







前言
有挺久没有写博客了 现如今记录一下Android比较重要都一个知识点 也是面试点考点,很多面试都会以Handler作为切入点去了解求职人员的技术深度(比如菜鸡我在之前面试的时候就在Handler里面栽过跟头)
下面有一些内容是我总结出来的知识要点 发表在csdn上也是为了以后如果需要复习的时候好找复习点
如果带着一下比较常问的面试提读这篇文章可以更好的掌握Handler的玄妙
问题
- Handler有哪些作用?
- 为什么我们能在主线程直接使用Handler,而不需要创建Looper?
- 如果想要在子线程创建Handler,需要做什么准备?
- 一个线程有几个Handler?
- 一个线程有几个Looper?如何保证?
- 为什么Lopper死循环,却不会导致应用卡死?
- Handler内存泄露原因? 如何解决?
- 线程维护的Looper,在消息队列无消息时的处理方案是什么?有什么用?
- 我们可以使用多个Handler往消息队列中添加数据,那么可能存在发消息的Handler存在不同的线程,那么Handler是如何保证MessageQueue并发访问安全的呢?
- Handler是如何进行线程切换的呢?
- 我们在使用Message的时候,应该如何去创建它?
- Handler里面藏着的CallBack能做什么?
- Handler阻塞唤醒机制是怎么一回事?
- 什么是Handler的同步屏障?
- 能不能让一个Message被加急处理?
什么是Handler?
我们通常所说的Handler,他其实是Handler机制中的一个角色,只不过我们对Handler接触比较多,因此用Handler来代称
Handler机制是Android中基于单线消息队列模式的一套线程消息机制。
Handler基本用法
//在主线程创建Handler实例
private Handler mHandler = new Handler() {
@Override
public void handleMessage(@NonNull Message msg) {
//处理接收的消息
}
};
//在适当的时机使用Handler实例发送消息
mHandler.sendMessage(message);
mHandler.post(runnable);//Runnable会被封装进一个Message,所以它本质上还是一个Message
复制代码看上面这段代码,创建了一个Handler实例并重写了 handleMessage 方法 ,然后在适当的时机调用它的 send 或者 post 系列方法就可以了,使用就是这么简单
那么问题来了,它们是如何进行线程间的通信的呢? 下面我们就需要对源码进行分析
Handler机制源码分析
在分析源码之前,我先讲下Handler机制涉及的几大角色: Handler,Looper,MessageQueue,Message
先提前介绍下这几个角色的作用,便于后续分析源码的一个理解
Handler: 发送消息和处理消息
Looper: 从MessageQueue中获取Message,然后交给Handler处理
MessageQueue: 消息队列,存放Handler发送过来的消息
Message: 消息的载体
如图所示:

下面我们开始进行源码分析,在我们一开始使用的时候,创建了一个Handler实例,那我们看下它实例化的这个构造方法:
public Handler() {
this(null, false);
}
复制代码它其实是调用了它的一个重载的方法,接着看它的重载方法
注意:
- Handler的构造方法中还可以传入Looper,通过传入Looper的构造方法可以实现一些特殊的功能
- Handler的构造方法中还可以传入Callback,这种方式创建一个Handler的实例,它并不需要派生出一个子类,后面我也会介绍到
- 有些构造方法使用了
@UnsupportedAppUsage注解,表示不支持外部应用调用
public Handler(@Nullable Callback callback, boolean async) {
//...
//获取当前线程的Lopper
mLooper = Looper.myLooper();
//如果当前Looper为空,则抛出异常
if (mLooper == null) {
throw new RuntimeException(
"Can't create handler inside thread " + Thread.currentThread()
+ " that has not called Looper.prepare()");
}
//将当前Lopper中的MessageQueue赋值给Handler中的MessageQueue
mQueue = mLooper.mQueue;
//...
}
//---------------------以下为额外扩展内容--------------------------
//传入Looper的构造方法
public Handler(@NonNull Looper looper) {
this(looper, null, false);
}
//传入Callback的构造方法
public Handler(@Nullable Callback callback) {
this(callback, false);
}
//使用了@UnsupportedAppUsage注解的构造方法
@UnsupportedAppUsage
public Handler(boolean async) {
this(null, async);
}
复制代码上面这段代码注释写的很清楚,那我们是不是就可以得出一个结论: 我们在创建Handler实例的时候,一定要先创建一个Lopper,并开启循环读取消息,那么大家肯定有个疑问? 你上面的使用就没有创建Lopper,那是因为我们的主线程已经给我们创建了一个Lopper
接下来我们找下主线程的这个Lopper是在哪里创建的,我们找到ActivityThread的main()方法
public static void main(String[] args) {
//...
//创建Lopper
Looper.prepareMainLooper();
ActivityThread thread = new ActivityThread();
thread.attach(false);
if (sMainThreadHandler == null) {
sMainThreadHandler = thread.getHandler();
}
//...
