







摘要
本文提出了一种名为高分辨率网络(HRNet)的新型网络架构,旨在解决视觉识别任务中的高分辨率表示问题。与现有的方法不同,HRNet在整个过程中保持高分辨率表示,而不是通过低分辨率表示来恢复高分辨率。HRNet通过并行连接高分辨率和低分辨率卷积流,并反复进行多分辨率融合,从而生成语义丰富且空间精确的表示。首先,输入图像通过一个由两个步长为2的3x3卷积组成的初始模块(stem),将分辨率降低到1/4。然后,图像进入主体部分,主体部分由多个阶段组成,每个阶段包含多个并行卷积流,分别对应不同的分辨率。在每个阶段中,通过多分辨率融合模块反复交换不同分辨率之间的信息。最后,根据任务需求,选择不同的表示头(HRNetV1、HRNetV2或HRNetV2p)来输出最终的表示。实验表明,HRNet在人体姿态估计、语义分割和目标检测等任务中均表现出色,证明了其作为计算机视觉问题中更强骨干网络的潜力。
Abstract
This paper introduces a new network architecture called High-Resolution Network (HRNet), designed to address the challenge of maintaining high-resolution representations in visual recognition tasks. Unlike existing methods, HRNet keeps high-resolution representations throughout the entire process, instead of recovering high-resolution details from low-resolution representations. HRNet achieves this by connecting high-resolution and low-resolution convolutional streams in parallel and repeatedly fusing information across multiple resolutions. This approach generates representations that are both semantically rich and spatially precise.First, the input image passes through an initial module called the “stem”, which consists of two 3x3 convolutions with a stride of 2, reducing the resolution to 1/4 of the original. Then, the image enters the main body of the network, which is composed of multiple stages. Each stage contains several parallel convolutional streams, each corresponding to a different resolution. Within each stage, a multi-resolution fusion module repeatedly exchanges information between different resolutions. Finally, depending on the task, different representation heads (HRNetV1, HRNetV2, or HRNetV2p) are selected to produce the final output.Experiments show that HRNet performs exceptionally well in tasks such as human pose estimation, semantic segmentation, and object detection. These results demonstrate its potential as a stronger backbone network for solving computer vision problems.
