









摘要
与前列腺癌和乳腺癌等常见癌症不同,罕见癌症的肿瘤分级很困难,而且很大程度上是不确定的,因为样本量小,承担这样的任务需要大量的时间和经验,而且提取人类观察到的模式本身就很困难。最具挑战性的例子之一是肝内胆管癌(ICC),这是一种起源于胆道系统的原发性肝癌,其肿瘤异质性是公认的,并且没有分级范例或预后生物标志物。本文提出了一种新的基于无监督深卷积自动编码器的聚类模型,该模型基于视觉相似性将246张数字化整张幻灯片中的肿瘤细胞形态和结构形态组合在一起。基于这种组织学模式的视觉字典的群集被解释为新的ICC亚型,并通过训练Cox比例风险生存模型进行评估,从而导致统计上显著的患者分层
简介
肿瘤亚型是判断疾病预后和指导治疗的重要工具。常见的癌症,如乳腺癌和前列腺癌,都有确定的亚型,并在大样本大小上得到验证[4]。通过识别不同的组织学模式,并利用它们将患者分成不同的风险组,对癌症进行亚型所需的体力劳动是一项极其复杂的任务,需要多年的努力和对大量视觉数据的重复审查,通常由一名病理学家进行。
一种罕见的癌症的亚型构成了一系列独特的挑战。肝内胆管癌(ICC)是一种起源于胆管的原发性肝癌,在美国的发病率约为每16万人中就有1例,而且还在上升[14]。目前,还没有普遍接受的基于组织病理学的ICC亚型或分级系统,将ICC分为不同风险组的研究也不一致[1,12,15]。ICC分型的一个主要限制因素是,每个机构只有少量的队列可用。迫切需要从有限的罕见癌症(如ICC)的组织学数据集中有效地识别与预后相关的细胞和结构形态学,以建立目前许多癌症类型都缺乏的风险分层系统
计算病理学提供了一套新的工具,更重要的是,提供了一种使用基于计算机视觉的深度学习、利用病理切片的数字化以及利用计算处理能力的最新进展来应对癌症亚型的历史挑战的新方法。本文提出了一种新的基于深度学习的模型,该模型使用一种独特的基于神经网络的聚类方法对基于视觉相似性的组织学进行分组。利用这一视觉词典,我们将簇解释为亚型,并训练生存模型,首次在ICC中显示了显著的结果。
2 材料和方法
癌症组织病理学图像由于其大小(大到数百亿像素)表现出很高的内部和内部异质性。肿瘤的不同空间或时间采样可以有具有独特基因组的细胞亚群,理论上导致不同的组织学模式[3]。为了有效地将这些极大量的高方差数据聚类成基于相似形态的子集,我们提出将基于神经网络的聚类代价函数与一种新的深卷积结构相结合,该代价函数在手写数字图像上的性能优于传统的聚类技术[16]。我们假设,在图像重建的约束下,由滤波器的自适应学习驱动的k-均值类型的聚类代价函数将产生与患者预后相关的组织病理学聚类。最后,我们通过进行生存分析,使用Cox比例风险模型和Kaplan-Meier生存估计来评估这种聚类模型的性能和实用性,以衡量每一类组织形态是否与肿瘤切除术后复发有显著相关性。虽然其他研究已经基于图像特征对整个幻灯片进行了非监督聚类,但是它们已经被用于解决图像分割问题[11],并且依赖于对发展的潜在空间进行聚类[7,8]。我们的研究随着聚类的每一次迭代而调整潜在空间。
2.1深度聚类卷积自动编码器
卷积自动编码器由编码器和解码器两部分组成。编码层将图像投影到低维表示中,通过一系列卷积、合并和激活函数进行嵌入。这在公式1a中描述,其中xi是通过fθ()变换的输入图像或输入图像批次,而zi是结果表示嵌入。解码器层尝试使用类似的函数从嵌入的原始输入图像重建原始输入图像。均方误差损失通常用于优化这样的模型,更新相对于原始(输入,Xi)图像和重建(输出,x?)之间的误差的模型权重(θ)。i)N个图像集合中的图像。这如等式1b所示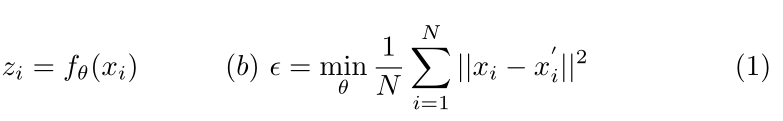
虽然卷积自动编码器可以学习一组图像的有效低维表示,但它不会将具有相似形态的样本聚集在一起。为了克服这一问题,我们利用由Song等人首次提出的重构聚类误差函数对传统的均方误差损失函数进行了修正。
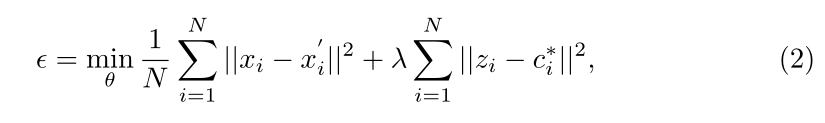
其中zi是公式1a中定义的嵌入,c∗i是从前一个训练时期分配给样本xi的质心,而λ是加权参数。通过找出嵌入自历元t的样本和从历元t−1跨越j个质心的质心之间的最短欧几里德距离来确定聚类分配。
该算法通过向每个样本分配随机簇来初始化。按公式4计算每个簇类的质心位置。每个小批量通过模型转发,并分别更新网络权重。在由所有小批次的前向传递定义的历元结束时,给定新的嵌入空间,簇分配由公式3更新。最后,根据新的群集分配更新质心位置。重复此过程,直到收敛。图1显示了此训练过程的可视化。
数据集
完整的幻灯片图像是从纪念斯隆·凯特林癌症中心(MSK)和伊拉斯谟医学中心获得的,并得到了各自机构审查委员会的批准。总共有246名没有接受新辅助化疗的切除ICC的患者被纳入分析。
