







优化迭代方法统一论
线性回归建模
线性回归过程:训练,预测
线性回归公式模型表示及向量化表示
训 练 样 本 : { ( x ( i ) , y ( i ) ) } 训 练 样 本 集 : { ( x ( i ) , y ( i ) ) ; i = 1 , ⋯ , N } 向 量 化 : { ( x 1 ( i ) , x 2 ( i ) , y ( i ) ) } → { ( x ( i ) , y ( i ) ) } , x ( i ) = [ x 1 ( i ) x 2 ( i ) ] 我 们 学 习 什 么 ? f ( x ) = w x + b f ( x ( i ) ) ≈ y ( i ) f ( x ) = w T x + b f ( x ( i ) ) ≈ y ( i ) \begin{array}{l}训练样本:{\left\{\left(x^{(i)}, y^{(i)}\right)\right\}} \\\\训练样本集: {\left\{\left(x^{(i)}, y^{(i)}\right) ; i=1, \cdots, N\right\}} \\\\ 向量化: {\left\{\left(x_{1}^{(i)}, x_{2}^{(i)}, y^{(i)}\right)\right\} \rightarrow\left\{\left(\mathbf{x}^{(i)}, y^{(i)}\right)\right\}, \mathbf{x}^{(i)}=\left[\begin{array}{c}{x_{1}^{(i)}} \\ {x_{2}^{(i)}}\end{array}\right]} \\我们学习什么?\\ {f(x)=w x+b} \\ \\{f\left(x^{(i)}\right) \approx y^{(i)}} \\ \\{f(x)=\mathbf{w}^{T} \mathbf{x}+b} \\ \\{f\left(\mathbf{x}^{(i)}\right) \approx y^{(i)}}\end{array} 训练样本:{
(x(i),y(i))}训练样本集:{
(x(i),y(i));i=1,⋯,N}向量化:{
(x1(i),x2(i),y(i))}→{
(x(i),y(i))},x(i)=[x1(i)x2(i)]我们学习什么?f(x)=wx+bf(x(i))≈y(i)f(x)=wTx+bf(x(i))≈y(i)
下面讲述两种学习方法。
无约束优化梯度分析法
介绍一些前验知识:无约束优化问题、梯度、二次型、正定矩阵、泰勒级数展开、极值等。
无约束优化问题:
- 自变量为标量的函数
f : R → R min f ( x ) x ∈ R \begin{array}{ll}{f: \mathbb{R} \rightarrow}{\mathbb{R}} \\ {} & {\min f(x) \quad x \in \mathbb{R}} \end{array} f:R→Rminf(x)x∈R - 自变量为向量的函数
f : R n → R min f ( x ) x ∈ R n \begin{array}{ll}{f: \mathbb{R}^{n} \rightarrow \mathbb{R}} \\ {} & {\min f(\mathbf{x})} & {\mathbf{x} \in \mathbb{R}^{n}}\end{array} f:Rn→Rminf(x)x∈Rn - 等高线图(Contour)
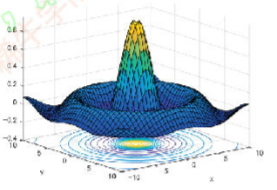
- 极值情况
极小、极大、鞍点(saddle point)、局部极大(极小)。
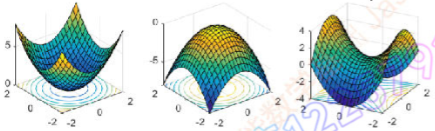
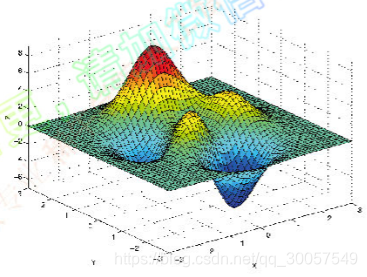
梯度:
一阶导数和梯度(gradient vector)
f ( x ) ; g ( x ) = ∇ f ( x ) = ∂ f ( x ) ∂ x = [ ∂ f ( x ) ∂ x 1 ⋮ ⋮ ∂ f ( x ) ∂ x n ] \begin{array}{l}{f(x) ; \quad \mathbf{g}(x)=\nabla f(x)=\frac{\partial f(x)}{\partial x}=\left[\begin{array}{c}{\frac{\partial f(x)}{\partial x_{1}}} \\ {\vdots} \\ {\vdots} \\ {\frac{\partial f(x)}{\partial x_{n}}}\end{array}\right]}\end{array} f(x);g(x)=∇f(x)=∂x∂f(x)=⎣⎢⎢⎢⎢⎢⎡∂x1∂f(x)⋮⋮∂xn∂f(x)⎦⎥⎥⎥⎥
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3900
3900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