视觉识别的深度高分辨率表征学习
Title: Deep High-Resolution Representation Learning for Visual Recognition
Author: Wang, JD (Wang, Jingdong) ; Sun, K (Sun, Ke) ; Cheng, TH (Cheng, Tianheng) ; Jiang, BR (Jiang, Borui) ; Deng, CR (Deng, Chaorui) ; Zhao, Y (Zhao, Yang) ; Liu, D (Liu, Dong) ; Mu, YD (Mu, Yadong) ; Tan, MK (Tan, Mingkui) ; Wang, XG (Wang, Xinggang) ; Liu, WY (Liu, Wenyu) ; Xiao, B (Xiao, Bin)
Source: IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE
WOS: https://www.webofscience.com/wos/alldb/full-record/WOS:000692232400010
研究背景
深度卷积神经网络(DCNNs)在许多计算机视觉任务中取得了最先进的结果,如图像分类、目标检测、语义分割和人体姿态估计等。大多数现有的分类网络(如AlexNet、VGGNet、GoogleNet、ResNet等)遵循LeNet-5的设计规则,即通过串联高分辨率到低分辨率的卷积逐渐减少特征图的空间尺寸,最终生成低分辨率表示。然而,对于位置敏感的任务(如语义分割、人体姿态估计和目标检测),高分辨率表示是必不可少的。

现有的方法通常通过从低分辨率表示中恢复高分辨率表示来解决这一问题。例如,Hourglass、SegNet、DeconvNet、U-Net和SimpleBaseline等方法通过上采样过程逐步恢复高分辨率表示。此外,扩张卷积也被用于去除一些下采样层,从而生成中等分辨率的表示。然而,这些方法在恢复高分辨率表示时可能会丢失一些空间信息,导致表示不够精确。
方法论
HRNet的核心思想是在整个过程中保持高分辨率表示,而不是通过低分辨率表示来恢复高分辨率。HRNet通过并行连接高分辨率和低分辨率卷积流,并反复进行多分辨率融合,从而生成语义丰富且空间精确的表示。
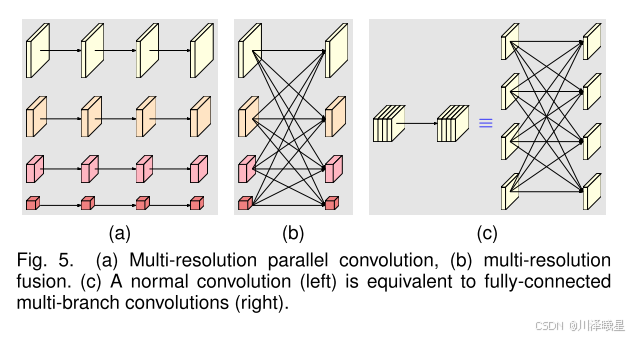
如上图所示,和普通卷积(c)相比,HRNet 进行了多分辨率并行卷积(a),并且进行了多分辨率融合(b)。这些设计使得 HRNet能够在保持高分辨率特征的同时,充分利用低分辨率的全局信息,从而在视觉任务中表现出色。
网络结构

具体来说,HRNet的主体部分由多个阶段组成,每个阶段包含多个并行卷积流,分别对应不同的分辨率。在每个阶段中,通过多分辨率融合模块反复交换不同分辨率之间的信息。多分辨率融合模块的输入是多个分辨率的表示,输出是经过融合后的表示。融合模块通过下采样和上采样操作将不同分辨率的表示转换为目标分辨率,然后将它们相加得到最终的输出表示。
不同尺度融合
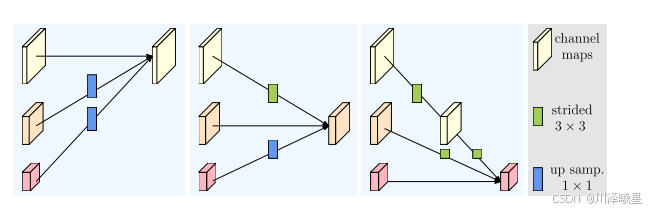