//开启循环读取消息
Looper.loop();
//Looper如果因异常原因停止循环则抛异常
throw new RuntimeException("Main thread loop unexpectedly exited");
}
复制代码注意:通常我们认为 ActivityThread 就是主线程。事实上它并不是一个线程,而是主线程操作的管理者,所以们把 ActivityThread 认为就是主线程无可厚非,另外主线程也可以说成 UI 线程。
我们在 ActivityThread里的main方法里调用了Looper.prepareMainLooper() 方法创建了主线程的Looper ,并且调用了loop方法,所以我们就可以直接使用 Handler
继续分析,我们知道main()方法是Java程序的入口,同时也是Android应用程序的入口,而在Java中,我们执行完main()方法,马上就退出了,而在Android中,为啥没有退出呢?这里我们做个假设,如果在Android中也退出了,那么是不是Android就没得玩了,所以Google肯定是不能让他退出的,之所以在Android中没有退出,正是因为我们在这里创建并开启了Looper死循环,他会循环执行各种事物。Looper死循环说明线程没有死亡,如果Looper停止循环,线程则结束退出了
那么大家是不是又会有个疑问?既然是一个死循环,那为啥不会造成ANR?
其实Lopper死循环和程序ANR没有任何关系,这里感觉就是在进行一个概念的混淆,这里我解释一下这两个概念
ANR: 全称Applicationn Not Responding,中文意思是应用无响应,当我发送一个消息到主线程,经过一定时间没有被执行,那么这个时候就会抛出ANR异常
Lopper死循环: 循环执行各种事务,当Looper处理完所有消息的时候会进入阻塞状态,当有新的Message进来的时候会打破阻塞继续执行
到了这里,相信大家对于创建Handler已经很明了了,下面我们来实际应用一下,在子线程创建Handler,直接上代码:
public static class MyThread extends Thread {
public Handler mHandler;
public void run() {
Looper.prepare();
mHandler = new Handler() {
public void handleMessage(@NonNull Message msg) {
//处理接收的消息
}
};
Looper.loop();
}
}
复制代码好,到了这里,我们应该对创建Handler实例的时候,一定要先创建一个Lopper,并开启循环读取消息,有了深刻的理解,我们继续分析源码
上面说了创建Handler实例之前要先创建Looper并开启循环,那我们分析下创建Lopper并开启循环这个过程,先看下ActivityThread里的main方法里调用的Looper.prepareMainLooper()
public static void prepareMainLooper() {
//创建Looper,参数false表示该Looper不能退出
prepare(false);
//添加同步锁
synchronized (Looper.class) {
//如果当前sMainLooper已经存在,则抛异常
if (sMainLooper != null) {
throw new IllegalStateException("The main Looper has already been prepared.");
}
//将当前线程的Looper实例赋值给sMainLooper
sMainLooper = myLooper();
}
}
复制代码实际上主要是调用了另外两个方法,我们在看下prepare(false)和myLooper()方法的内部实现
private static void prepare(boolean quitAllowed) {
//通过sThreadLocal获取当前Looper实例,如果当前Lopper实例不为空则抛出异常
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
//将new出来的Looper实例设置给sThreadLocal
sThreadLocal.set(new Looper(quitAllowed));
}
复制代码public static @Nullable Looper myLooper() {
//通过sThreadLocal获取Looper实例对象
return sThreadLocal.get();
}
复制代码prepare方法: new一个Looper设置给sThreadLocal. myLooper方法: 通过sThreadLocal获取Looper. 上面两个方法,大家是不是会对这个sThreadLocal很好奇,这个东西有啥作用,我们根据上面两个方法可以推断出: sThreadLocal是用来存放Looper的
ThreadLocal介绍
ThreadLocal是Java中一个用于线程内部存储数据的工具类
看下面这一段代码
public static void main(String[] args) {
ThreadLocal<Boolean> threadLocal = new ThreadLocal<>();
threadLocal.set(true);
Boolean aBoolean = threadLocal.get();
System.out.println("Current Thread " + Thread.currentThread().getName() + ": " + aBoolean);
//创建一个新的线程命名为a
new Thread("a"){
@Override
public void run() {
threadLocal.set(false);
Boolean bBoolean = threadLocal.get();
System.out.println("Current Thread " + Thread.currentThread().getName() + ": " + bBoolean);
}
}.start();
//创建一个新的线程命名为b
new Thread("b"){
@Override
public void run() { ;
Boolean cBoolean = threadLocal.get();
System.out.println("Current Thread " + Thread.currentThread().getName() + ": " + cBoolean);
}
}.start();
}
//打印结果:
Current Thread main: true
Current Thread a: false
Current Thread b: null
复制代码上面这段代码:
- 在主线程创建了一个threadLocal变量,并调用
set方法设置为true,然后获取该值并打印 - 创建一个新的线程,并调用
set方法设置值为false,获取获取该值并打印 - 创建一个新的线程,获取该值并打印
