






目录
各位兄弟姐妹们国庆节快乐!!
机器学习是一种人工智能(AI)分支领域,它致力于开发算法和模型,让计算机能够从数据中学习和改进性能,而无需显式地进行编程。机器学习的主要目标是让计算机能够根据过去的经验来做出决策或预测未来的事件,而不需要硬编码的规则。
K近邻算法(K-Nearest Neighbors,简称KNN)是一种用于分类和回归问题的机器学习算法。它属于监督学习的范畴,可用于模式识别、数据挖掘和预测分析等任务。KNN的基本思想非常简单:对于一个新的输入样本,它通过查找与该样本最相似的K个已知样本(训练集中的样本),来进行分类或回归预测。
一、KNN简介:
为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的K个已知样本,根据少数服从多数的投票法则(majority-voting),将未知样本与K个最邻近样本中所属类别占比较多的归为一类。
对于本土而言,如何判断绿色圆应该属于哪一类,是属于红色三角形还是属于蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被判定为属于红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆将被判定为属于蓝色四方形类。
KNN算法的优缺点:
优点:
-
简单且易于理解: KNN 是一种直观的算法,易于理解和实现,特别适用于入门级的机器学习学习者。
-
无需训练: KNN 是一种基于实例的学习算法,不需要训练模型。新的训练数据可以直接添加到数据集中,而无需重新训练整个模型。
-
对于小规模数据集效果好: 在数据集较小的情况下,KNN 的表现通常比较好,因为在小数据集中能够更好地捕捉数据的局部特征。
-
适用于多类别问题: KNN 在处理多类别问题时表现良好,不需要额外的修改或调整。
缺点:
-
计算成本高: 随着数据集的增大,KNN 的计算成本会显著增加。因为对每个测试样本,都需要计算与所有训练样本的距离,这可能导致效率低下。
-
对异常值敏感: KNN 对异常值(离群点)非常敏感,因为它是基于距离的算法。一个离群点可能对最终的分类结果产生较大影响。
-
维数灾难: 随着特征维数的增加,KNN 的性能可能会下降。这是因为在高维空间中,样本点之间的距离变得更加模糊,这也被称为“维数灾难”。
-
需要合适的距离度量: KNN 对于距离度量的选择比较敏感,需要根据具体问题选择合适的距离度量方法。
-
类别不平衡问题: 如果某个类别的样本数量明显多于其他类别,可能导致预测偏向于样本数量多的类别。
二、KNN算法实现过程及个人理解
一、获取数据集