上图从左到右分别展示了高分辨率(High Resolution)、中分辨率(Medium Resolution)和低分辨率(Low Resolution)的特征图如何通过融合模块进行信息交换。每个分辨率的特征图通过不同的操作(如卷积、上采样或下采样)与其他分辨率的特征图进行融合。
-
高分辨率(High Resolution)特征图的处理:
高分辨率特征图通过stride=2的3×3卷积 进行下采样,生成中分辨率和低分辨率的特征图。
同时,高分辨率特征图也会直接保留,用于后续的高分辨率分支。 -
中分辨率(Medium Resolution)特征图的处理:
中分辨率特征图通过1×1卷积 进行处理,以调整通道数。
对于高分辨率分支,中分辨率特征图通过 双线性上采样(Bilinear Upsampling) 恢复到高分辨率。
对于低分辨率分支,中分辨率特征图通过stride=2的3×3卷积 进行下采样。 -
低分辨率(Low Resolution)特征图的处理:
低分辨率特征图通过1×1卷积 进行处理,以调整通道数。
对于高分辨率和中分辨率分支,低分辨率特征图通过 双线性上采样(Bilinear Upsampling) 恢复到相应的分辨率。
输出表示头
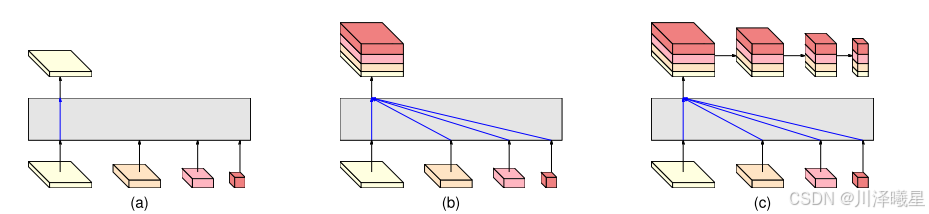
HRNet的输出表示头有三种形式:HRNetV1、HRNetV2和HRNetV2p。HRNetV1仅输出高分辨率卷积流的表示,适用于人体姿态估计任务。HRNetV2将所有分辨率的表示上采样到高分辨率并拼接在一起,适用于语义分割任务。HRNetV2p则通过下采样高分辨率表示生成多级表示,适用于目标检测任务。
代码解析
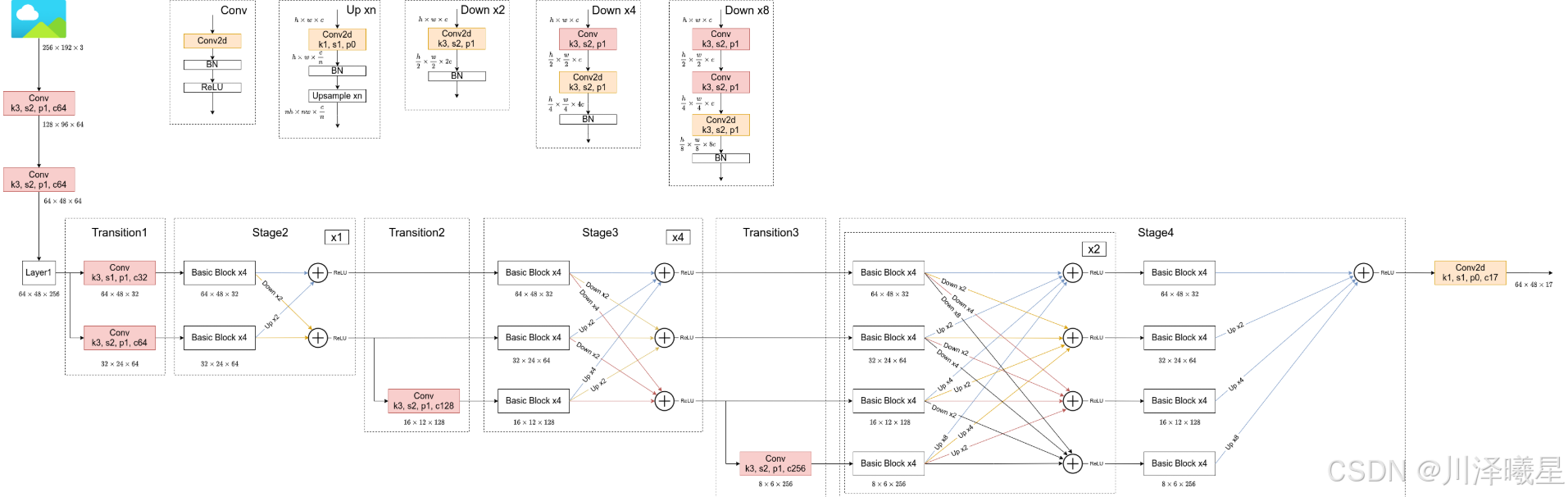
上图以HRNet-W32的模型结构为例绘制,该论文的核心思想就是不断地去融合不同尺度上的信息,也就是论文中所说的Exchange Blocks。
通过上图可以看出,HRNet首先通过两个卷积核大小为3x3步距为2的卷积层(后面都跟有BN以及ReLU)共下采样了4倍。然后通过Layer1模块,这里的Layer1其实和之前讲的ResNet中的Layer1类似,就是重复堆叠Bottleneck,注意这里的Layer1只会调整通道个数,并不会改变特征层大小。下面是实现Layer1时所使用的代码:
# Stage1
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256, momentum=BN_MOMENTUM)
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64)
)
将stage封装成一个类,如下所示:
class StageModule(nn.Module):
def __init__(self, input_branches, output_branches, c):
"""
构建对应stage,即用来融合不同尺度的实现
:param input_branches: 输入的分支数,每个分支对应一种尺度
:param output_branches: 输出的分支数
:param c: 输入的第一个分支通道数
"""
super().__init__()
self.input_branches = input_branches
self.output_branches = output_branches
self.branches = nn.ModuleList()
for i in range(self.input_branches): # 每个分支上都先通过4个BasicBlock
w = c * (2 ** i) # 对应第i个分支的通道数
branch = nn.Sequential(
BasicBlock(w, w),
BasicBlock(w, w),
BasicBlock(w, w),
BasicBlock(w, w)
)
self.branches.append(branch)
