







文章目录
1.背景
目前Transformers及其衍生的各种模型(包括Bert,Roberta等)在NLP领域上大放异彩。不仅仅在NLP领域上,在CTR预估上,这些模型能够有效针对画像特征进行分类,从而有效学习高阶交互特征,提升CTR预估效果。同时CTR预估往往存在文本信息,因此也可以使用Transformers等模型来挖掘词语之前的关系。
CTR预估:旨在预测用户是否会点击所推荐的广告和商品,它通常会运用到在线广告和推荐系统中。
2.相关论文解析
2.1 《AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks》
论文指出,目前CTR预估中,存在两个问题:
- 输入的数据,比如用户数据和商品数据,这些都是高纬度和稀疏的特征,容易造成过拟合
- 有效的预估中,需要进行特征交叉。这其中又会涉及到大量的人工标记评估时间
因此本论文提出了新的模型AutoInt用来学习高阶的输入特征,用来解决稀疏且高纬度的输入特征。
同时这个模型能够同时处理数字型(numerical)和分类型(categorical)的特征。
2.1.1 论文贡献
论文中贡献有如下几点:
- 论文的模型能够进行显示学习高阶特征,同时能够找到很好的解释方法(其实也就是用了attention机制来解释)
- 提出了一个基于self-attention神经网络,它能够自动学习高阶特征,同时有效解决高纬度的稀疏数据问题
- 实验中展示出论文中提出模型达到了SOTA,且有更好的可解释性
2.1.2 模型结构

整体模型比较简单,在输入部分同时输入了one-hot特征和numerical特征。然后经过了整个multi-head self-attention结构,最后进行模型预测。
2.1.2.1 输入
创新点在于输入部分是结合了两种不同的特征,一种是one-hot vector;另一种是numerical数值特征。
(1)one-hot vector
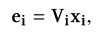
普通的embedding特征,其中
V
i
V_i
Vi代表向量化矩阵。把对应的one-hot特征向量化后,取平均值得到下面的公式:
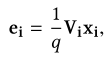
(2)numerical数值特征
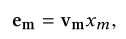
其中
x
m
x_m
xm为特征真实值,
v
m
v_m
vm为对应该特征的随机vector。也即是说,首先模型会随机向量化一个矩阵,同时这个矩阵有
M
M
M个维度,对应的是
M
M
M个特征。因此只需要把对应的数值特征与对应位置的vector相乘,就可以有效表征该特征。
2.1.2.2 注意力机制层
这里面的注意力机制层主要用到了transformers中的multi-head attention。同时在attention的输入和输出端引入残差结构。

特征
m
m
m和特征
k
k
k会有一个映射关系,相当于FM模型中的交叉特征,其中
h
h
h为multi-head中的head的数量:
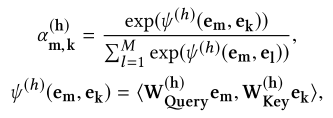
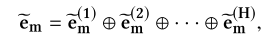
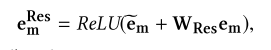
论文中提到这个是具有可解释性的:
-
假设开始输入四个特征值 x 1 , x 2 , x 3 , x 4 x_1,x_2,x_3,x_4 x1,x2,x3,x4,那么它们的二阶交叉特征为 g ( x 1 , x 2 ) , g ( x 2 , x 3 ) , g ( x 3 , x 4 ) g(x_1,x_2),g(x_2,x_3),g(x_3,x_4) g(x1,x2),g(x2,x3),g(x3,x4)。这四个二阶交叉特征恰好可以通过上面的attention公式计算出来,也即是他们对应的注意力权重 α \alpha α
-
给定一阶交叉特征值为 e 1 R e s e^{Res}_1 e1Res和三阶交叉特征 e 3 R e s e^{Res}_3 e3Res。则 e 3 R e s e^{Res}_3 e3Res可以由 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3生成,这是因为有 g ( x 1 , x 2 ) g(x_1,x_2) g(x1,x2)和残差连接 x 3 x_3 x3可以生成的
-
因此可以推导,越高阶的特征,可以由低阶生成
2.1.3 实验结果
实验中使用了四个数据集,由三个拿到了SOTA:

在可解释性方面,画了attention权重可视化:

其中可以看到左图中颜色较深的是两个特征有关系的:<Gender=Male,Age=[18-24),MovieGenre=Action&Triller>,这个说明年轻人比较喜欢Action&Triller电影,符合常识。
2.2 《Behavior Sequence Transformer for E-commerce Recommendation in Alibaba》
2.2.1 论文贡献
以前的工作采用的是embedding和MLP(普通的全量连接层),原始的特征会直接映射成低纬度vectors,然后利用MLP作为最后的预测层。但是以前的这种方法没有考虑到用户的行为序列,仅仅是把原有的特征进行拼接。
本论文的贡献是:
- 利用Transformer模型来捕捉底层用户行为的信号
- 实验结果证明新提出的模型在CTR预估上有重大的提升
2.2.2 引入
在推荐系统中(RSs),会分为两个部分:match(匹配)和rank(排序)。在匹配中,根据商品和用户的交互来选择相似的物品,然后利用精细化的预估模型来预测用户对该商品的点击概率。
本论文主要集中在排序阶段,预测用户点击候选商品的概率。利用Transformer模型,同时引入用户的一系列行为,来提升CTR预估的效果。论文中提出的模型称为behavior sequence transformer(BST)。
2.2.3 模型

在排序阶段,构建了一个推荐任务:CTR任务。任务的描述如下,用户 u u u的行为序列 S ( u ) = { v 1 , v 2 , . . . , v n } S(u)=\{v_1,v_2,...,v_n\} S(u)={v1,v2,...,vn},学习的函数为 F F F,来预测用户 u u u对目标商品 v t v_t vt的点击概率。
以前点击items和相关的特征被直接嵌入到底层的向量当中。本论文最大的不同在于,BST主要利用了transformer层来学习内在的用户点击信号。
(1)Embedding Layer
首先把所有的输入特征嵌入到低纬度的向量中。
- Other Features不经过Transformer,直接构成一个向量化矩阵
W
0
W_0
W0。下面是Other Features的表格:

- Sequence Item和Positional Features则需要经过Transformer层。其中Sequence Item主要是由商品ID和类别ID进行输入。
- Positional embedding(位置向量),用下面公式构建:
p o s ( v i ) = t ( v t ) − t ( v i ) pos(v_i)=t(v_t)-t(v_i) pos(vi)=t(vt)−t(vi)
其中 v t v_t vt代表该商品的推荐时间, v i v_i vi代表用户点击时间
2.2.4 实验结果

从实验结果上看,BST在离线和在线任务中都取得了最好的结果
2.3 《Deep Multifaceted Transformers for Multi-objective Ranking in Large-Scale E-commerce Recommender Systems》
2.3.1 论文贡献
以前的CTR模型仅仅集中在历史的点击序列中,但没有关注用户的多种行为。因此本论文提出了模型Deep Multifaceted Transformers (DMT)来考虑用户的多种行为,并应用多任务学习方法来训练模型。论文的主要贡献如下:
- 多任务学习方法:同时使用CTR(点击率)和Conversion Rate (CVR,转化率)来训练模型
- 引入用户的多种不同行为:用户有很多不同的行为,比如:点击、添加商品到购物车,排序。
- 引入偏差隐藏反馈(bias):
(1)位置偏差:一个用户会点击一个商品仅仅是因为它排名比较高,这种现象称为“位置偏差”
(2)邻居偏差:用户偏向于点击目标商品的附近商品
2.3.2 引入
推荐系统旨在把前在的商品进行推荐,同时解决信息暴露问题,在电子商务中有重要的作用。推荐系统往往包括两个部分:候选生成、排序。论文中主要关注的是排序阶段,用来提升用户的满意度和网站的收入。
在多目标学习中,论文中使用了Multi-gate Mixture-of-Experts (MMoE)。
为了考虑偏差问题,论文中提出的模型DMT使用了偏差网络来估计倾向分数。
2.3.3 模型