本次实验使用的数据集来自于Kaggle ,此网站下有各种类型的数据集开放下载,可以取来实验使用。本次为学习过程,所以选用了双特征的1500条水果推理数据,来完成K近邻算法学习实验。从Kaggle上获取的数据集文件为fruit_dataset.csv
二、导入数据
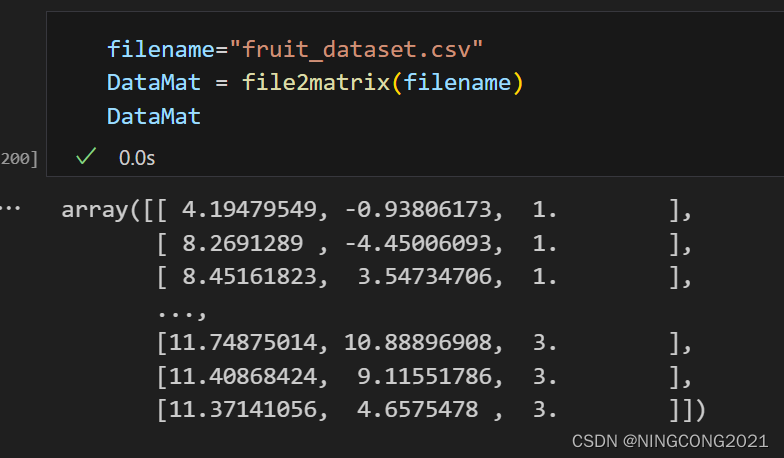
这段代码的作用是读取一个文本文件,将其中的数据行转换为NumPy数组,并将文本标签替换为数字标签,最终返回包含数据的NumPy数组。由于我使用的是.cvs文件而不是.txt文件,导入数据集处理的时候稍微有所不同,有时间修改的地方为分隔符‘,’。对实验课程提供的代码依据自身数据集进行了改写,代码如下:
import numpy as np
def file2matrix(filename):
fr = open(filename)
#读取文件所有内容
arrayOLines = fr.readlines()
#得到文件行数
numberOfLines = len(arrayOLines)
#print(numberOfLines)
#创建对应的零矩阵,为了后续填数据
returnMat = np.zeros((numberOfLines-1,3))
#行的索引值
index = 0
#列头
for line in arrayOLines:
#s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
if(index == 0):
#将数据集的第一行提出来当列头
lineheader = line.split(',')
#print(lineheader)
index += 1
continue
#将类型替换为对应的数字标签代号 ('apple','1') ('banana','2') ('orange','3')
line=line.replace('apple','1')
line=line.replace('banana','2')
line=line.replace('orange','3')
#使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。
line=line.split(',')
#将数据导入numpy
returnMat[index-1,:] = line[0:3]
index += 1
return returnMat
测试及结果:
三、使用Matplotlib库查看数据
这段代码的作用是使用Matplotlib库创建散点图来展示数据。接受数据集NumPy数组作为输入,其中每一行包括两个特征值和一个标签值。根据标签值的不同,散点图中的点被分别用黑色、橙色和红色表示,用于可视化不同类别的数据点。对实验课程提供的代码依据自身数据集进行了改写,改写后的代码如下:
# 分析数据:使用Matplotlib创建散点图
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
# 数据展示
#def showData(datingDataMat, datingLabels):
def showData(datingDataMat):
fig, axs = plt.subplots(nrows=1, ncols=1)
#print(datingDataMat)
LabelsColors = []
for i in datingDataMat:
if i[2] == 1:
LabelsColors.append('black')
if i[2] == 2:
LabelsColors.append('orange')
if i[2] == 3:
LabelsColors.append('red')
#print(LabelsColors)
axs.scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 1], color=LabelsColors)
axs0_title_text = axs.set_title('Guessing fruit')
axs0_xlabel_text = axs.set_xlabel('Parx')
axs0_ylabel_text = axs.set_ylabel('Pary')
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')
# 设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
# 添加图例
axs.legend(handles=[didntLike, smallDoses, largeDoses])
# axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])
# axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])
# 显示图片
plt.show()测试及结果:
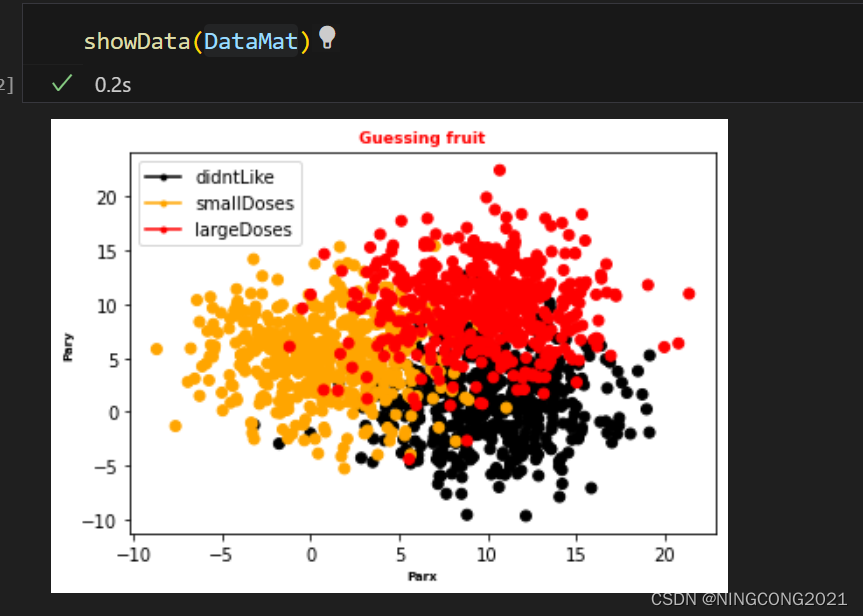
数据集选的一般,勉强能用。
四、随机取样
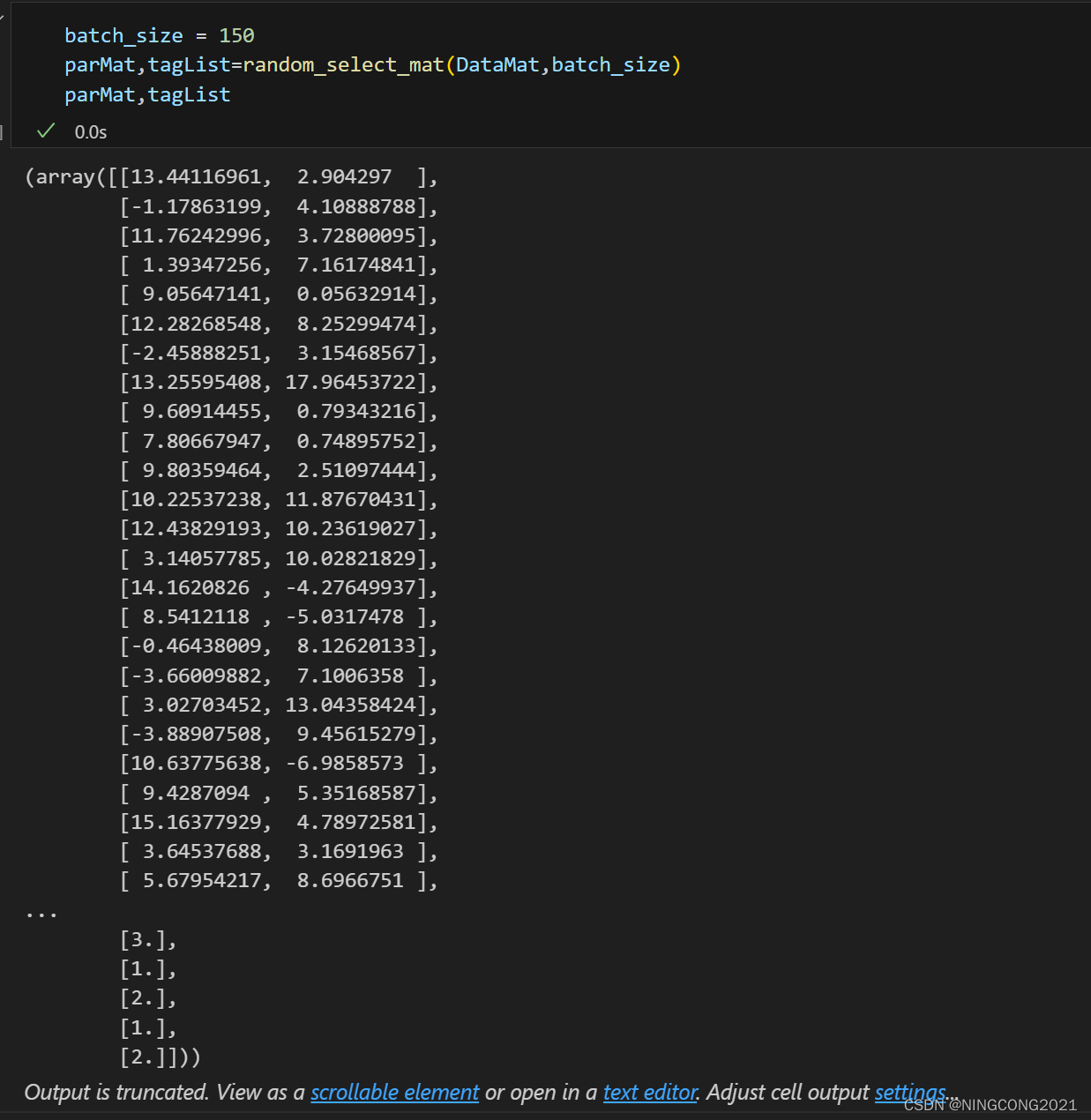
这段代码的作用是从输入矩阵中随机选择指定数量的行,然后将这些行分为两个新矩阵:一个包含特征数据,另一个包含对应的标签数据,最后返回这两个新矩阵。这段代码对导入的数据集进行了标签参数分离和小批量随机取样,虽然小批量随机取样对KNN好像没什么作用,脑子一热就写了,那就把他一起带上,代码如下:
#数据集中随机取样
def random_select_mat(matrix, batch_size):