self.fuse_layers = nn.ModuleList() # 用于融合每个分支上的输出
for i in range(self.output_branches):
self.fuse_layers.append(nn.ModuleList())
for j in range(self.input_branches):
if i == j:
# 当输入、输出为同一个分支时不做任何处理
self.fuse_layers[-1].append(nn.Identity())
elif i < j:
# 当输入分支j大于输出分支i时(即输入分支下采样率大于输出分支下采样率),
# 此时需要对输入分支j进行通道调整以及上采样,方便后续相加
self.fuse_layers[-1].append(
nn.Sequential(
nn.Conv2d(c * (2 ** j), c * (2 ** i), kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(c * (2 ** i), momentum=BN_MOMENTUM),
nn.Upsample(scale_factor=2.0 ** (j - i), mode='nearest')
)
)
else: # i > j
# 当输入分支j小于输出分支i时(即输入分支下采样率小于输出分支下采样率),
# 此时需要对输入分支j进行通道调整以及下采样,方便后续相加
# 注意,这里每次下采样2x都是通过一个3x3卷积层实现的,4x就是两个,8x就是三个,总共i-j个
ops = []
# 前i-j-1个卷积层不用变通道,只进行下采样
for k in range(i - j - 1):
ops.append(
nn.Sequential(
nn.Conv2d(c * (2 ** j), c * (2 ** j), kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c * (2 ** j), momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
# 最后一个卷积层不仅要调整通道,还要进行下采样
ops.append(
nn.Sequential(
nn.Conv2d(c * (2 ** j), c * (2 ** i), kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c * (2 ** i), momentum=BN_MOMENTUM)
)
)
self.fuse_layers[-1].append(nn.Sequential(*ops))
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
# 每个分支通过对应的block
x = [branch(xi) for branch, xi in zip(self.branches, x)]
# 接着融合不同尺寸信息
x_fused = []
for i in range(len(self.fuse_layers)):
x_fused.append(
self.relu(
sum([self.fuse_layers[i][j](x[j]) for j in range(len(self.branches))])
)
)
return x_fused
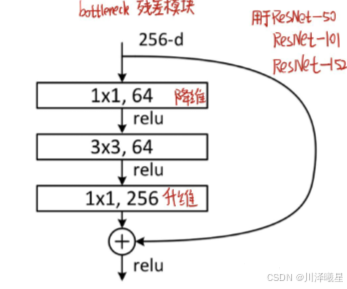
Bottleneck 结构如上图所示,首先先降维到中间层,然后再进行升维,因此 Bottleneck的第一个参数是输入通道,第二个参数是中间通道,最后一个参数是输出通道,代码如下:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
