








概要
本篇博客讲解的是深度学习中经典模型——AlexNet。论文笔记已上传CSDN,如有需要请下载:AlexNet笔记 。利用AlexNet架构实现MNIST分类的代码请详见:TensorFlow深度学习实战(一):AlexNet对MNIST数据集进行分类 。AlexNet的原始论文请详见:ImageNet Classification with Deep Convolutional Neural Networks 。
一、简介
AlexNet是Alex Krizhevsky、Ilya Sutskever和 Geoffrey Hinton创造了一个“大型的深度卷积神经网络”,赢得了2010和2012 ILSVRC(2012年ImageNet 大规模视觉识别挑战赛)。2012年是CNN首次实现Top 5误差率15.4%的一年(Top 5误差率是指给定一张图像,其标签不在模型认为最有可能的5个结果中的几率),当时的第二名误差率为26.2%。我们可以看出性能提升相当大。AlexNet也是深度学习和神经网络的重新崛起转折点。正是由于AlexNet在ImageNet竞赛中夺冠,深度学习正是进入学术界的视野。
二、涉及技术
2.1 ReLU激活函数
在ReLU激活函数未提出之前,神经网络的激活函数主要为Sigmoid函数和Tanh函数。这里两个函数的表达式如下:
S
i
g
m
o
i
d
(
x
)
=
1
1
+
e
−
x
T
a
n
h
(
x
)
=
1
−
e
−
2
x
1
+
e
−
2
x
=
2
1
+
e
−
2
x
−
1
=
2
S
i
g
m
o
i
d
(
2
x
)
−
1
\begin{aligned} & Sigmoid(x)=\frac{1}{1+{{e}^{-x}}} \\ & Tanh(x)=\frac{1-{{e}^{-2x}}}{1+{{e}^{-2x}}}=\frac{2}{1+{{e}^{-2x}}}-1 \\ & =2Sigmoid(2x)-1 \end{aligned}
Sigmoid(x)=1+e−x1Tanh(x)=1+e−2x1−e−2x=1+e−2x2−1=2Sigmoid(2x)−1
两个函数的导数为:
S
i
g
m
o
i
d
′
(
x
)
=
S
i
g
m
o
i
d
(
x
)
[
1
−
S
i
g
m
o
i
d
(
x
)
]
T
a
n
h
′
(
x
)
=
1
-
T
a
n
h
(
x
)
2
\begin{aligned} & Sigmoi{d}'(x)=Sigmoid(x)\left[ 1-Sigmoid(x) \right] \\ & Tan{h}'(x)=1\text{-}Tanh{{(x)}^{2}} \\ \end{aligned}
Sigmoid′(x)=Sigmoid(x)[1−Sigmoid(x)]Tanh′(x)=1-Tanh(x)2
这两个函数的图像如上图所示。显然Sigmoid函数和Tanh的求导是极其方便的。Sigmoid函数的值域为
(
0
,
1
)
(0,1)
(0,1),图像关于0.5中心对称;Tanh函数值域为
(
−
1
,
1
)
(-1,1)
(−1,1) ,图像关于0中心对称,有利于相关数值的特殊处理。无论是Sigmoid函数还是Tanh函数,两者在实数范围内连续可导,优化稳定。同时当
x
→
∞
x\to\infty
x→∞时,函数区域平缓,导数趋向于0,因此Sigmoid和Tanh函数都是饱和函数,容易在训练后期出现梯度消失,导致训练后期出现梯度消失问题。但是从图2.1也可以看出,Tanh函数比Sigmoid函数收敛更快。
下面给出饱和函数的定义。设函数为
ϕ
(
x
)
\phi (x)
ϕ(x) ,若满足如下等式:
lim
x
→
+
∞
ϕ
′
(
x
)
=
0
\underset{x\to +\infty }{\mathop{\lim }}\,{\phi }'(x)=0
x→+∞limϕ′(x)=0
则称
ϕ
(
x
)
\phi (x)