从上面的日志可以看出,虽然在不同的线程中访问同一个threadLocal对象,但是它们通过ThreadLocal获取的值却是不一样的,这就是ThreadLocal的奇妙之处,这里我又想问一句,为什么? 凡事多问几个为什么,知识原理就学到手了,哈哈😄,我们点进去ThreadLocal的set方法看一下
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取当前线程的ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null)
//如果map不为空,则将当前的ThreadLocal变量作为key,传进来的泛型作为value进行存储
map.set(this, value);
else
//如果map为空,则会创建map,将当前的ThreadLocal变量作为key,传进来的泛型作为value进行存储
createMap(t, value);
}
复制代码通过上面代码我们知道,通过获取当前线程的ThreadLocalMap,在把ThreadLocal变量作为key,传进来的泛型作为value进行存储
ThreadLocalMap它是ThreadLocal里面的一个静态内部类,它类似于一个改版的HashMap,内部也是使用数组和Hash算法来存储数据,使得存储和读取的速度非常快,因此这里我们使用HashMap的思想去理解ThreadLocalMap就好了。
在看下get方法
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
return setInitialValue();
}
复制代码获取当前线程的ThreadLocalMap,前面讲到ThreadLocalMap其实非常像一个HashMap,他的get方法也是一样的,使用ThreadLocal作为key获取到对应的Entry,再把value返回即可,如果map尚未初始化则会执行初始化操作
因此我们是否可以得到结论:

ThreadLocal会从各自的线程,取出自己维护的ThreadLocalMap,其key为ThreadLocal,value为ThreadLocal对应的泛型对象,这样每个ThreadLocal就可以把自己作为key把不同的value存储在不同的ThreadLocalMap,当获取数据的时候,同个ThreadLocal就可以从不同线程的ThreadLocalMap中得到不同的数据。因此当我们以线程作为作用域,并且不同线程需要具有不同数据副本的时候,我们就可以考虑使用ThreadLocal。而Looper正好适用于这种场景
Looper介绍
上面我们分析到Looper使用ThreadLocal来保证每个线程有且只有一个相同的副本,因此我们可以得出结论: 一个线程对应一个Looper,这个结论非常的重要,Handler机制之所以能够实现线程之间的通信,就是因为使用了不同线程的Looper处理消息,举个例子: 我在线程A创建了几个Hanlder实例处理消息,那我首先就要创建A线程的Looper并开启消息循环,那么我不管你这些Hanlder的实例从那个线程发送消息过来,最终都会回到我A线程的MessageQueue中,然后通过A线程Looper不断读取消息,在交给当前A线程的Handler来处理
Looper可以说是Handler机制中的一个非常重要的核心。Looper相当于线程消息机制的引擎,驱动整个消息机制运行。Looper负责从队列中取出消息,然后交给对应的Handler去处理。如果队列中没有消息,则MessageQueue的next方法会阻塞线程,等待新的消息的到来。每个线程有且只能有一个“引擎”,也就是Looper,如果没有Looper,那么消息机制就运行不起来,而如果有多个Looper,则会违背单线操作的概念,造成并发操作。
Looper创建
在上面创建Looper的时候我们分析到:
-
主线程ActivityThread创建Looper,使用的是
prepareMainLooper方法,它是为主线程量身定做的,由于主线程的Looper比较特殊,所以Looper提供了一个getMainLooper方法,通过这个方法我们可以在任何地方获取到主线程的Looper,且主线程的Looper不能退出 -
我们自己创建的Looper,使用的是
prepare方法,实质上它们最终都会调到prepare(boolean quitAllowed)这个方法,这个方法是私有的,外部不能直接调用,区别就是主线程创建的Looper不能退出,而我们自己创建的可以退出
//主线程
public static void prepareMainLooper() {
prepare(false);
//...
}
//获取主线程Looper
public static Looper getMainLooper() {
synchronized (Looper.class) {
return sMainLooper;
}
}
//我们自己创建Looper
public static void prepare() {
prepare(true);
}
//参数quitAllowed true: 可退出 false: 不可退出
private static void prepare(boolean quitAllowed) {
if (sThreadLocal.get() != null) {
throw new RuntimeException("Only one Looper may be created per thread");
}
sThreadLocal.set(new Looper(quitAllowed));
}
复制代码到这里我又有个疑问,为啥Looper不能直接在外部给New出来呢?我们点击去Looper的构造方法看一下:
private Looper(boolean quitAllowed) {
//创建一个MessageQueue,赋值给当前Looper的mQueue
mQueue = new MessageQueue(quitAllowed);
//获取当前线程赋值给Looper的mThread
mThread = Thread.currentThread();
}
复制代码我们发现,他的构造方法是私有的,原来如此。而且我们还会发现:Looper的内部维护了一个MessageQueue,当初始化Looper的时候会顺带初始化这个MessageQueue
Looper开启消息循环
当我们的Looper创建好后,他是不会自己启动的,需要我们手动去启动Looper,调用Looper的loop()方法即可,所以前面创建Looper的时候我总是会说,创建Looper并开启消息循环,Looper的prepare和loop方法是配套使用的,两者必须成对存在。现在我们来重点分析一下Looper的loop方法,上源码:
public static void loop() {
// 获取当前线程的Looper
final Looper me = myLooper();
//当前线程的Looper,直接抛异常
if (me == null) {
throw new RuntimeException("No Looper; Looper.prepare() wasn't called on this thread.");
}
//获取当前Looper中的MessageQueue
final MessageQueue queue = me.mQueue;
//...
