







前言
目前使用最广泛的one-shot learning的方法是,先学习一个深度embedding函数,然后再定义一个简单的分类规则,比如在embedding空间中进行最近邻操作。但是,计算embedding和学习适用于新目标的模型还是相去甚远。
本文提出了一种与众不同的方法,仅从一个单一的样本,就能得到一个完整的深度判别模型来识别与该样本属于同一类别的其它目标。而且本文提出的方法并不需要一个冗长的优化过程,而是能够进行实时、高效和一次性的计算。本文的方法就是学习一个深度神经网络,称为learnet,具体来说就是,给定一个新类的样本,预测第二个网络的参数,该网络可以识别属于该新类的其它目标。
本文的模型有以下几个值得关注的地方:
- 如果把学习看作是将一组图像映射到模型参数的过程,那么这可以看作是learning to learn方法。显然,只有在给定充分的先验知识的情况下,才能从一个单一样本中学习。通过处理数百万个one-shot learning任务和端到端的向后传播误差,将这些先验知识在一个off-line阶段整合到learnet中。
- learnet模型提供了一个前馈学习算法,它可以从可用的样本中一次性提取出最终模型的参数,它也证明了深度学习网络能够以元学习的方式预测第二个网络的参数。
- 本文的方法以一种高效、实用的方式来进行one-shot learning
方法实现
由于本文将one-shot learning视为判别任务,因此首先从标准的判别学习开始:在有 n n n个样本 x i x_i xi及其对应标签 l i l_i li的数据集上计算一个预测函数: φ ( x ; W ) \varphi (x;W) φ(x;W),需要找到参数矩阵 W W W使得该函数的平均损失 L L L最小:

当从一个类别的单一样本 z z z中学习 W W W时,也就是所谓的one-shot learning,需要将先验知识融入到学习过程中,也就是learning to learn,这是one-shot learning所面对的主要的挑战;除此之外,还要避免如式(1)中冗余的优化过程,这对于one-shot learning的实际应用是非常重要的。
为了解决上面说到的两个问题,本文使用元预测(meta-prediction)过程从单个样本 z z z中学习参数矩阵 W W W,也即用一个无迭代的前馈函数 ω \omega ω将 ( z ; W ′ ) (z;W^{'}) (z;W′)映射到 W W W,称这个函数为learnet,learnet取决于样本 z z z, z z z就是某个新类中的唯一一个样本,它有一个参数矩阵 W ′ W^{'} W′。那么learning to learn问题现在就可以被转换成使用目标函数(objective function)来优化learnet的元参数(meta-parameter) W ′ W^{'} W′,在这种方式下,larnet前馈网络的速度远大于式(1)中求解优化问题的速度。为了训练learnet,要求能在给定任意样本 z z z的情况下生成良好的预测,最终的结果是在 n n n个样本 z i z_i zi上的平均结果:
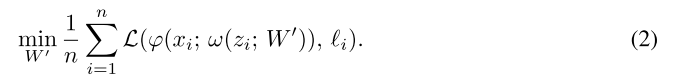
在上式中,用一个验证对儿 ( x i , l i ) (x_i,l_i) (xi,li)来评估learnet从 z i z_i zi中提取的预测的性能,训练数据由三元组 ( x i , z i , l i ) (x_i,z_i,l_i) (xi,z
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1437
1437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