ϕ(x) 为右饱和。同理,如满足等式:
lim
x
→
-
∞
ϕ
′
(
x
)
=
0
\underset{x\to \text{-}\infty }{\mathop{\lim }}\,{\phi }'(x)=0
x→-∞limϕ′(x)=0
则称 ϕ ( x ) \phi (x) ϕ(x) 为左饱和。那么, ϕ ( x ) \phi (x) ϕ(x) 为饱和的充要条件为: 既是左饱和又是右饱和。
同理对任意的 x x x ,如果存在常数 c c c ,当 x > c x>c x>c时,恒有 ϕ ′ ( x ) = 0 {\phi }'(x)=0 ϕ′(x)=0,则称 ϕ ( x ) \phi (x) ϕ(x) 是右硬饱和,当 x < c x<c x<c时,恒有 ϕ ′ ( x ) = 0 {\phi }'(x)=0 ϕ′(x)=0 ,则称 ϕ ( x ) \phi (x) ϕ(x) 为左硬饱和。 ϕ ( x ) \phi (x) ϕ(x)为硬饱和的充要条件为: 既是左硬饱和又是右硬饱和。 为软饱和的充要条件为:只有在极限状态下 ϕ ′ ( x ) = 0 {\phi }'(x)=0 ϕ′(x)=0。
在AlexNet论文当中,提出了利用非饱和非线性的ReLU函数作为激活函数。ReLU函数的函数表达式及其导数如下:
R
e
L
U
(
x
)
=
{
x
x
≥
0
0
x
<
0
R
e
L
U
′
(
x
)
=
{
1
x
≥
0
0
x
<
0
\begin{aligned} & ReLU(x)=\left\{ \begin{matrix} x & x\ge 0 \\ 0 & x<0 \\ \end{matrix} \right. \\ & ReL{U}'(x)=\left\{ \begin{matrix} \text{1} & x\ge 0 \\ 0 & x<0 \\ \end{matrix} \right. \\ \end{aligned}
ReLU(x)={x0x≥0x<0ReLU′(x)={10x≥0x<0
显然相比于Sigmoid函数和Tanh函数,ReLU函数及其导数没有复杂的指数运算与乘除运算,减少了计算负担。ReLU函数图像如下图所示。
在论文中也指出,使用ReLU的深度卷积神经网络训练速度比同样情况下使用Tanh单元的速度快好几倍。下图表示使用特定的四层卷积网络在数据集CIFAR-10上达到25%错误率所需的迭代次数。其中实线代表ReLU,虚线代表Tanh。下图表明如果使用传统的饱和激活函数不可能在大规模神经网络中利用。

2.2 多GPU并行训练
在该论文中采用2个NVIDIA GTX 580 GPU进行训练网络。单个NVIDIA GTX 580 GPU只有3GB的内存,这限制了可以在其上训练的网络的最大尺寸。在LSVRC2010数据集共有120万个训练样本。这120万个训练样例过于庞大,也无法放在一个GPU上的网络。因此,论文中将AlexNet网络分布在两个GPU上。当前的GPU特别适合跨GPU并行化,因为它们能够直接读取和写入彼此的内存,而无需通过主机内存实现并行化。
具体方案为:将一半内核(或神经元)放在每个GPU上,还有一个额外的技巧:GPU只在某些层中进行通信。这意味着,例如,第3层的内核从第2层中的所有内核映射获取输入。但是,第4层中的内核仅从位于同一GPU上的第3层中的那些内核映射获取输入。
2.3 局部响应归一化(LRN)
ReLU函数不需要对输入进行归一化来防止饱和。只要训练样本产生一个正输入给一个ReLU函数,那么在那个神经元中学习就会开始了。但是,论文中提出了局部响应归一化对神经元输入进行了改进。我们将坐标为
(
x
,
y
)
(x,y)
(x,y) 的像素在第
i
i
i 个核函数进行卷积操作之后,并利用ReLU函数的非线性进行激活的神经元记作
a
x
,
y
i
a_{x,y}^{i}
ax,yi ,
b
x
,
y
i
b_{x,y}^{i}
bx,yi 为
a
x
,
y
i
a_{x,y}^{i}
ax,yi 对应的局部响应标准化的神经元。
b