接着通过一系列Transition结构以及Stage结构,每通过一个Transition结构都会新增一个尺度分支。比如说Transition1,它在layer1的输出基础上通过并行两个卷积核大小为3x3的卷积层得到两个不同的尺度分支,即下采样4倍的尺度以及下采样8倍的尺度。在Transition2中在原来的两个尺度分支基础上再新加一个下采样16倍的尺度,注意这里是直接在下采样8倍的尺度基础上通过一个卷积核大小为3x3步距为2的卷积层得到下采样16倍的尺度。
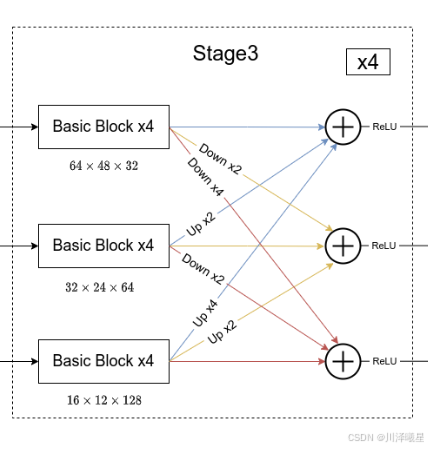
介绍完Transition结构后,在来说说网络中最重要的Stage结构。以Stage3为例,对于每个尺度分支,首先通过4个Basic Block,然后融合不同尺度上的信息。对于每个尺度分支上的输出都是由所有分支上的输出进行融合得到的。比如说对于下采样4倍分支的输出,它是分别将下采样4倍分支的输出(不做任何处理) 、 下采样8倍分支的输出通过Up x2上采样2倍 以及下采样16倍分支的输出通过Up x4上采样4倍进行相加最后通过ReLU得到下采样4倍分支的融合输出。其他分支也是类似的,上图画的已经非常清楚了。图中右上角的x4表示该模块(Basic Block和Exchange Block)要重复堆叠4次。
Basic Block 是Res-Net中采用的结构,如下图所示:
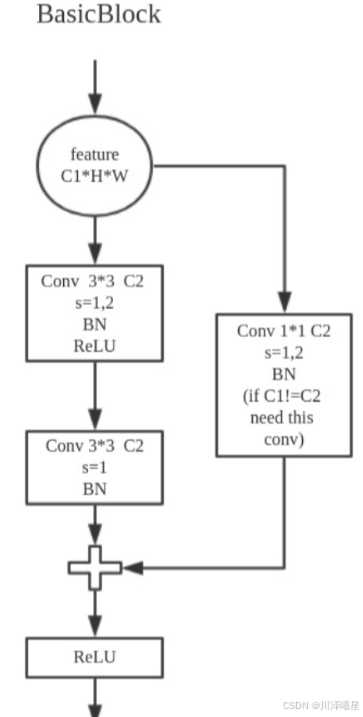
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
上采样和下采样的具体实现
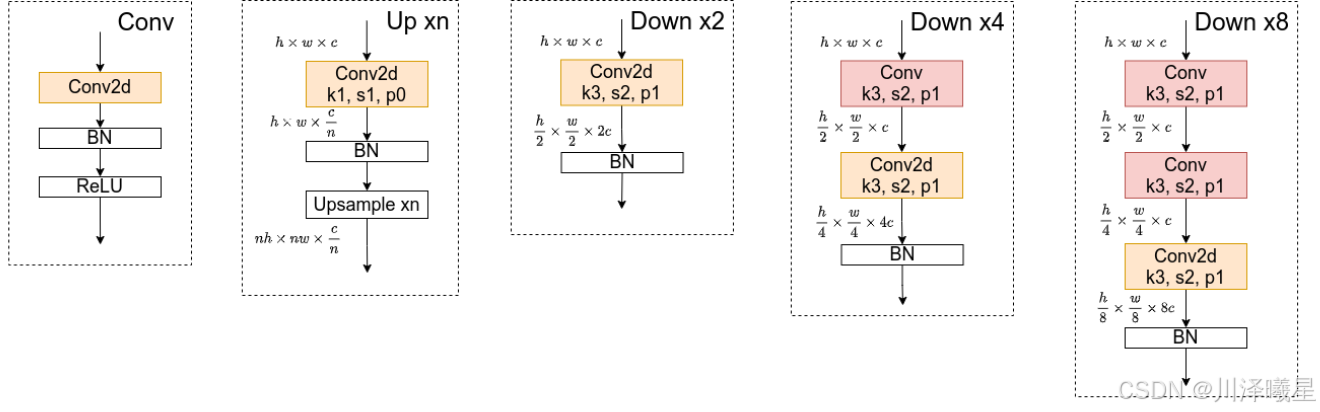
对于所有的Up模块就是通过一个卷积核大小为1x1的卷积层然后BN层最后通过Upsample直接放大n倍得到上采样后的结果(这里的上采样默认采用的是nearest最邻近插值)。Down模块相比于Up稍微麻烦点,每下采样2倍都要增加一个卷积核大小为3x3步距为2的卷积层(注意上图中Conv和Conv2d的区别,Conv2d就是普通的卷积层,而Conv包含了卷积、BN以及ReLU激活函数)。
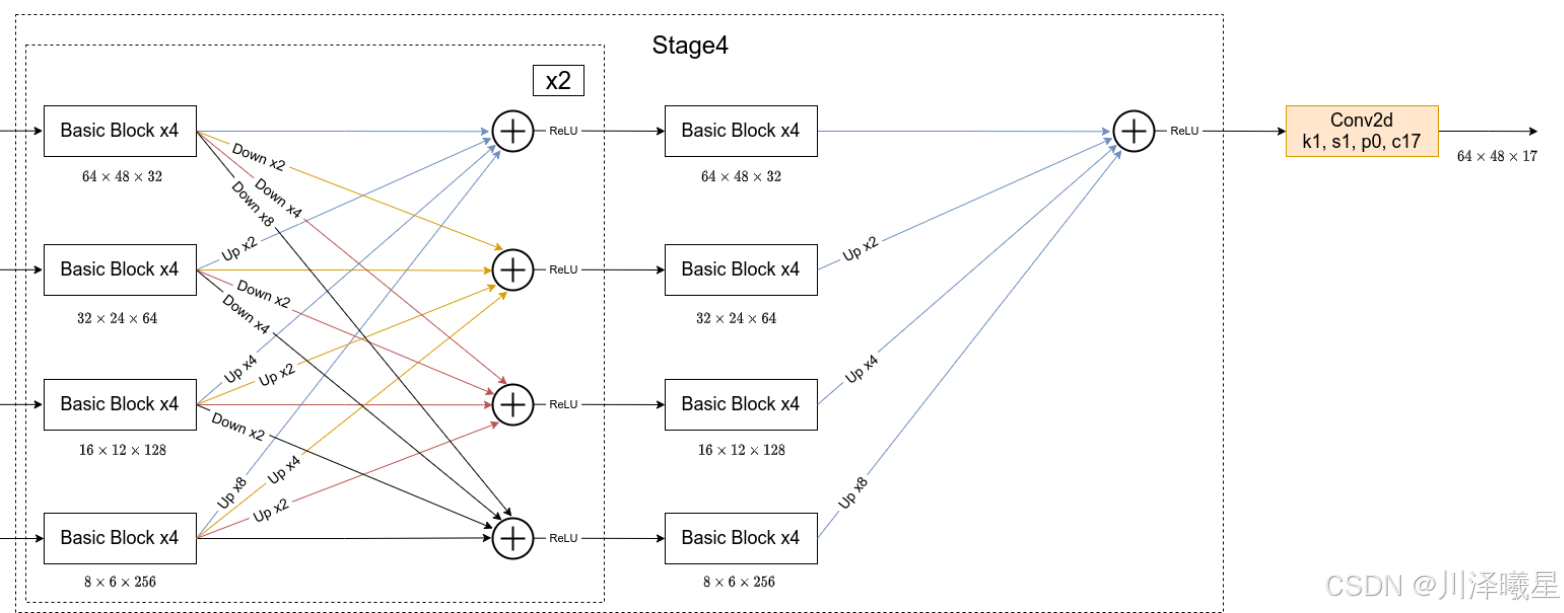
最后,在Stage4中的最后一个Exchange Block只输出下采样4倍分支的输出(即只保留分辨率最高的特征层),然后接上一个卷积核大小为1x1卷积核个数为17(因为COCO数据集中对每个人标注了17个关键点)的卷积层。最终得到的特征层(64x48x17)就是针对每个关键点的heatmap(热力图)。
综上所述,总的HRNet网络结构代码如下:
class HighResolutionNet(nn.Module):
def __init__(self, base_channel: int = 32, num_joints: int = 17):
super().__init__()
# Stem
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(64, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
# Stage1
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256, momentum=BN_MOMENTUM)
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64)
)
self.transition1 = nn.ModuleList([
nn.Sequential(
nn.Conv2d(256, base_channel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(base_channel, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