在MSK使用Aperio AT2扫描仪(徕卡生物系统公司;德国Wetzlar)。同时也获得了手术后无复发存活率的最新回顾性数据。虽然目前与常见癌症相比样本量较小,但这一收集是世界上已知的最大的ICC数据集。
从所有数字化幻灯片中生成提取的图像平铺库。首先,将每张幻灯片缩小为一个缩略图,其中缩略图中的一个像素表示幻灯片中的224×224px平铺,放大倍数为20倍。接下来,在缩略图上使用Otsu阈值,生成组织(正)与背景(负)的二进制掩模。组织中10个缩略图像素以下的连接部分被认为是背景,以排除数字化幻灯片中的灰尘或其他无关紧要的肿块。最后,利用数学形态学对组织蒙版进行一个缩略图像素的侵蚀,最小化带有部分背景的瓷砖。为了将癌症亚型问题从肿瘤分割问题中分离出来,使用基于Web的整个幻灯片查看器对肿瘤区域进行了手动标注。使用触摸屏(Surface Pro 3,Surface Studio;微软公司,雷蒙德,华盛顿州,美国),病理学家在肿瘤区域上绘制,以确定应该在哪里提取瓷砖。如果瓷砖完全位于已识别肿瘤的这些区域内,则将其添加到训练集中。
质量控制。扫描伪像(如图像的焦外区域)可能会影响较小数据集上的模型性能。训练一个深度卷积神经网络来检测模糊瓷砖,以进一步降低数据集中的噪声。在真实的模糊数据上训练检测器超出了本研究的范围,因为获取幻灯片中模糊区域的注释是不可行的,并且还会在模糊和锐化瓷砖之间造成强烈的类别不平衡。为了准备训练模糊检测器的数据,我们使用了一种与[6]中描述的方法类似的方法:首先,通过应用随机半径从1到10的高斯模糊来人工模糊一半的瓷砖,另一半贴上“锐化”的标签,并且不对其进行任何改变。ResNet18被训练成通过使用MSE回归所应用的滤波器半径值来输出图像质量分数。值0用于夏普类中的图像。最后,根据检测器的输出值手动选择阈值以排除模糊的瓷砖。
2.3架构和培训
我们提出了一种新的卷积自动编码器结构来优化图像重建的性能。编码器是在ImageNet[13]上预先训练的ResNet18[9]。在病理数据上训练完整模型时,编码器所有层的参数都更新了。解码器由五个卷积层组成,每个卷积层的填充和步长均为1,用于在每次卷积运算时保持张量大小恒定。在每个卷积步骤之前使用上采样以增加特征地图的大小。根据经验,批归一化图层不会提高重建性能,因此被排除在外
模型的两个属性需要优化:首先,网络的权重θ,然后是嵌入空间Cj中聚类中心或质心的位置。为了将等式2最小化并更新θ,之前的培训使用EPOCH的质心组Ct−1j。在第一训练时段的情况下,质心位置在初始化时被随机分配。训练时期由所有小批次通过网络的一次前向传递来定义。在更新θ之后,使用公式3将所有样本重新分配到最近的质心。最后,在下一个训练时段的计算中使用公式4a n u s e d来更新所有质心位置。图1说明了此过程和体系结构
为了节省计算时间,从完整的图片库中随机抽样100,000个图块来训练每个模型,平均每张幻灯片产生大约400个图块。下节分别描述了超参数λ和J、聚类权重和簇数的选择过程。
实验。Calinski-Harabaz指数(CHI)[5],也称为方差比标准,被用来衡量集群性能,其定义是通过测量集群间分散平均和集群内分散的比率来定义的。较高的CHI表示较强的聚类分离和较低的每个聚类内的方差。
进行了一系列实验,以优化λ和J进行模型选择。将λ设置为0.2时,使用从5到25的不同J群集对5个不同的模型进行训练。其次,用不同的λ训练5个模型,f_r_o_m为0。2到1,其中J设置为与前一实验中的最高CHI相对应的值。使用优化的J和λ对最终模型进行训练,对数据集中的所有瓷砖进行聚类。每张幻灯片都被分配了一个类,根据哪个簇被测量为占据幻灯片中最大的区域。之所以使用这种方法,是因为它类似于病理学家根据最常见的组织学模式将癌症分类为亚型的方式
**生存建模。**为了衡量聚类形态学模式的有用性和有效性,我们根据分配给相关结果数据的类别进行了幻灯片级别的生存分析。生存数据通常包括右审查的持续时间。这意味着一些患者不知道感兴趣的事件发生的时间,在我们的病例中,放射学检测到的复发时间是未知的。然而,测量到患者最后一次随访日期的无复发持续时间仍然是有用的信息,可以用于建模。Cox比例风险建模是处理右删失数据的常用模型:
其中H(T)是依赖于时间t的危险函数,Ho是基线危险,协变量Xi由系数bi加权。危险比,或死亡的相对可能性,由EBJ定义。风险比大于1表示群集类别导致较差的预后。相反,风险比小于1有助于良好的预后因素。为了衡量生存模型中的重要性,每个模型都给出了基于Wald统计量、似然比和对数秩检验的p值。
训练了五个单变量Cox模型,每个模型都有一个聚类类别作为参考,以衡量相对于其他类别的生存影响。此外,通过估计生存函数S(T),我们展示了Kaplan-Meier曲线来说明每一类内的生存结果:

其中dir是在时间t的复发事件的数量,nii是在时间t之前有死亡或复发风险的受试者的数量。
3 结果
通过改变λ和J进行模型选择的结果如表1所示。最佳性能由CHI测量,λ设置为0.2时,J设置为5时。
当根据无监督模型产生的聚类对患者的组织进行分类时,Cox比例风险模型在患者之间的复发生存率中显示出很强的意义。表2详细说明了在五个不同模型中,每个群集相对于其他群集的风险比率。每个模型都有一个簇作为参考,以产生危险比。图2显示了使用Kaplan-Meier分析的生存模型的可视化。
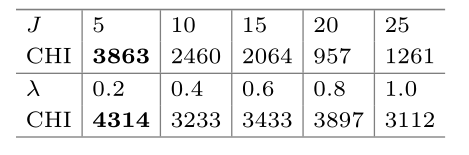
表1.当模型设置为5个聚类(J)并且聚类权重(λ)设置为0.2时,Calinski-Harabaz指数(CHI)最高。这表明哪个模型最能产生密集且彼此分离良好的聚类。

表2.通过三种不同的统计测试测量的危险比率显示出很强的显著性。这表明由无监督模型产生的聚类类别具有临床实用性。如果每个聚类都被认为是一个癌症亚型,那么五个亚型是迄今为止文献中看到的最强的分层。

图2.Kaplan-Meier可视化每个患者的生存概率,这些患者被归入由无监督模型产生的五个聚类类别中的一个。组3中组织高度存在的患者比组2或4组的患者有更好的无复发生存率。
4结论
我们的模型提供了一种新的方法来识别具有潜在预后意义的组织学模式,避免了繁琐的组织标记和费力的人类对多张整张幻灯片的评估任务。作为一个比较点,最近的一项研究表明,通过使用监督学习首先将幻灯片分割成八个预定义的分类区域,可以获得结直肠癌的有效预后评分[10]。这类模型将模型限制为预定义的组织成分(肿瘤、脂肪、碎片等)。而且该方案可能不会扩展到缺乏类似肿瘤特异性间质相互作用的结肠外解剖部位[2]。相反,我们的模型设计缺乏预先定义的组织类别,并且能够分析任意数量的聚类,从而消除了训练带来的潜在偏差,增加了模型应用的灵活性。我们真心希望像这样的新的亚型方法能带来更好的胆管癌分级,并改善患者的治疗和预后。















 4611
4611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