//开启死循环读取消息
for (;;) {
// 获取消息队列中的消息
Message msg = queue.next(); // might block
if (msg == null) {
// 返回null说明MessageQueue退出了
return;
}
//...
try {
// 调用Message对应的Handler处理消息
msg.target.dispatchMessage(msg);
if (observer != null) {
observer.messageDispatched(token, msg);
}
dispatchEnd = needEndTime ? SystemClock.uptimeMillis() : 0;
}
//...
// 回收Message
msg.recycleUnchecked();
}
}
复制代码loop方法就是Looper这个“引擎”的核心所在,他就像是一个开关
分析下这段代码,首先获取当前线程的Looper对象,没有则抛异常,然后进入一个死循环: 不断调用MessageQueue的next方法来获取消息,然后调用message的目标handler的dispatchMessage方法来处理Message。
Looper退出
Looper提供了quit和quitSafely方法来退出一个Looper,二者的区别是: quit会直接退出Looper,而quitSafely只是设定一个标记,然后把消息队列中的已有消息处理完毕后才安全退出.在我们手动创建Looper的情况下,如果所有的消息都被处理完成后,我们应该调用quit方法来终止消息循环,否则子线程就会一直处于等待状态,而如果退出Looper,这个线程就会立刻终止,因此建议不需要的时候终止Looper。
public void quit() {
mQueue.quit(false);
}
public void quitSafely() {
mQueue.quit(true);
}
// 最终都是调用到了这个方法
void quit(boolean safe) {
// 如果不能退出则抛出异常。这个值在初始化Looper的时候被赋值
if (!mQuitAllowed) {
throw new IllegalStateException("Main thread not allowed to quit.");
}
synchronized (this) {
// 退出一次之后就无法再次运行了
if (mQuitting) {
return;
}
mQuitting = true;
// 执行不同的方法
if (safe) {
removeAllFutureMessagesLocked();
} else {
removeAllMessagesLocked();
}
// 唤醒MessageQueue
nativeWake(mPtr);
}
}
复制代码quit和quitSafely方法最终都调用了quit(boolean safe)这个方法,这个方法先判断是否能退出,然后再执行退出逻辑。如果mQuitting==true,那么这里会直接return掉,我们会发现mQuitting这个变量只有在这里被执行了赋值,所以一旦looper退出,则无法再次运行了。之后执行不同的退出逻辑,然后唤醒MessageQueue,之后MessageQueue的next方法会退出,Looper的loop方法也会跟着退出,那么线程也就停止了。
Looper总结
Looper作为Handler消息机制的“动力引擎”,不断从MessageQueue中获取消息,然后交给Handler去处理。Looper的使用前需要先初始化当前线程的Looper对象,再调用loop方法来启动它。
同时Handler也是实现切换的核心,因为不同的Looper运行在不同的线程,他所调用的dispatchMessage方法则运行在不同的线程,所以Message的处理就被切换到Looper所在的线程了。当looper不再使用时,可调用不同的退出方法来退出他,注意Looper一旦退出,线程则会直接结束。
Handler发送消息
Handler和Looper都创建好了,那么接下来我们就要使用Handler去发送消息,我们在最开始介绍Handler使用的时候,写了发送的两种消息类型,如下:
//在适当的时机使用Handler实例发送消息
mHandler.sendMessage(message);
mHandler.post(runnable);//Runnable会被封装进一个Message,所以它本质上还是一个Message
复制代码使用Handler发送消息,它有send 或者 post等一系列方法,最终这些发送的方法会调用到Handler中的enqueueMessage()方法,而Handler中的enqueueMessage方法最终会调用到MessageQueue的enqueueMessage方法,我们通过一个发送消息方法的源码看下,以我们最常用的sendMessage()这个方法为例:
注意:post系列方法,发送的是一个Runnable,Runnable会被封装进一个Message,所以它本质上还是一个Message
//1
public final boolean sendMessage(@NonNull Message msg) {
return sendMessageDelayed(msg, 0);
}
//2
public final boolean sendMessageDelayed(@NonNull Message msg, long delayMillis) {
if (delayMillis < 0) {
delayMillis = 0;
}
return sendMessageAtTime(msg, SystemClock.uptimeMillis() + delayMillis);
}
//3
public boolean sendMessageAtTime(@NonNull Message msg, long uptimeMillis) {
MessageQueue queue = mQueue;
if (queue == null) {
RuntimeException e = new RuntimeException(
this + " sendMessageAtTime() called with no mQueue");
Log.w("Looper", e.getMessage(), e);
return false;
}
return enqueueMessage(queue, msg, uptimeMillis);
}
//4
private boolean enqueueMessage(@NonNull MessageQueue queue, @NonNull Message msg,long uptimeMillis) {
//将当前的Handler赋值给Message的target属性
msg.target = this;
msg.workSourceUid = ThreadLocalWorkSource.getUid();
if (mAsynchronous) {
msg.setAsynchronous(true);
}
return queue.enqueueMessage(msg, uptimeMillis);
}
复制代码以上代码的调用顺序就是1->2->3->4
这里我给一张图来总结一下,send 或者 post等一系列方法的调用及最终的走向:
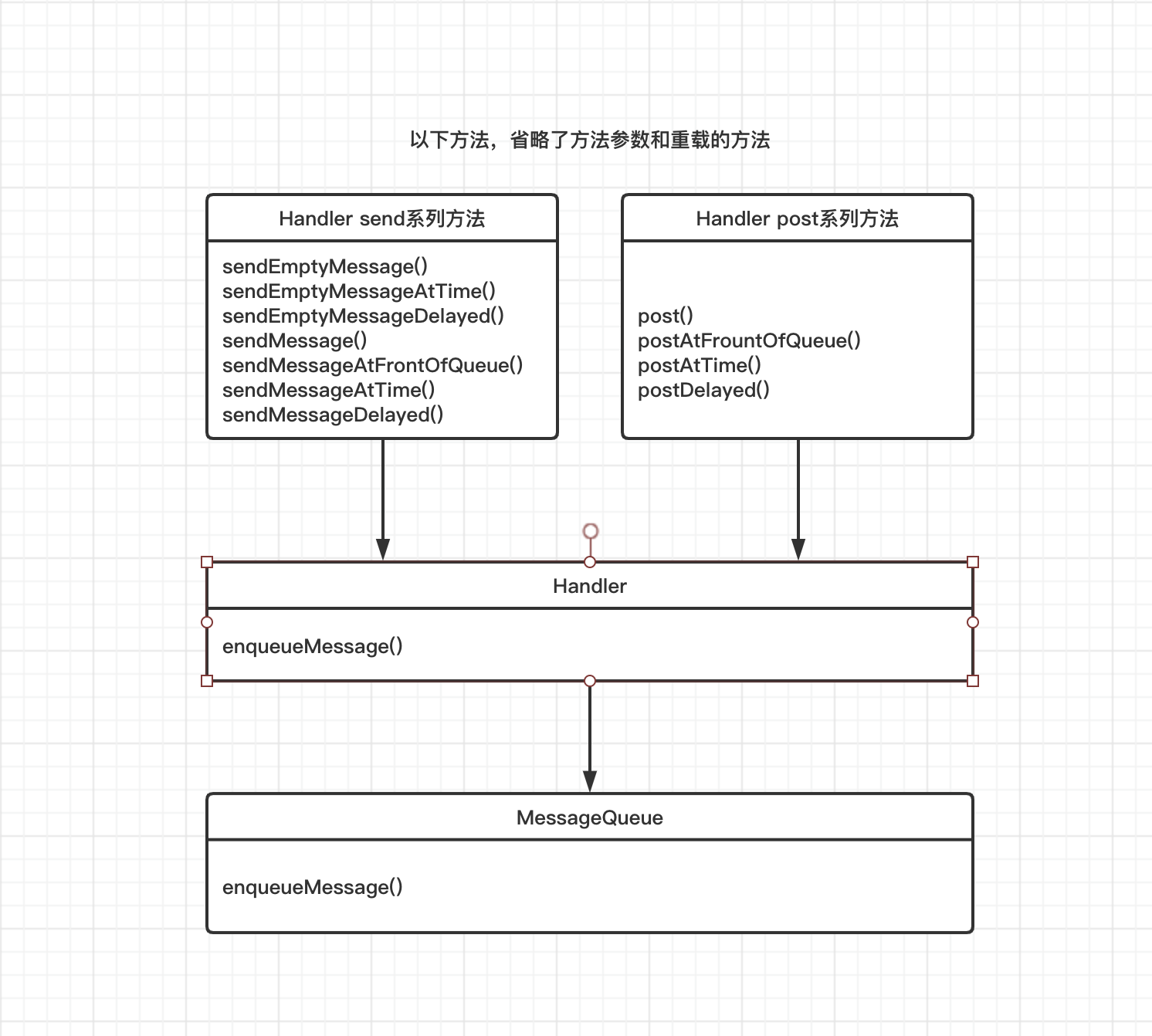
MessageQueue enqueueMessage方法介绍
到了这里,我们就来重点分析一下MessageQueue的enqueueMessage()方法,enqueueMessage中文意思是入队消息,见名知意,这个方法就是把Handler发送的消息,放到消息队列中
boolean enqueueMessage(Message msg, long when) {
// Hanlder为空则抛异常
if (msg.target == null) {
throw new IllegalArgumentException("Message must have a target.");
}
//当前消息如果已经已经被执行则抛异常
if (msg.isInUse()) {
throw new IllegalStateException(msg + " This message is already in use.");
}
// 对MessageQueue进行加锁
synchronized (this) {
// 判断目标thread是否已经死亡
if (mQuitting) {
IllegalStateException e = new IllegalStateException(
msg.target + " sending message to a Handler on a dead thread");
Log.w(TAG, e.getMessage(), e);
msg.recycle();
return false;
}
// 标记Message正在被执行,以及需要被执行的时间,这里的when是距离1970.1.1的时间
msg.markInUse();
msg.when = when;
// p是MessageQueue的链表头
Message p = mMessages;
// 判断是否需要唤醒MessageQueue
boolean needWake;
// 如果有新的队头,同时MessageQueue处于阻塞状态则需要唤醒队列
if (p == null || when == 0 || when < p.when) {
msg.next = p;
mMessages = msg;
needWake = mBlocked;
} else {
//...