),
nn.Sequential(
nn.Sequential( # 这里又使用一次Sequential是为了适配原项目中提供的权重
nn.Conv2d(256, base_channel * 2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(base_channel * 2, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
])
# Stage2
self.stage2 = nn.Sequential(
StageModule(input_branches=2, output_branches=2, c=base_channel)
)
# transition2
self.transition2 = nn.ModuleList([
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Sequential(
nn.Sequential(
nn.Conv2d(base_channel * 2, base_channel * 4, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(base_channel * 4, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
])
# Stage3
self.stage3 = nn.Sequential(
StageModule(input_branches=3, output_branches=3, c=base_channel),
StageModule(input_branches=3, output_branches=3, c=base_channel),
StageModule(input_branches=3, output_branches=3, c=base_channel),
StageModule(input_branches=3, output_branches=3, c=base_channel)
)
# transition3
self.transition3 = nn.ModuleList([
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Identity(), # None, - Used in place of "None" because it is callable
nn.Sequential(
nn.Sequential(
nn.Conv2d(base_channel * 4, base_channel * 8, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(base_channel * 8, momentum=BN_MOMENTUM),
nn.ReLU(inplace=True)
)
)
])
# Stage4
# 注意,最后一个StageModule只输出分辨率最高的特征层
self.stage4 = nn.Sequential(
StageModule(input_branches=4, output_branches=4, c=base_channel),
StageModule(input_branches=4, output_branches=4, c=base_channel),
StageModule(input_branches=4, output_branches=1, c=base_channel)
)