x
,
y
i
b_{x,y}^{i}
bx,yi 的计算公式如下:
b
x
,
y
i
=
a
x
,
y
i
/
[
k
+
α
∑
j
=
max
(
0
,
i
−
n
2
)
min
(
N
−
1
,
i
+
n
2
)
(
a
x
,
y
i
)
2
]
β
b_{x,y}^{i}={a_{x,y}^{i}}/{{{\left[ k+\alpha \sum\limits_{j=\max (0,i-\frac{n}{2})}^{\min (N-1,i+\frac{n}{2})}{{{(a_{x,y}^{i})}^{2}}} \right]}^{\beta }}}\;
bx,yi=ax,yi/⎣⎡k+αj=max(0,i−2n)∑min(N−1,i+2n)(ax,yi)2⎦⎤β
其中,
n
n
n代表与
a
x
,
y
i
a_{x,y}^{i}
ax,yi 在同一坐标上最近相邻核映射个数,
N
N
N为该层核函数的深度。
k
k
k,
α
\alpha
α,
β
\beta
β为超参数。Tensorflow中LRN的实现有两个接口:tf.nn.local_response_normalization和tf.nn.lrn。
k
k
k对应于函数中bias;
α
\alpha
α对应于函数中alpha;
n
2
\frac{n}{2}
2n对应于函数中deepth_radius;
β
\beta
β对应于函数中belta。
由于内核映射的顺序是任意的,在训练前就已经决定好了。那么这种局部响应归一化实现了横向抑制,使得根据利用不同核计算得到的神经元输出之间产生了竞争。原始输出较大的值变得更大,而较小的值变得更小即实现了抑制,在这样的机制下提高了模型泛化能力。
在AlexNet中,这项技术在卷积层1和卷积层2使用。其中参数设置全部一样:
k
=
2
,
n
=
5
,
α
=
10
−
4
,
β
=
0.75
k=2,n=5,\alpha ={{10}^{-4}},\beta =0.75
k=2,n=5,α=10−4,β=0.75
2.4 重叠池化
在CNN中,池化层总结了同一个核函数下相邻神经元的输出。传统的,相邻池化单元的总结不重叠。为了更精确,一个池化层可以被认为是由相邻 S S S 个像素的池化网格所组成,每个总结是池化单元中心的邻近 z × z z\times z z×z 个单元。如果我们假设 S = z S=z S=z ,我们获得CNN中传统的局部池化。如果设 S < z S<z S<z ,我们获得重叠池化。
三、AlexNet网络架构
为了更好地讲解卷积操作,我们首先的对卷积操作和图像尺寸之间的关系进行说明。假设图像维度为 W × W × L W\times W\times L W×W×L ,即图像由 L L L 个 W × W W\times W W×W 的二维矩阵构成。卷积内核维度为: F × F × L × K F\times F\times L\times K F×F×L×K ,即由 K K K 个 F × F × L F\times F\times L F×F×L三维矩阵构成。步长为 S S S,使用了 P P P 次全0填充。那么经过卷积操作后,内核映射的尺寸为: W − F − 2 P S + 1 \frac{W-F-2P}{S}+1 SW−F−2P+1 。
下来我们将逐层介绍AlexNet的网络架构。下图是AlexNet的整体架构图。
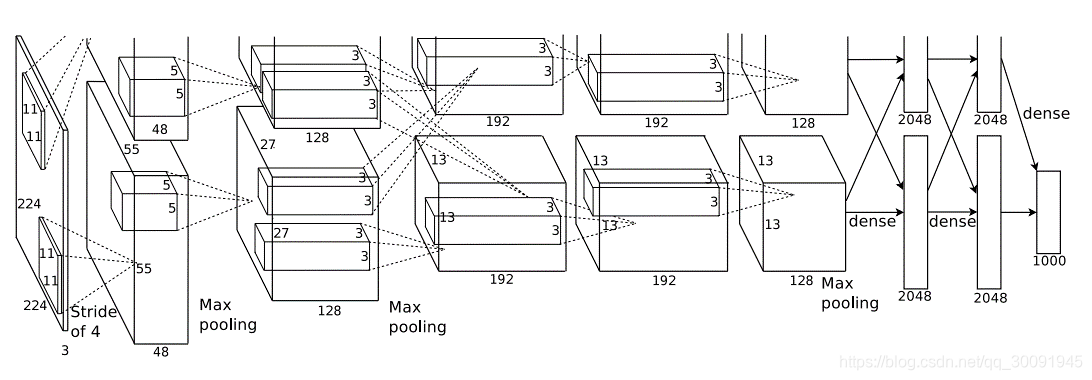
3.1 卷积层1(Conv1)
