型的过程。它的目标是调整模型参数,以有效地捕捉特定领域的细微差别,从而提高其在特定下游任务上的性能。这种预训练-微调范例已在各种实际应用中证明是成功的。具体来说,微调可以涉及将预训练模型的语义空间与推荐模型的行为空间对齐。根据预训练模型的应用,它们可以提取项目表示[56,141],用户表示[113]或两者[55,74,121]。此外,根据下游任务的类型,目前的研究可以分为基于表征的匹配任务[56,121,133]和基于评分的排名任务[68,141,153]。
然而,使用推荐数据对预训练模型进行端到端微调面临着与训练效率相关的挑战。推荐任务通常需要每天处理数百万甚至数十亿个样本。完全微调预训练模型会大大增加训练开销,这对大规模推荐系统造成了实际限制,特别是考虑到大型语言和多模态模型的规模[54,115]。此外,对大量数据进行微调很容易导致灾难性遗忘的问题,即先前学习的知识在持续训练中迅速退化。
3.3 Adapter Tuning
为了减少预训练的大型模型的训练开销,已经开发了参数有效的微调(PEFT)方法。一种突出的方法是通过参数高效的适配器,如LoRA [40],它将紧凑的,特定于任务的模块直接集成到预训练的模型中。该策略有效地减少了微调所需的参数数量,并促进了快速模型自适应。PEFT技术因其在各个领域的有效性而得到广泛认可,在推荐系统中获得了显著的吸引力[27,32,38,71,135]。例如,ONCE框架[71]利用预先训练的Llama模型[115],LoRA作为项目编码器来增强内容感知推荐。类似地,UniSRec [38]使用基于MOE的适配器和BERT模型来改进跨不同领域的项目的语义表示。在多模式推荐领域,TransRec [27]和VIP5 [32]引入了分层适配器。M3SRec使用模态特定的莫伊适配器[6],而EM3在微调期间使用多模态融合适配器[16]。尽管如此,持续的挑战在于设计有效平衡有效性和效率的适配器,这仍然是一个活跃的研究领域。
3.4 Prompt Tuning
随着大型语言模型的出现,提示已成为利用其能力来生成所需输出或执行特定任务的关键技术[70]。提示调优不是使用手工制作的提示,而是旨在从特定于任务的数据中学习可适应任务的提示,同时保持模型参数冻结。因此,即时调优可以避免灾难性的遗忘,并实现仅使用提示令牌作为可调参数的快速自适应。根据提示是否在离散令牌空间中优化,它们可以进一步分类为硬提示调优,如AutoPrompt [105]和软提示调优,如Prefix-Tuning [60]。即时调整在视觉学习[159]和多模态学习[23,49]中取得了成功,提高了模型性能。
对于多模式推荐任务,即时调整已成为一种适应预训练模型的新技术。最近的研究,如RecPrompt [66],ProLLM4Rec [138],ProLT4NR [155]和PBNR [59],采用提示方法为新闻推荐任务定制大型语言模型(LLM)。此外,DeepMP [125],VIP5 [32]和AdmittMM [127]采用即时调整来集成和调整多模态内容知识以增强推荐。尽管最近取得了进展,但这一研究领域仍然没有得到充分探索。一个有趣的方向是个性化的多模态提示技术的发展,以推进多模态推荐系统。
4 MULTIMODAL GENERATION FOR RECOMMENDATION
随着生成模型的最新进展,AI生成的内容(AIGC)在各种应用程序中获得了极大的普及。在本节中,我们将探索在推荐系统中使用AIGC技术的潜在研究途径。图1c呈现了多模态生成技术的概述。
4.1 Text Generation
在强大的大型语言模型(LLM)的支持下,文本生成已经成为一种成熟的能力,现在正在推荐领域的各种任务中应用[86]。
- 关键词生成:关键词标记在广告定位和推荐的内容理解中起着关键作用。以前的技术主要依赖于从文本内容中显式提取关键字,可能会遗漏文本中不存在的重要关键字。因此,关键字生成技术已被广泛应用于增强关键字标记过程[53,108]。
- 新闻标题生成:对个性化和引人入胜的新闻内容的需求推动了新闻标题生成的探索。传统上,标题生成被框定为文本摘要任务,将输入文本或多模态内容压缩为标题[19,51]。然而,典型的新闻标题可能对特定用户缺乏吸引力或相关性,从而需要个性化的方法。因此,个性化标题生成已经成为一个引人注目的研究课题,重点是生成针对个人用户的阅读偏好和可用新闻内容的标题[35,100]。
- 营销文案生成:营销文案是指用于推广产品和激励消费者购买的文本。它在吸引用户兴趣和增强参与度方面发挥着至关重要的作用。最近的努力集中在基于LLM的自动营销文案[85,158]
- 解释生成:在交互式场景中,对可解释建议的需求正在显著增长。这涉及生成自然语言解释,以证明向各个用户推荐项目的合理性,从而增强用户对系统的理解和信任[57,156]。