# 获取输入矩阵的行数
total_rows = matrix.shape[0]
# 确保要选择的行数不超过输入矩阵的总行数
if batch_size > total_rows:
batch_size = total_rows
# 随机生成要选择的行的索引
random_indices = np.random.choice(total_rows, batch_size, replace=False)
# 使用随机生成的索引选择行并创建新矩阵
random_matrix = matrix[random_indices, :]
parmat = random_matrix[:,:matrix.shape[1]-1]
taglist = random_matrix[:,matrix.shape[1]-1:]
return parmat,taglist测试及结果:
 五、参数归一化
五、参数归一化
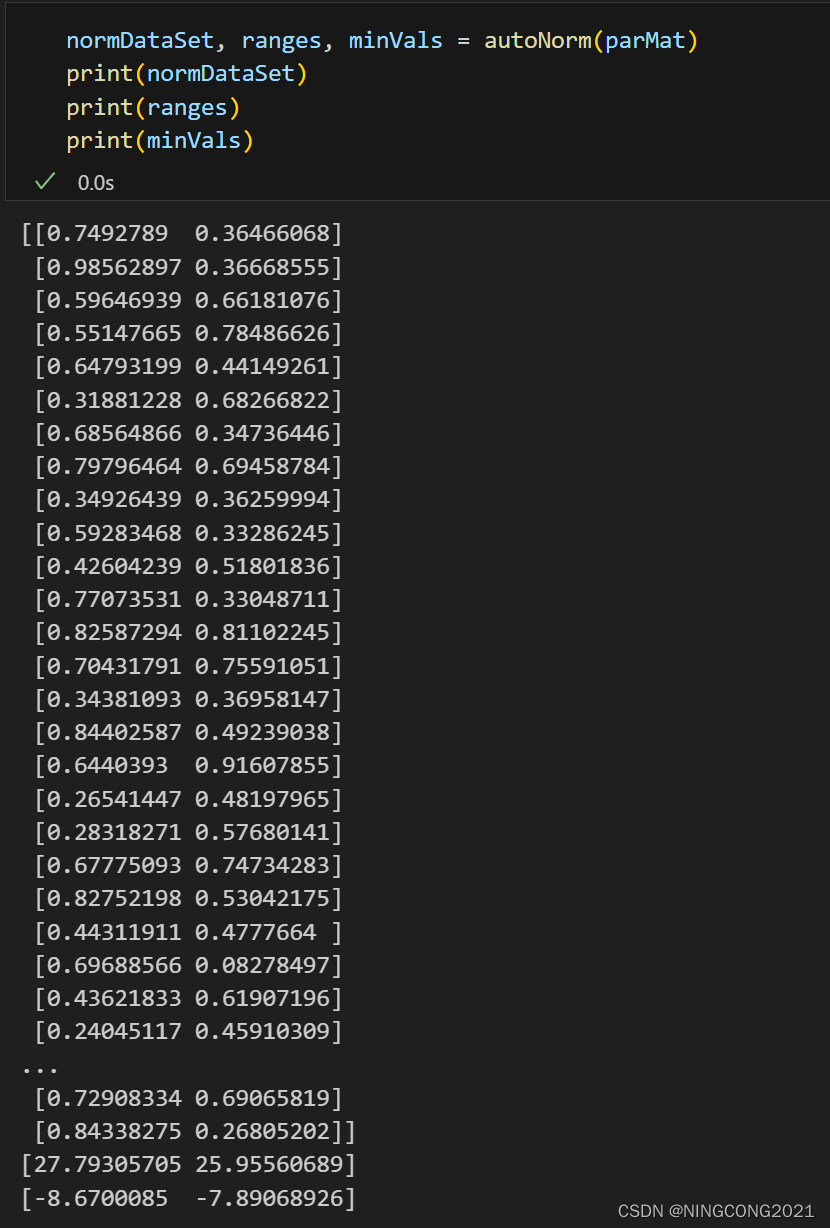
这段代码用于归一化输入的数据集,将数据的范围缩放到 [0, 1] 范围内,确保各个特征具有相同的重要性。我对部分代码进行了注释的补充,代码本身已经能完成任务了,无需修改,补充了一些于numpy广播机制有关的内容的注释。
# 归一化
def autoNorm(dataSet):
#获得数据的最小值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
#min(0) 和 max(0) 表示在每列上进行最小值和最大值的计算,返回一个包含每列最小值和最大值的数组。
# 这两个数组分别存储了数据集中每个特征的最小值和最大值。
#最大值和最小值的范围
ranges = maxVals - minVals
#shape(dataSet)返回dataSet的矩阵行列数
normDataSet = np.zeros(np.shape(dataSet))
#返回dataSet的行数
m = dataSet.shape[0]
#原始值减去最小值
#np.tile(minVals, (m, 1)) 这一行代码是使用 NumPy 的 np.tile() 函数来创建一个新的矩阵,
# 其中 minVals 数组的内容在行方向(维度0)上被重复 m 次,而在列方向(维度1)上被重复 1 次。
normDataSet = dataSet - np.tile(minVals, (m, 1))
#除以最大和最小值的差,得到归一化数据
normDataSet = normDataSet / np.tile(ranges, (m, 1))
#返回归一化数据结果,数据范围,最小值
return normDataSet, ranges, minVals测试及结果:
六、KNN分类器
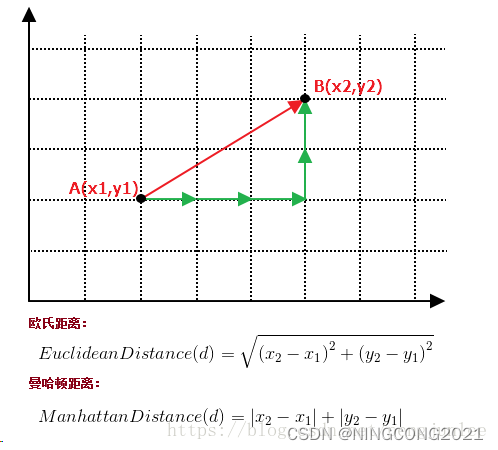
以下是一个 K 最近邻(KNN)分类器的简单实现。它通过计算待分类数据与训练集中数据的欧式距离,选择距离最小的 K 个邻居,然后通过投票的方式确定待分类数据的类别。整体流程包括计算距离、排序、投票统计和返回结果。这部分代码进行距离计算的方法使用了欧几里得距离,也就是L2范数距离:
直白点说就是两点之间的直线距离。
除了欧几里得距离外还有一个计算距离的可选项,叫做曼哈顿距离。
曼哈顿距离也被称为L1范数距离。
曼哈顿距离是计算两点在一个网格上的路径距离,它只允许沿着网格的水平和垂直方向移动,对于二维平面就是x轴的距离差减去y轴的距离差(不带平方)。
# 分类器
import operator
# 输入:inX - 用于分类的数据(测试集);dataSet - 训练集;labes - 分类标签;K - KNN算法参数,选择距离最小的K个点
# 输出:sortedClassCount[0][0] - 分类结果
def classify0(inX, dataSet, labels, k):
#numpy函数shape[0]返回dataSet的行数
dataSetSize = dataSet.shape[0]
#在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向)
diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet
#二维特征相减后平方
sqDiffMat = diffMat**2
#sum()所有元素相加,sum(0)列相加,sum(1)行相加
sqDistances = sqDiffMat.sum(axis=1)
#开方,计算出距离
distances = sqDistances**0.5
#返回distances中元素从小到大排序后的索引值
sortedDistIndices = distances.argsort()
#定一个记录类别次数的字典
classCount = {}
for i in range(k):
#取出前k个元素的类别
voteIlabel = labels[sortedDistIndices[i]][0]
#dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。
#计算类别次数
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#python3中用items()替换python2中的iteritems()
#key=operator.itemgetter(1)根据字典的值进行排序