2.3.3.1 Input Layer和Embedding Layer
电子商务系统中,分类特征是比较有用的。给定用户 u u u,该用户的行为序列为 S = < x 1 , x 2 , . . . , x T > S=<x_1,x_2,...,x_T> S=<x1,x2,...,xT>。其中 x i = ( t i , p i ) x_i=(t_i,p_i) xi=(ti,pi)表明该用户在 t i t_i ti时刻上在商品 p i p_i pi上的行为。论文中分为三种不同的行为:点击行为(click)、添加到购物车的行为(cart)、排序行为(order)。
在Embedding Layer中,对每个商品的特征进行向量化,得到dense vectors e i e_i ei。
在模型的左边有一个dense layer,它主要分为三个不同的类型:
- 商品特征:点击数量,转化率等
- 用户特征:购买力,首选类别和品牌
- 用户-商品特征:商品是否符合用户的年龄和性别
2.3.3.2 Deep Multifaceted Transformers Layer
这部分主要用到的是Transformer模型。
论文中,对于每个用户,1)点击序列取在近7天中最近的50个商品;2)添加购物车和排序取近1年中的10个行为。
在Transformer中,encoder输入的是商品序列,encoder输入的是目标商品,用来学习用户的兴趣向量来映射目标商品。通过多层self-attention进行叠加,可以学习到用户的隐藏信息。
2.3.3.3 Multi-gate Mixture-of-Experts Layers(MMoE)
主要用来进行多目标任务学习。
单独拿出这一部分进行分析:

- MMoE有一组bottom networks, 每一个叫做一个expert, 在本文中, expert network是一个feed-forward network
然后为每个任务引入一个gating network。Gating networks 的输入是input features, 输出是softmax gates,即各个expert的权重 - 加权之后的expert结果被输入下一层网络中
- 这样的话,不同任务的gating networks能够学到不同的专家混合方式,以此捕捉到任务之间的关系
- MMoE更容易训练并且能够收敛到一个更好的loss,因为近来有研究发现modulation和gating机制能够提升训练非凸深度神经网络的可训练性。
- 在这篇论文中因为学习的是两个目标,所以用到两个expert网络和两个gate网络
具体看公式:
w
k
=
s
o
f
t
m
a
x
(
N
N
G
k
(
x
)
)
f
k
(
x
)
=
∑
i
=
1
N
w
i
k
e
i
(
x
)
u
k
=
N
N
U
k
(
f
k
(
x
)
)
w^k=softmax(NN_G^k(x)) \\ f^k(x)=\sum_{i=1}^{N}w_i^ke_i(x) \\ u_k=NN_U^k(f^k(x))
wk=softmax(NNGk(x))fk(x)=i=1∑Nwikei(x)uk=NNUk(fk(x))
gate网络输出 N N G k ( x ) NN_G^k(x) NNGk(x),然后经过sotmax得到权重 w k w^k wk。这个权重 w k w^k wk与expert网络的 e i ( x ) e_i(x) ei(x)进行生成,得到 f k ( x ) f^k(x) fk(x).最后再经过utility网络得到 u k u_k uk。
2.3.3.4 Bias Deep Neural Network
论文中主要处理Position bias(位置偏差)和Neighboring bias(邻居偏差)。
- Position bias(位置偏差):排名较高得会倾向于点击。记录目标商品的位置
- Neighboring bias(邻居偏差):在目标商品附近,也会倾向于点击。记录目标商品最近的K个商品
y b = N N B ( x b ) y_b=NN_B(x_b) yb=NNB(xb)
2.3.3.5 训练和预测
在训练阶段,需要加上偏差
y
b
y_b
yb:
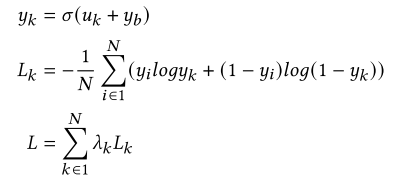
预测阶段则不需要偏差。
2.3.4 实验结果
(1)baseline对比

(2)不同模块之间的对比

加入排序的操作序列,不会有太高的提升。经验来说:对于具有较长回购期的产品(例如计算机),用户倾向于在购买产品后的短时间内单击但不再次购买该产品。 对于回购期较短的产品(例如牛奶),用户可以在短时间内单击并再次购买。 订单序列可能会导致点击预测和订单预测之间发生冲突,并干扰点击或购物车序列中的信息。
(3)不同expert的影响

点击预测任务对expert1和expert4影响较大。
排序预测任务对expert1、3、4影响较大
















 1230
1230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











