







机器学习方法之范数规则
范数规则 实则就是将模型的一些先验知识融入到模型的学习中,强行地让学习到的模型具有某些特征,如低秩、稀疏等等,因此可用于防止过拟合现象的出现。
从贝叶斯的角度来看,范数规则项实则对应模型的先验概率;另外,也可看成是结构风险最小化策略的实现,即在经验风险上加一个正则化项或者是惩罚项。
一般来说,监督学习即是最小化下面的目标函数:
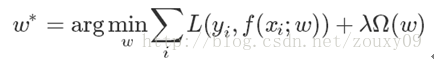
其中,第一项衡量模型(分类/回归)对第i个样本的预测值
f
(
x
i
;
ω
)
f(x_i;\omega)
f(xi;ω) 和真实的值
y
i
y_i
yi 之间的误差,最小化误差(第一项)从而保证我们的模型是在拟合训练样本;第二项则是对参数
ω
\omega
ω 的约束,防止过拟合。
L0范数和L1范数
L0范数是指向量中非0元素的个数,将L0范数作为正则项实则是希望向量中的非0元素个数减少,即变得更为稀疏。但是,L0范数由于在0处不可微,难以优化求解(NP-Hard问题),因此常被L1范数代替。
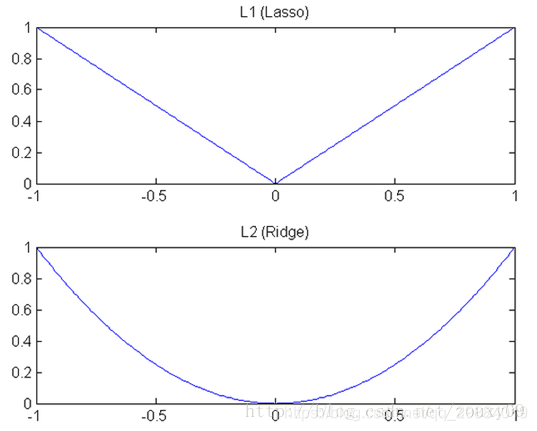
L1范数是指向量中各个元素的绝对值之和,是L0范数的最优凸近似,更容易优化求解,如下图所示:

L2范数
L2范数是取向量元素的平方和后再开方,也称"weight decay",可以起到预防过拟合的作用(权值衰减,网络更简单)。此外,也有助于处理 condition number 较大情况下的矩阵求逆问题。
(这里对于第二点好处就不展开论述了,详见机器学习中的范数规则化之(一)L0、L1与L2范数),但是作为总结简单说下。首先凸优化中主要有两大较为棘手问题——局部最小值和 ill-condition 病态问题。ill-condition对应的是well-condition。那他们分别代表什么?假设我们有个方程组AX=b,我们需要求解X。如果A或者b稍微的改变,会使得X的解发生很大的改变,那么这个方程组系统就是ill-condition的,对系统输入的微小变化也很敏感,反之就是well-condition的。condition number衡量的是输入发生微小变化的时候,输出会发生多大的变化。也就是系统对微小变化的敏感度。condition number值小的就是well-conditioned的,大的就是ill-conditioned的。)
下面说下L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?
下降规则
L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快。所以会非常快得降到0。
模型空间的限制
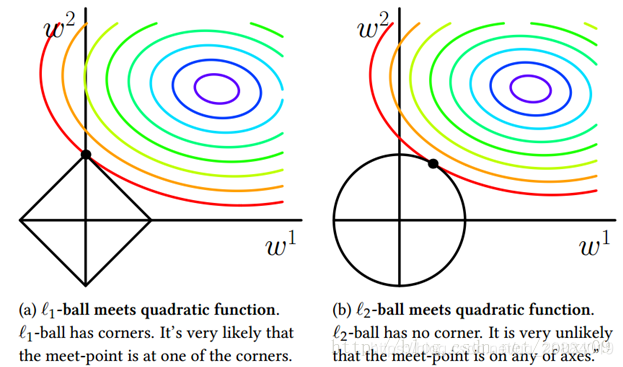
可以看到,L1和每个坐标轴相交的地方都有“角”出现,除了角之外很多边的轮廓也是有很大的概率成为第一次相交的地方,这都会产生稀疏性。而对于L2-ball,第一次相交的地方出现在具有稀疏性的位置的概率就非常小了,因此不能产生稀疏性。
L1会趋于产生少量的特征,而其他特征都是0,但是L2会选择更多特征,这些特征都会接近0。
核范数
在介绍核范数之前首先说下矩阵的秩,其物理意义主要是用于衡量矩阵行列之间的相关性。如果矩阵的各行或各列都是线性无关的,则矩阵式满秩的;如果矩阵各行之间的相关性很强,那么该矩阵实则可以投影到更低维的线性子空间中,表示成一个低秩的矩阵。
然而,对矩阵求秩rank()是非凸的,难以优化求解,因此就需要寻求它的凸近似,即为核范数 ∣ ∣ ω ∣ ∣ ∗ ||\omega||_* ∣∣ω∣∣∗。
首先给出数学公式,摘自浅说范数规范化(二)—— 核范数:


可以看出核范数实则表示奇异值/特征值的和,rank()表示的是非零奇异值的个数,因此可以理解为L1与L0范数之间的关系。
核范数的应用之一:鲁棒PCA(RPCA)
RPCA的基本思想是将原矩阵分解为两个矩阵相加,一个是低秩矩阵(原矩阵含有一定的结构信息,因此各行/各列是线性相关的),另一个是稀疏的(原矩阵中含有噪声,噪声是稀疏的),因此目标函数可以写成:
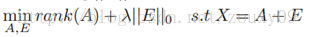
与经典PCA相同的是,RPCA本质上也是寻找数据在低维空间上的最佳投影问题。对于低秩数据观测矩阵X,假如X受到随机(稀疏)噪声的影响,则X的低秩性就会破坏,使X变成满秩的。所以我们就需要将X分解成包含其真实结构的低秩矩阵和稀疏噪声矩阵之和。找到了低秩矩阵,实际上就找到了数据的本质低维空间。
与经典PCA问题不同的是,因为PCA假设我们的数据的噪声是高斯的,对于大的噪声或者严重的离群点,PCA会被它影响,导致无法正常工作。而RPCA则不存在这个假设。它只是假设它的噪声是稀疏的,而不管噪声的强弱如何。
为便于优化求解,通常将原问题松弛到凸优化问题:
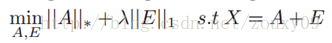
语音方面应用
有一类语音增强方法是基于RPCA模型的语音增强方法,认为带噪语音信号可以分解为低秩的噪声和稀疏的语音信号(语音信号往往只在若干个频点表现活跃),但是实验结果表明获得的系数矩阵中残留较多的噪声,低秩矩阵中也含有较多的语音信息,并不能实现很好的分离效果。因为语音时频谱矩阵除了具有稀疏性以外,也具有一定的低秩特性。
此外,在参考文献[3]中作者是将带噪语音分为低秩 L,稀疏 S和噪声 N三部分,其中低秩部分代表结构化噪声(结构化噪声部分通常具有比语音信号更加明显的重复和冗余结构),稀疏部分代表语音,而噪声则代表是非结构化噪声,这部分的分解运算可由GoDec算法实现。然而,由于单纯的稀疏低秩分解得到的低秩部分更关注信号在时频域的重复性而不侧重于研究这些重复信号所具有的具体特征,为此文献[3]提出对L用非负矩阵分解以学习到结构化噪声字典,具体如下:

其他改进算法我也没有多看,便不多说了。
参考博文:
原文1:https://blog.csdn.net/zouxy09/article/details/24972869
原文2:http://sakigami-yang.me/2017/09/09/norm-regularization-02/
[3] : 稀疏低秩模型下的单通道自学习语音增强算法

















 1765
1765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