- 对话生成:对话生成[142]在会话式推荐系统中是必不可少的,包括描述推荐项目[26]的响应的生成。此外,它需要生成问题,以引导用户进行更多轮的对话和互动[124]。
虽然这些任务受益于强大的LLM,但在推荐文本生成中存在两个关键挑战:1)可控生成:工业应用需要对生成的文本进行精确控制,以确保产品描述的正确性,使用独特的销售主张,或遵循特定的写作风格[160]。2)知识增强的一代:现有的LLM通常缺乏对特定领域知识的明确认识,例如产品实体,类别和卖点。最近的研究集中在整合特定领域的知识库以取得更令人满意的结果[117,139]。
4.2 Image and Video Generation
随着扩散模型的流行,文本到图像的生成已经取得了显著的成功(例如,SD [99])。在本节中,我们将深入研究它们在电子商务和广告中的潜在应用。与自然图像生成不同,生成产品图像和广告横幅涉及处理复杂的布局,包括产品,徽标和文本描述等各种元素。因此,独特的挑战出现在设计一个连贯的布局,并有效地整合文本与适当的字体和颜色,以创建视觉吸引力的海报。
具体而言,Inoue等人[45]提出了LayoutDM,这是一种设计用于有效处理结构化布局数据和促进离散扩散过程的模型。Hsu等人[39]通过在给定的画布上排列预定义的空间元素来实现内容感知布局生成(即PosterLayout)。Lin等人[63]开发了AutoPoster,这是一个用于生成广告海报的高度自动化和内容感知系统。与此同时,一些研究也探索了海报生成的文本设计。例如,Gao等人[29]介绍了TextPainter,这是一种利用上下文视觉信息和相应文本语义生成文本图像的新颖多模态方法。Tuo等人[118]提出了一种基于扩散的多语言可视文本生成和编辑模型AnyText,该模型解决了如何在图像中呈现准确且连贯的文本的问题。
最近,视频生成取得了重大进展。索拉[80]作为一种开创性的技术出现,展示了为产品生成广告视频的巨大潜力。在这种情况下,Gong等人[34]介绍了AtomoVideo,这是一种高保真的图像到视频生成解决方案,可以有效地将产品图像转换为用于广告目的的宣传视频。此外,Liu等人[65]设计了一个系统,能够从给定的一组视觉材料自动生成视觉故事情节,为电子商务量身定制引人注目的宣传视频。此外,Wang等人[122]开发了一种集成方法,将文本到图像模型,视频运动生成器,参考图像嵌入模块和帧插值模块合并到端到端视频生成管道中,这对微视频推荐平台很有价值。我们相信,这一领域正在迅速扩大,使基于AIGC的推荐和广告应用的发展成为可能。
4.3 Personalized Generation
随着AIGC的兴起,有一个显着的转向个性化生成,旨在提高生成内容的定制和个性化。这种趋势在推荐场景中具有特别的意义,在推荐场景中,个性化内容可以更好地迎合用户的兴趣。开创性的工作已经在各个领域进行,包括个性化新闻标题生成[2,3,8,100],电子商务中的个性化产品描述生成[17],个性化答案生成[17],具有身份保护的个性化图像生成[21]和个性化多模态生成[104]。将推荐系统与个性化生成技术相结合,有望开发出下一代推荐系统。
5 APPLICATIONS
在本节中,我们总结了一些需要多模态推荐技术的常见应用领域。
- 电子商务推荐。电子商务是推荐系统研究中最广泛的应用领域之一,其目的是帮助用户发现他们可能购买的商品。电子商务中大量的多模态数据,包括产品名称、描述、图像和评论,对将不同模态与用户交互数据集成以提高推荐质量提出了挑战。为了应对这一挑战,已经进行了大量的研究工作。值得注意的例子包括阿里巴巴[30,58,141]、JD.com [68,136]和Pinterest [4]的作品。
- 广告推荐。在线广告用作许多web应用的主要收入来源。广告创意在这一生态系统中扮演着关键角色,涵盖了图像、标题和视频等多种格式。美学创意有可能吸引潜在用户,并提高产品的点击率(CTR)[9]。还迫切需要更好地理解广告创意,以有效地使广告与用户的兴趣相一致[143,144]。
- 新闻推荐。个性化新闻推荐是帮助用户发现感兴趣新闻的关键技术。为了提高推荐的准确性和多样性,推荐系统必须理解新闻内容,并从用户的阅读历史中提取语义信息。这通常涉及到学习新闻标题、摘要、正文和封面图片的语义表示。最近的研究集中在对来自多个模态的特征进行建模,如MM-Rec [134]和IMRec [140]所示。
- 视频推荐。随着微视频平台的迅速普及,视频推荐在社会上引起了极大的关注。视频封装了多种形式,包括标题、缩略图、帧、音轨、抄本等。当前的研究工作集中在微视频推荐模型中集成和适配多模态信息。[131,第146页]。值得注意的是,Ni等人[87]最近引入了一个综合的微视频推荐数据集,该数据集富含丰富的多模态辅助信息,以促进该领域的进一步研究。