// 根据时间找到插入的位置
Message prev;
for (;;) {
prev = p;
p = p.next;
if (p == null || when < p.when) {
break;
}
//...
}
msg.next = p;
prev.next = msg;
}
// 如果需要则唤醒队列
if (needWake) {
nativeWake(mPtr);
}
}
return true;
}
复制代码上述代码我们来总结一下:
-
首先判断Message中的Handler不能不空,且不能为在使用中,否则抛异常
-
对MessageQueue进行加锁,判断当前线程是否dead,如果dead则打印一个异常,并返回false
-
初始化Message的执行时间以并且标记为正在执行中
-
当新插入的Message在链表头时,如果messageQueue是空的或者正在等待下个延迟消息,则需要唤醒MessageQueue
-
根据Message的执行时间,找到在链表中的插入位置进行插入,这里我们可以理解MessageQueue中维护了一个优先级队列,
优先级队列就是链表根据时间进行排序并加入队列的数据结构形成的,例如我们发送的几个消息携带的时间分别为:1s,20ms,3s,那么这个时候就会根据时间进行排序为:20ms,1s,3s, 那么如果我新加入的一个消息的时间为2s,那么他就会插入1s和3s的中间,此时这个优先级队列就有了4个元素: 20ms,1s,2s,3s
MessageQueue next方法介绍
到这里,Handler发送的消息已经放到了MessageQueue中,那接着肯定就要进行消息的读取,我们刚讲到Looper的Loop方法会从MessageQueue中循环读取消息,loop方法中调用queue.next()的地方有句源码注释:might block,中文意思是可能被阻塞,如下:
public static void loop() {
//获取当前Looper中的MessageQueue
final MessageQueue queue = me.mQueue;
//...
//开启死循环读取消息
for (;;) {
// 获取消息队列中的消息
Message msg = queue.next(); // might block
}
//...
}
复制代码我们就看下MessageQueue的next方法到底做了什么:
Message next() {
// Return here if the message loop has already quit and been disposed.
// 源码中的注释表示:如果looper已经退出了,这里就返回null
final long ptr = mPtr;
if (ptr == 0) {
return null;
}
//...
// 定义阻塞时间赋值为0
int nextPollTimeoutMillis = 0;
//死循环
for (;;) {
if (nextPollTimeoutMillis != 0) {
Binder.flushPendingCommands();
}
// 阻塞对应时间 这个方法最终会调用到linux的epoll机制
nativePollOnce(ptr, nextPollTimeoutMillis);
// 对MessageQueue进行加锁,保证线程安全
synchronized (this) {
final long now = SystemClock.uptimeMillis();
Message prevMsg = null;
Message msg = mMessages;
//...
if (msg != null) {
if (now < msg.when) {
// 下一个消息还没开始,等待两者的时间差
nextPollTimeoutMillis = (int) Math.min(msg.when - now, Integer.MAX_VALUE);
} else {
// 获得消息且现在要执行,标记MessageQueue为非阻塞
mBlocked = false;
// 链表操作
if (prevMsg != null) {
prevMsg.next = msg.next;
} else {
mMessages = msg.next;
}
msg.next = null;
msg.markInUse();
return msg;
}
} else {
// 没有消息,进入阻塞状态
nextPollTimeoutMillis = -1;
}
//退出
if (mQuitting) {
dispose();
return null;
}
//...涉及了同步屏障和IdleHandler,后续在分析
}
}
复制代码从上面代码我们发现next方法目的是获取MessageQueue中的一个Message,它里面有一个死循环,如果消息队列中没有消息,那么next方法会一直阻塞在这里,当有新消息到来时,就会将它唤醒,next方法会返回这条消息并将其从优先级队列中给移除
步骤如下:
- 如果Looper已经退出了,直接返回null
- 进入死循环,直到获取到Message或者退出
- 循环中先判断是否需要进行阻塞,阻塞最终会调用到linux的epoll机制,阻塞结束后,对MessageQueue进行加锁,获取Message
- 如果MessageQueue中没有消息,则直接把线程无限阻塞等待唤醒
- 如果MessageQueue中有消息,则判断是否需要等待,否则则直接返回对应的message
可以看到逻辑就是判断当前时间Message中是否需要等待.其中nextPollTimeoutMillis表示阻塞的时间,-1表示无限时间,直到有事件发生为止,0表示不阻塞
Handler接收消息
在我们对Looper进行总结时我们说了: Handler也是实现线程切换的核心,因为不同的Looper运行在不同的线程,他所调用的dispatchMessage方法则会运行在不同的线程,所以Message的处理就会被切换到Looper所在的线程
public static void loop() {
for (;;) {
//...