# Final layer
self.final_layer = nn.Conv2d(base_channel, num_joints, kernel_size=1, stride=1)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.layer1(x)
x = [trans(x) for trans in self.transition1] # Since now, x is a list
x = self.stage2(x)
x = [
self.transition2[0](x[0]),
self.transition2[1](x[1]),
self.transition2[2](x[-1])
] # New branch derives from the "upper" branch only
x = self.stage3(x)
x = [
self.transition3[0](x[0]),
self.transition3[1](x[1]),
self.transition3[2](x[2]),
self.transition3[3](x[-1]),
] # New branch derives from the "upper" branch only
x = self.stage4(x)
x = self.final_layer(x[0])
return x
预测结果:
原图

预测出来的json文件如下:
{
"keypoints": ["nose","left_eye","right_eye","left_ear","right_ear","left_shoulder","right_shoulder","left_elbow","right_elbow","left_wrist","right_wrist","left_hip","right_hip","left_knee","right_knee","left_ankle","right_ankle"],
"skeleton": [[16,14],[14,12],[17,15],[15,13],[12,13],[6,12],[7,13],[6,7],[6,8],[7,9],[8,10],[9,11],[2,3],[1,2],[1,3],[2,4],[3,5],[4,6],[5,7]],
"flip_pairs": [[1,2], [3,4], [5,6], [7,8], [9,10], [11,12], [13,14], [15,16]],
"kps_weights": [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.2, 1.2, 1.5, 1.5, 1.0, 1.0, 1.2, 1.2, 1.5, 1.5],
"upper_body_ids": [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
"lower_body_ids": [11, 12, 13, 14, 15, 16]
}

创新性
并行连接高分辨率和低分辨率卷积流:与现有的方法不同,HRNet通过并行连接高分辨率和低分辨率卷积流,而不是串联连接。这种设计使得HRNet能够在整个过程中保持高分辨率表示,从而生成更精确的空间表示。
反复进行多分辨率融合:HRNet通过反复进行多分辨率融合,将低分辨率表示的语义信息与高分辨率表示的空间信息相结合,从而生成语义丰富且空间精确的表示。
多种输出表示头:HRNet提供了三种输出表示头(HRNetV1、HRNetV2和HRNetV2p),分别适用于不同的视觉任务。这种灵活性使得HRNet能够在多个任务中表现出色。
实验结果

HRNet在多个视觉任务中进行了广泛的实验,包括人体姿态估计、语义分割和目标检测。实验结果表明,HRNet在这些任务中均表现出色,证明了其作为计算机视觉问题中更强骨干网络的潜力。