#key=operator.itemgetter(0)根据字典的键进行排序
#reverse降序排序字典
sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
#返回次数最多的类别,即所要分类的类别
return sortedClassCount[0][0]测试及结果:
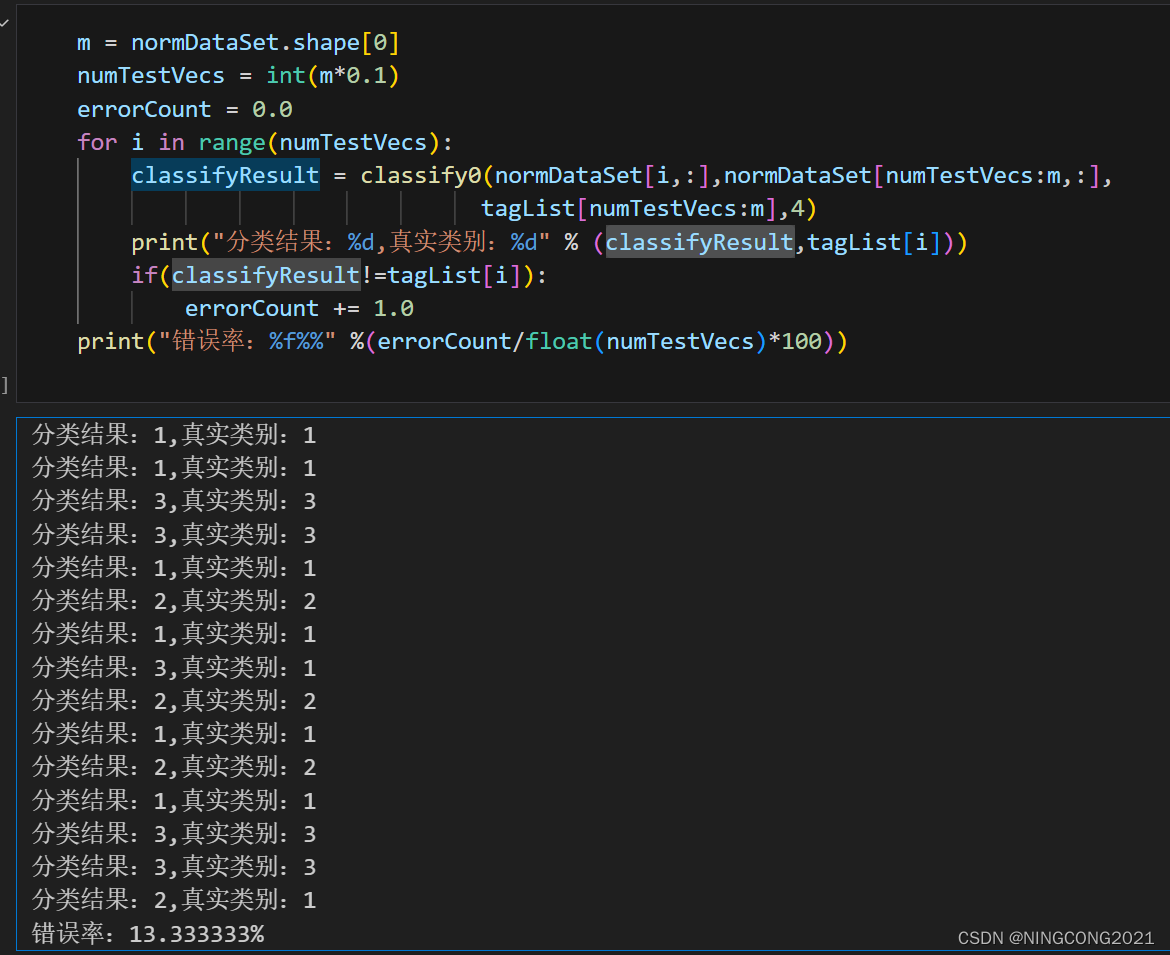
错误率13.33333%,数据集还行,就错了两个。
七、函数封装测试:
这段代码把先前用到的函数做了一个集合,模仿出一次KNN测验的过程,对以上代码编写做了一个总结。本人对样例代码根据自身数据集需求进行了一定量的改写,以便能够适配自身需求,并添加了自己随手写的(脑热)小批量随机取样,整体大部分框架没有改变。
def classifyPerson():
#输出结果
resultList = ['apple','banana','orange']
parX = float(input("你的参数X:"))
parY = float(input("你的参数Y:"))
#打开的文件名
filename = "fruit_dataset.csv"
#打开并处理数据
DataMat = file2matrix(filename)
#选取的数据批量
batch_size = 150
#从数据集中随机抽取指定批量的样本,对KNN好像有点用又好像没有
parMat,tagList=random_select_mat(DataMat,batch_size)
#训练集归一化
normMat, ranges, minVals = autoNorm(parMat)
#生成NumPy数组,测试集
inArr = np.array([parX, parY])
#测试集归一化
norminArr = (inArr - minVals) / ranges
#返回分类结果
classifierResult = classify0(norminArr, normMat, tagList, 3)
#打印结果
print("根据你给的X和Y这玩意可能是:%s" % resultList[int(classifierResult)-1])测试及结果:
三、学习总结
KNN很直接,根据拿到的数据集直接可以出一个模型,可以说每一个输入样本对应的结果根据你的数据集已经完全确定了,很直白,很直接,如果不更换数据集样本训练一轮和多轮的结果是完全一样的,等下KNN好像不需要多少多少轮训练,然后写了个小批量取样??总之理解了KNN到底在做什么事情,KNN还是比较简单的。
至此,机器学习笔记二到此结束。
















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











