







pos-1.txt
89,111,226,252,263,544,552,553,557,1264,1284,1889,1953,1960,2432,2433,4138,4648,4655,4663,5980,10010,10315,10576,10843,11994,12096,12165,12332,12341,12342,12343,12521,12532,12793,12795,12796,13124,14197,14214,14227,14893,15176,17166,18136,18442,18575,18649,18789,18790
1.read()
import os
text_file = open("H:/data/CRC/train/分类结果/1/pos-1.txt", "r")
read_1 = text_file.read()
print("current is type of read_1:{}".format(type(read_1)))
print("current is read_1:{}".format(read_1))
print("current is read_1[0]:{}".format(read_1[0]))
read_split= read_1.split(",")
print("current is type of li:{}".format(type(read_split)))
print("current is read_split:{}".format(read_split))
print("current is read_split[0]:{}".format(read_split[0]))
read()是读取整个文件,将其放到一个字符串里面,是一个字符串类型。如果文件比较大的话,用read()将会比较吃力。

2.readline()
readline() 是读取文件中的一行,读完这一行之后会自动指向下一行,返回的是一个字符串类型。
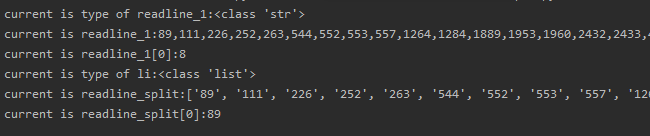
import os
text_file = open("H:/data/CRC/train/分类结果/1/pos-1.txt", "r")
readline_1 = text_file.readline()
print("current is type of readline_1:{}".format(type(readline_1)))
print("current is readline_1:{}".format(readline_1))
print("current is readline_1[0]:{}".format(readline_1[0]))
readline_split= readline_1.split(",")
print("current is type of li:{}".format(type(readline_split)))
print("current is readline_split:{}".format(readline_split))
print("current is readline_split[0]:{}".format(readline_split[0]))
结果:
readlines()
readlines()是一次性读取整个文件,自动将文件内容分析成一个列表(list)
import os
text_file = open("H:/data/CRC/train/分类结果/1/pos-1.txt", "r")
readlines_1 = text_file.readlines()
print("current is type of readlines_1:{}".format(type(readlines_1)))
print("current is readlines_1:{}".format(readlines_1))
print("current is readlines_1[0]:{}".format(readlines_1[0]))
















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