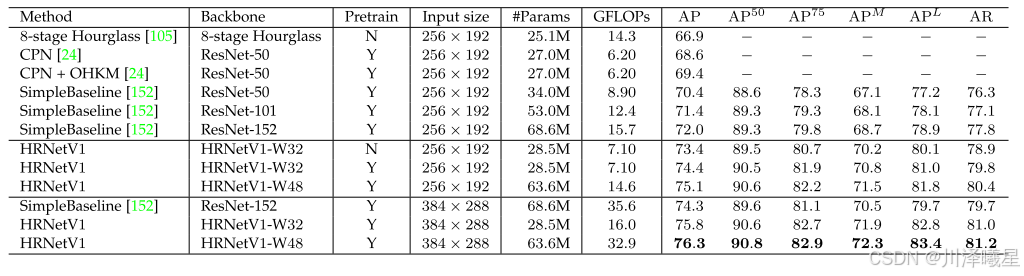
从上表可以看出,HRNet在人体姿态估计任务中表现出色,尤其是在输入尺寸为256×192时,HRNetV1-W32以73.4的AP分数超越了其他先进方法。与Hourglass相比,HRNetV1-W32在AP上提升了6.5分,同时计算量大幅降低;与CPN相比,HRNetV1-W32在模型大小和计算复杂度略高的情况下,AP分别提升了4.8和4.0分;与SimpleBaseline相比,HRNetV1-W32在AP上提升了3.0分(ResNet-50骨干)和1.4分(ResNet-152骨干),且计算量和参数量显著更低。通过使用ImageNet预训练模型或增加模型宽度(如HRNetV1-W48),HRNet的性能可以进一步提升。在输入尺寸为384×288时,HRNetV1-W32和HRNetV1-W48的AP分别达到75.8和76.3,相比SimpleBaseline(ResNet-152骨干)分别提升了1.5和2.0分,同时计算量仅为后者的45%和92.4%。这些结果表明,HRNet通过高分辨率特征保持和多分辨率融合的设计,在保持高效计算的同时,显著提升了姿态估计的精度。
局限性
- 计算成本高
HRNet通过保持高分辨率特征图来提升精度,但这带来了较高的计算和内存开销,尤其在处理高分辨率图像时,推理速度较慢,难以在资源受限的设备上部署。 - 参数量大
网络结构复杂,参数量较多,导致模型体积庞大,训练和推理时需要更多资源,限制了其在移动设备或嵌入式系统中的应用。 - 对小目标检测效果有限
虽然HRNet在高分辨率特征图上表现良好,但对于小目标的检测和分割效果仍有提升空间,尤其是当目标与背景对比度较低时。 - 多尺度特征融合不够充分
HRNet通过并行多分辨率分支进行特征融合,但在某些任务中,这种融合方式可能不够充分,导致信息传递不够高效。
针对以上的这几个局限性,结合目前阅读过的论文和了解的技术,我想到了以下几个可能的改进方向:
- 轻量化设计
可以通过引入轻量化模块(如深度可分离卷积、通道剪枝等)减少计算量和参数量,同时保持较高的精度。例如,结合MobileNet或ShuffleNet的思想,设计更高效的网络结构。 - 动态分辨率调整
引入动态分辨率机制,根据输入图像的内容自适应调整特征图的分辨率。对于简单场景,降低分辨率以减少计算量;对于复杂场景,保持高分辨率以提升精度。 - 增强小目标检测能力
通过引入注意力机制或特征金字塔网络(FPN),增强对小目标的检测能力。注意力机制可以帮助网络更关注小目标区域,而FPN可以更好地捕捉多尺度信息。 - 改进特征融合策略
设计更高效的特征融合模块,例如通过跨层连接或自适应权重分配,提升多分辨率特征之间的信息传递效率。可以考虑引入Transformer中的自注意力机制,增强全局上下文信息的利用。 - 知识蒸馏
使用知识蒸馏技术,将大模型的知识迁移到轻量化模型中,从而在减少计算量的同时保持较高的精度。例如,用HRNet作为教师模型,训练一个更小的学生模型。 - 结合自监督学习
通过自监督学习预训练模型,提升模型在有限标注数据下的泛化能力。自监督学习可以利用大量未标注数据,增强模型的特征提取能力。
总结
本文提出的HRNet通过并行连接高分辨率和低分辨率卷积流,并反复进行多分辨率融合,生成语义丰富且空间精确的表示。实验结果表明,HRNet在人体姿态估计、语义分割和目标检测等任务中均表现出色,证明了其作为计算机视觉问题中更强骨干网络的潜力。尽管HRNet在计算复杂度和内存消耗方面存在一些局限性,但通过优化计算复杂度、减少内存消耗和加速训练过程,可以进一步提升其性能。未来的研究可以探索将HRNet与其他技术结合,以进一步提高其在语义分割和实例分割等任务中的表现。

















 7123
7123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