- 音乐推荐。音乐流服务领域代表了另一个需要多模态推荐技术的重要领域。在这个领域中,涉及到多种多样的多模态数据,包括音乐音频、乐谱、歌词、标签和评论。利用这些不同类型的音乐数据已经证明在制作旨在吸引用户的更个性化的推荐方面是有效的;在[10,43]中可以找到显著的例子。此外,Shen等人[103]提出,整合来自用户社交媒体的多模态信息可以洞察他们的个性、情绪和心理健康,从而提高音乐推荐的准确性。
- 时尚推荐。随着时尚产品的视觉和审美特性,时尚推荐已经成为一个独特的垂直领域。与传统的推荐系统不同,时尚推荐不仅推荐单个商品,还推荐与多个商品互补的服装。多模态理解能力在这一领域发挥着关键作用,包括从图像中定位时尚单品、识别其属性以及计算多个单品的兼容性评分等任务[13,109]。此外,开创性的工作[164]已经开发了文本到图像的扩散模型,允许用户虚拟地试穿衣服。这些技术有望增强时尚推荐的个性化,将用户体验提升到一个新的水平。
- LBS推荐。基于位置的服务(LBS)已经变得无处不在,提供了广泛的服务,包括出租车旅行、食物递送和餐馆推荐。在这些上下文中,用户可以共享他们的兴趣点(POI)签到、照片、意见和评论,其中包含丰富的多模态时空数据阵列。集成该多模态信息并理解位置之间的时空相关性使得能够对用户偏好进行更准确的建模。值得注意的例子可以在[76,91]中找到。
6 CHALLENGES AND OPPORTUNITIES
在本节中,我们将讨论未来研究面临的持续挑战和新兴机遇。
- 多模态信息融合。多模态融合已经在研究中被广泛探索。在推荐系统中,目前的研究主要集中在融合和适应项目的多模态特征嵌入到推荐模型[157]。然而,用于推荐的多模态信息本质上采用分层结构,从用户行为序列到单个项目,每个项目都包括多个模态,并进一步细分为语义令牌和对象。此外,来自不同模式和区域的信息的影响在不同用户之间可能有很大差异。因此,挑战在于以分层和个性化的方式有效地融合多模态信息以优化推荐。
- 多模式多域推荐。多模态信息为项目内容提供了丰富的语义见解。尽管对多模式推荐和跨域推荐进行了大量研究,但有效利用多模式信息来弥合跨域的信息差距仍然是一个公开的挑战[113]。例如,基于用户的阅读习惯推荐音乐需要跨模态(音频与文本)和域(音乐与书籍)的语义对齐。
- Multimodal Foundation Models for Recommendation.虽然大型语言模型和大型多模态模型已经成为NLP和CV领域的基础模型,但将这种探索扩展到推荐领域存在着令人信服的机会。一个理想的推荐基础模型应该表现出强大的上下文学习能力,同时保持跨不同任务和领域的通用性[42]。潜在的探索途径包括使现有的多模态LLM适应推荐任务(例如,[32])或者使用大规模多模态多域推荐数据从头开始进行多模态生成模型的预训练。
- AIGC推荐。AIGC的集成代表了推荐系统的一个显著进步,为显著增强用户个性化、参与度和整体体验提供了机会。这包括个性化的新闻标题,定制的广告创意,以及跨不同推荐上下文的解释性内容。这个领域正在迅速扩大,主要挑战在于实现对内容和用户的全面理解,促进可控生成,并确保准确的格式以优化用户体验。此外,必须解决使用AIGC所产生的潜在道德和隐私问题。
- Multimodal Recommendation Agent。基于LLM的代理[120]通过广泛的知识和强大的推理能力,在自动化任务方面表现出了卓越的能力。这些代理的整合在推荐领域引入了创新前景,特别是在会话推荐中[25]。这需要在任务完成过程中直接吸引用户,从而增强用户体验和推荐系统的有效性。作为一个具体的例子,整合对话和虚拟试穿生成[164]功能可能会为时尚推荐提供新的机会。
- 训练和推理的效率。推荐任务通常具有严格的延迟要求以满足实时服务需求。因此,在实践中应用多模态预训练和生成技术时,确保训练和推理效率变得至关重要。有一个高需求的发展ofeffefficient战略,以利用多式联运模式的能力。这方面的先驱努力包括通过合并项目集来加速训练,以避免冗余编码操作[137],并通过缓存项目和用户表示来提高推理速度[12,74]。
7 Conclusion
多模态推荐是一个非常有前途的领域,近年来受到了极大的关注,这得益于多模态机器学习和推荐系统社区的进步。大型多通道模型的出现改变了多通道推荐的格局,赋予其增强的理解和内容生成能力。本文对当前的多模态推荐框架进行了系统的概述,重点讨论了多模态预训练、自适应和生成等关键方面。此外,我们深入研究了它的应用,挑战和未来前景。我们的目的是提供这个调查作为一个足智多谋的指南,以帮助在该领域的后续研究。
以上内容全部使用机器翻译,如果存在错误,请在评论区留言。欢迎一起学习交流!

















 1529
1529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