输入维度为: 224 × 224 × 3 224\times 224\times 3 224×224×3 ,即这也是ALexNet的输入的起点。内核维度为: 11 × 11 × 3 × 96 11\times 11\times 3\times 96 11×11×3×96 ,即由尺寸为11,3个通道的滤波器(掩膜、模板)与输入的原始图像进行卷积操作。步幅为4,即卷积核沿原始图像的 轴方向和 轴方向两个方向移动,移动的步长是4个像素。该层未做全0填充。注明:根据上述图中给出的AlexNet网络架构,卷积之后的结果维度为 55 × 55 × 96 55\times 55\times96 55×55×96 ,那么倒退回去输入图像维度应该为 227 × 227 × 3 227\times 227\times 3 227×227×3 ,那么我们必须视作输入图像输入到AlexNet之后进行了预处理,将原来的 224 × 224 × 3 224\times 224\times 3 224×224×3 扩展到了 227 × 227 × 3 227\times 227\times 3 227×227×3 。在下面的笔记中我们主要是以 为输入进行讲述。那么经过卷积操作之后的图像尺寸为: 227 − 11 4 + 1 = 55 \frac{227-11}{4}+1=55 4227−11+1=55 。那么卷积之后的图像维度为: 55 × 55 × 96 55\times 55\times 96 55×55×96 。之后这 55 × 55 × 96 55\times 55\times 96 55×55×96 的卷积结果被随机分成了两组,即2个 55 × 55 × 48 55\times 55\times 48 55×55×48 ,之后在2个GPU上分别利用ReLU非线性激活函数激活后送至最大池化层。Conv1紧跟着的最大池化层的内核维度为: 3 × 3 3\times 3 3×3 ,步幅为2,那么输入图像的尺寸为: 55 − 3 2 + 1 = 27 \frac{55-3}{2}+1=27 255−3+1=27 ,即输出结果为2个维度为 27 × 27 × 48 27\times 27\times 48 27×27×48 的图像,之后这个组图像进行合并为: 27 × 27 × 96 27\times 27\times 96 27×27×96 。该层还进行了局部响应归一化(LRN),之后进行最大池化层操作。
3.2 卷积层2(Conv2)
输入维度为:2个 (统一看成是 ) 27 × 27 × 48 27\times 27\times 48 27×27×48,卷积内核尺寸为:2个 (或者统一看成是 27 × 27 × 96 27\times 27\times 96 27×27×96)。步幅为1,在该层进行了全0填充,上下左右各填充2个像素。那么经历卷积操作之后的图像尺寸为: 27 − 5 + 2 × 2 1 + 1 = 27 \frac{27-5+2\times 2}{1}+1=27 127−5+2×2+1=27 ,即2块GPU上的图像输入经过卷积之后的图像维度均为: 27 × 27 × 128 27\times 27\times \text{128} 27×27×128 。然后将卷积之后的结果通过ReLU函数进行激活后送至最大池化层。其中,内核维度为: 3 × 3 \text{3}\times \text{3} 3×3 ,步幅为2。那么2块GPU上经过最大池化层得到的图像尺寸为: 27 − 3 2 +1=13 \frac{27-3}{2}\text{+1=13} 227−3+1=13 ,即图像维度为: 13 × 13 × 128 13\times 13\times 128 13×13×128。与Conv1层一样,也进行了LRN,之后进行最大池化层的操作。之后将2块GPU上的结果进行合并,那么图像维度为: 13 × 13 × 256 13\times 13\times 256 13×13×256 。
3.3 卷积层3(Conv3)
输入维度为: 13 × 13 × 256 13\times 13\times 256 13×13×256 ,卷积内核尺寸为: 3 × 3 × 256 × 384 3\times 3\times 256\times 384 3×3×256×384。步幅为1,在该层进行了全0填充,上下左右各填充1个像素。那么经历卷积操作之后的图像尺寸为: 13 − 3 + 2 × 1 1 + 1 = 13 \frac{13-3+2\times 1}{1}+1=13 113−3+2×1+1=13 ,图像输入经过卷积之后的图像维度为: 13 × 13 × 384 13\times 13\times 384 13×13×384 。然后将卷积之后的结果通过ReLU函数进行激活。