try {
// 调用Message对应的Handler处理消息
msg.target.dispatchMessage(msg);
}
//...
}
}
复制代码上面代码调用了 msg.target.dispatchMessage(msg) 方法,msg.target 就是发送该消息的 Handler,这样消息最终会回调到Handler的dispatchMessage方法中,看下这个方法
public void dispatchMessage(@NonNull Message msg) {
//消息的callback不为空,则回调handleCallback方法
if (msg.callback != null) {
handleCallback(msg);
} else {
//当前mCallback不为空,回调mCallback.handleMessage方法
if (mCallback != null) {
if (mCallback.handleMessage(msg)) {
return;
}
}
//回调handleMessage
handleMessage(msg);
}
}
复制代码上述代码步骤:
1、首先,检查Message的callback是否为null,不为null就通过handleCallBack来处理消息,Message的callback是一个Runnable对象,实际上就是Handler的post系列方法所传递的Runnable参数,handleCallBack方法处理逻辑也很简单,如下:
private static void handleCallback(Message message) {
message.callback.run();
}
复制代码2、其次,检查mCallback是否为null,不为null就调用mCallback的handleMessage方法来处理消息。Callback是个接口,如下:
/**
* Callback interface you can use when instantiating a Handler to avoid
* having to implement your own subclass of Handler.
*/
public interface Callback {
boolean handleMessage(@NonNull Message msg);
}
复制代码通过Callback可以采用如下方式来创建Handlere对象:
Handler handler = new Handler(callback);
复制代码那Callback的意义是什么呢?源码里注释做了说明:可以用来创建一个Handler的实例但并不需要派生的子类。在日常开发中,创建Handler最常见的就是派生一个Handler的子类并重写其handleMessage方法来处理具体的消息,而Callback给我们提供了另外一种使用Handler的方式,当我们不想派生子类时,就可以通过Callback来实现。
3、最后,调用Handler的handleMessage方法来处理消息
Handler处理消息的过程我画了一张图,如下:
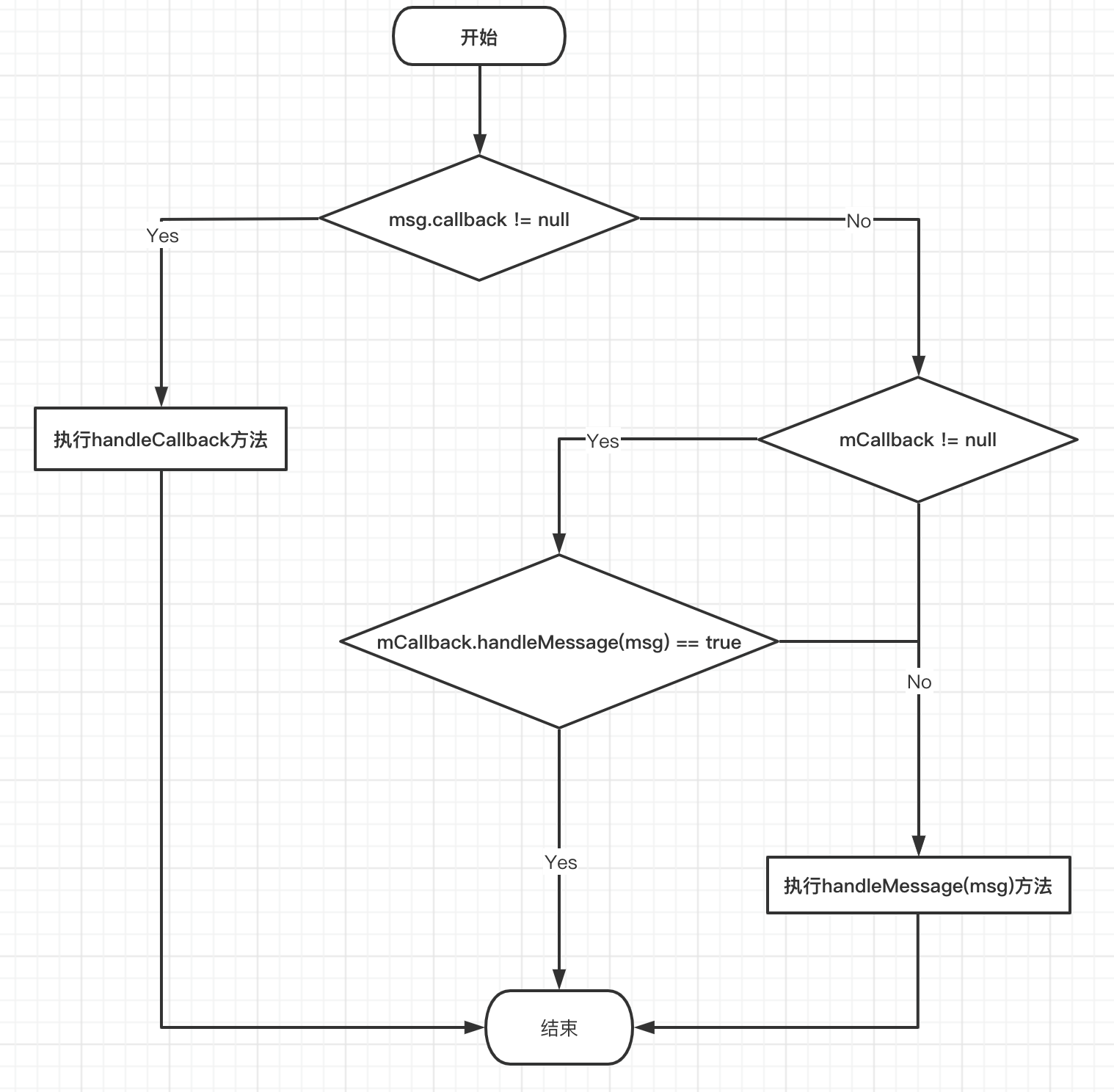
Message介绍
Message是负责承载消息的类,主要是关注他的内部属性:
// 用户自定义,主要用于辨别Message的类型
public int what;
// 用于存储一些整型数据
public int arg1;
public int arg2;
// 可放入一个可序列化对象
public Object obj;
// Bundle数据
Bundle data;