3.4 卷积层4(Conv4)
输入维度为: 13 × 13 × 384 13\times 13\times 384 13×13×384 ,卷积内核尺寸为: 3 × 3 × 384 × 384 3\times 3\times 384\times 384 3×3×384×384 。步幅为1,在该层进行了全0填充,上下左右各填充1个像素。那么经历卷积操作之后的图像尺寸为: 13 − 3 + 2 × 1 1 + 1 = 13 \frac{13-3+2\times 1}{1}+1=13 113−3+2×1+1=13 ,图像输入经过卷积之后的图像维度为: 13 × 13 × 384 13\times 13\times 384 13×13×384 。然后将卷积之后的结果通过ReLU函数进行激活,之后还进行了LRN。之后将处理得到的结果平分成2组送至2个GPU,即平分后的图像维度均为 13 × 13 × 192 13\times 13\times 192 13×13×192。
3.5 卷积层5(Conv5)
输入维度为:2个 13 × 13 × 192 13\times 13\times 192 13×13×192 ,卷积内核尺寸为:2个 3 × 3 × 192 × 128 3\times 3\times \text{192}\times \text{128} 3×3×192×128 。步幅为1,在该层进行了全0填充,上下左右各填充1个像素。那么经历卷积操作之后的图像尺寸为: 13 − 3 + 2 × 1 1 + 1 = 13 \frac{13-3+2\times 1}{1}+1=13 113−3+2×1+1=13 ,图像输入经过卷积之后的图像维度为:2个 13 × 13 × 128 13\times 13\times \text{128} 13×13×128。然后将卷积之后的结果通过ReLU函数进行激活。之后进入最大池化层操作,内核维度为: 3 × 3 \text{3}\times \text{3} 3×3 ,步幅为:2。那么经过最大池化图像尺寸为: 13 − 3 2 + 1 = 6 \frac{13-3}{2}+1=6 213−3+1=6 ,即该层图像维度为2个 6 × 6 × 128 \text{6}\times \text{6}\times \text{128} 6×6×128 ,并做了LRN。之后将2个GPU处理得到结果合并,即图像维度变成: 6 × 6 × 256 \text{6}\times \text{6}\times \text{256} 6×6×256。
3.6 全连接层1(FC1)
在此之后的网络结果可以看成是简单的前馈神经网络。其输入维度为: 6 × 6 × 256 6\times 6\times 256 6×6×256 ,为了进行前向传播,必须将输入图像矩阵拉成一维向量,即转化为: 1 × ( 6 ∗ 6 ∗ 256 ) = 1 × 9216 1\times (6*6*256)=1\times 9216 1×(6∗6∗256)=1×9216 。Conv5层与FC1层之间权重的维度为: 9216 × 4096 \text{9216}\times \text{4096} 9216×4096 ,偏置的维度为: 1 × 4096 1\times 4096 1×4096 。前行传播的结果的维度为: 。激活函数运用的是ReLU函数。同时将FC1和FC2两层之间的权重做了Dropout处理,概率为0.5。
3.7 全连接层2(FC2)
输入维度为: 1 × 4096 1\times 4096 1×4096 ,FC2层与FC3层之间权重的维度为: 4096 × 4096 \text{4096}\times \text{4096} 4096×4096 ,偏置的维度为: 1 × 4096 1\times 4096 1×4096 。前行传播的结果的维度为: 1 × 4096 1\times 4096 1×4096 。激活函数运用的是ReLU函数。同时将FC1和FC2两层之间的权重做了Dropout处理,概率为0.5。
3.8 全连接层3(FC3)
输入维度为: 1 × 4096 1\times 4096 1×4096 ,FC2层与FC3层之间权重的维度为: 4096 × 1000 \text{4096}\times \text{1000} 4096×1000 ,偏置的维度为: 1 × 1000 1\times 1000 1×1000 。前行传播的结果的维度为: 1 × 1000 1\times 1000 1×1000 。激活函数运用的是Softmax函数。得到的1000维向量代表了1000中分类对应的概率。
四、避免过拟合
首先来说一下,AlexNet用到的数据集——LSVRC2010。该数据集是ImageNet的子集。ImageNet数据集包含有大概22000种类别共150多万带标签的高分辨率图像。这些图像是从网络上收集得来,由亚马逊的Mechanical Turkey的众包工具进行人工标记。从2010年开始,作为Pascal视觉目标挑战的一部分,ImageNet大规模视觉识别挑战(ImageNet Large-Scale Visual Recognition Challenge ,ILSVRC)比赛每年都会举行。
ILSVRC采用ImageNet的子集,共包含一千个类别,每个类别包含大约1000幅图像。总的来说,大约有120万张训练图像,5万张验证图像以及15万张测试图像。ILSVRC-2010是ILSVRC唯一一个测试集标签公开的版本,因此这个版本就是本文大部分实验采用的数据集。ImageNet通常使用两种错误率:top-1和top-5,其中top-5错误率是指正确标签不在模型认为最有可能的前五个标签中的测试图像的百分数。
这个数据集图像分辨率为 224 × 224 224\times224 224×224 。论文中对图像的处理为:图像本身减去训练集的均值图像(训练集和测试集都减去训练集的均值图像)。因此论文直接在每个像素的原始RGB值上进行训练。
4.1 数据扩展
降低图像数据过拟合的最简单常见的方法就是利用标签转换人为地增大数据集。本文采取两种不同的数据增强方式,这两种方式只需要少量的计算就可以从原图中产生转换图像,因此转换图像不需要存入磁盘。本文中利用GPU训练先前一批图像的同时,使用CPU运行Python代码生成转换图像。因此这些数据增强方法实际上是不用消耗计算资源的。
第一种数据增强的形式包括生成平移图像和水平翻转图像。做法就是从$256\times 256$的图像中提取随机的 224 × 224 224\times 224 224×224大小的块(以及它们的水平翻转),然后基于这些提取的块训练网络。这个让我们的训练集增大了2048倍 ( 256 − 224 ) 2 × 2 = 2028 ) {{(256-224)}^{2}}\times 2=2028) (256−224)2×2=2028),尽管产生的这些训练样本显然是高度相互依赖的。在测试时,网络通过提取5个$224\times 224$块(四个边角块和一个中心块)以及它们的水平翻转(因此共十个块)做预测,然后网络的softmax层对这十个块做出的预测取均值。
第二种数据增强的形式包括改变训练图像的RGB通道的强度。特别的,本文对整个ImageNet训练集的RGB像素值进行了PCA。对每一幅训练图像,本文加上多倍的主成分,倍数的值为相应的特征值乘以一个均值为0标准差为0.1的高斯函数产生的随机变量。因此对每一个RGB图像像素 I x y = [ I x y R , I x y G , I x y B ] T {{I}_{xy}}={{\left[ I_{xy}^{R},I_{xy}^{G},I_{xy}^{B} \right]}^{T}} Ixy=[IxyR,IxyG,IxyB]T 都将上了 [ p 1 , p 2 , p 2 ] [ α 1 λ 1 , α 2 λ 2 , α 3 λ 3 ] T \left[ {{p}_{1}},{{p}_{2}},{{p}_{2}} \right]{{\left[ {{\alpha }_{1}}{{\lambda }_{1}},{{\alpha }_{2}}{{\lambda }_{2}},{{\alpha }_{3}}{{\lambda }_{3}} \right]}^{T}} [p1,p2,p2][α1λ1,α2λ2,α3λ3]T