// Message处理的时间。相对于1970.1.1而言的时间
// 对用户不可见
public long when;
// 处理这个Message的Handler
// 对用户不可见
Handler target;
// 当我们使用Handler的post方法时候就是把runnable对象封装成Message
// 对用户不可见
Runnable callback;
// MessageQueue是一个链表,next表示下一个
// 对用户不可见
Message next;
复制代码我们使用Message的时候怎么创建它
Message msg = Message.obtainMessage();
首先在loop中使用queue.next();拿到Message之后调用msg.target.dispatchMessage(msg);去分发完消息之后

调用msg.recycleUnchecked();这个方法

将所有的内容清零然后放在一个sPool;里面实际上就是一个Message 是消息的另外一个队列 Message里面会维持两个队列 一个是MessageQueue的这个队列
另外一个是这个消息管理池这个队列
private static Message sPool;
为什么回收?
1 每打开一个App 通过Linux的Zygote进程会fork一个进程 每个应用会分配一个独立的虚拟机 会涉及到虚拟机的内存管理机制
会分配一些内存片且都是连续的
2 Message :在Android 和App会有很多Message,面对这么多Message如果每次都是New 一个Message 当在虚拟机里面的可达性分析 发现不可达的时候就会将Message的内存碎片回收掉 就会触发很多GC
在GC的时候会发生STW:Stop the world
会让线程停止工作 所以会造成卡顿
也有可能会造成OOM 因为你不断的new 一些Message 会在内存里面有大量的内存碎片 如果你需要new 一个4m bitMap的时候 需要一个连续的4兆内存空间。虽然总体上有4m的内存 但是没有连续的内存空间 所以会导致OOM

所以为了解决问题就在Message维持一个队列 一个Message池 里面给你放很多很多的Message 都是空的 当你要用的时候就直接在池子里面去拿 所以频发访问的是确定的内存
第一个:就是不需要不断的去New Message了
第二个:这个是被一个变量sPool持有且sPool属于一个静态的变量,他会一直在这个里面 所以不会被回收 会一直持有 所以不会出现频繁的GC

这个是什么设计模式
享元设计模式
recycleview里面使用的就是这个设计模式
在Adaput里面创建一个内部类,ViewHolder
这个里面会有OnCreateView 以及 BinderView
在这个过程中OnCreateView 调用很少 BingerView调用很多
因为recycleview里面 当各个I team输入同一个type下面他们的布局是一致的
当布局一样的时候 只需要将View的显示内容处理一下 然后再调用in Validate去触发View刷新就行了 不需要大量调用OnCreateView了
实际使用这个设计模式
比如当大量的iteam在滚动的时候有很多网络请求 请求的数据会有一个list返回出来 返回的list 需要频繁的去New 一个arrayList()或者LinkList()去保存数据
或者一个股票软件的时候需要每秒刷新数据的时候可以使用这个模式去优化设计
可以使用这个设计模式去优化 可以避免卡顿
且避免OOM















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