这里 p i {{p}_{i}} pi 和 λ i {{\lambda }_{i}} λi 是RGB像素值的 3 × 3 3\times 3 3×3 协方差矩阵的第 i i i个特征向量和特征值, α i {{\alpha }_{i}} αi是上述的随机变量。每一个 α i {{\alpha }_{i}} αi的值对一幅特定的训练图像的所有像素是不变的,直到这幅图像再次用于训练,此时才又赋予 α i {{\alpha }_{i}} αi新的值。这个方案得到了自然图像的一个重要的性质,也就是,改变光照的颜色和强度,目标的特性是不变的。
4.2 Dropout
dropout它将每一个隐藏神经元的输出以0.5概率设为0。以这种方式被“踢出”的神经元不会参加前向传递,也不会加入反向传播。因此每次有输入时,神经网络采样一个不同的结构,但是所有这些结构都共享权值。这个技术降低了神经元之间复杂的联合适应性,因为一个神经元不是依赖于另一个特定的神经元的存在的。因此迫使要学到在连接其他神经元的多个不同随机子集的时候更鲁棒性的特征。在测试时,本文使用所有的神经元,但对其输出都乘以了0.5。
五、训练细节
训练过程中,使用SGD进行优化模型参数,小样本规模为128,动量因子为0.9,权重衰减(L2正则化)系数为0.0005。论文发现这个很小的权值衰减对模型的学习很重要。换句话说,这里的权值衰减不只是一个正则化矩阵:它降低了模型的训练错误率。权重 更新规则是:
v
i
+
1
=
0.9
v
i
-
0.0005
ε
w
i
−
ε
⟨
∂
L
∂
w
∣
w
i
⟩
D
i
w
i
+
1
=
w
i
+
v
i
+
1
\begin{aligned} & {{v}_{i+1}}=0.9{{v}_{i}}\text{-}0.0005\varepsilon {{w}_{i}}-\varepsilon {{\left\langle \frac{\partial L}{\partial w}{{\text{ }\!\!|\!\!\text{ }}_{{{w}_{i}}}} \right\rangle }_{{{D}_{i}}}} \\ & {{w}_{i+1}}={{w}_{i}}+{{v}_{i+1}} \\ \end{aligned}
vi+1=0.9vi-0.0005εwi−ε⟨∂w∂L ∣ wi⟩Diwi+1=wi+vi+1
其中, i i i为迭代次数, v v v 为动量变量, $\varepsilon $为学习率。 ⟨ ∂ L ∂ w ∣ w i ⟩ D i {{\left\langle \frac{\partial L}{\partial w}{{\text{ }\!\!|\!\!\text{ }}_{{{w}_{i}}}} \right\rangle }_{{{D}_{i}}}} ⟨∂w∂L ∣ wi⟩Di是第 i i i的小样本 D i {{D}_{i}} Di上,损失函数 L L L对变量 w w w 平均梯度。
对于权重,整个AlexNet中所有权重全部设置成均值为0,标准差为0.01的高斯分布随机数。对于偏置,第2、4和5卷积层和全连接层的偏置初始化为1.0,其余层的偏置初始化为0。学习率使用固定学习率0.01,当验证误差停止降低时,学习率除以10。


















 1833
1833

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











