







目录
概述
Inception是GoogleNet中的模块,它的目的是设计一种具有优良局部拓扑结构的网络,即对输入图像并行地执行多个卷积运算或池化操作,并将所有结果拼接为一个非常深地特征图。因为,
,
等不同卷积地运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。
另一方面,Inception网络是复杂的(需要大量工程工作)。它使用了大量的trick来提升性能,包括速度和准确率两方面。它的不断进化带来了多种Inception网络版本的出现。常见的版本有:
- Inception V1
- Inception V2和Inception V3
- Inception V4和Inception ResNet
每个版本都是前一个版本的迭代进化。了解Inception网络的升级可以帮助我们构建自定义分类器,优化速度和准确率。不过,一般情况下,或许较低版本的Inception模块工作效果更好。
Inception V1
图像识别任务中存在一些问题:
- 由于信息位置的巨大差异,为卷积操作选择合适的卷积核大小就比较困难。信息分布更全局性的图像偏好较大的卷积核,信息分布比较局部的图像偏好较小的卷积核
- 非常深的网络更容易过拟合,将梯度更新传输到整个网络是很困难的
- 简单地堆叠较大地卷积层非常消耗计算资源
为此,Inception模块被设计出来。Inception的思路是:在同一层级上运行具有多个尺寸的滤波器,网络本质上会变得稍微宽一些,而不是更深。
下图是”原始“的Inception模块。它使用了3个不同大小的滤波器(,
,
)对输入执行卷积操作,此外,它还会执行最大池化。所有子层的输入最后会被级联起来,并传送至下一个Inception模块。
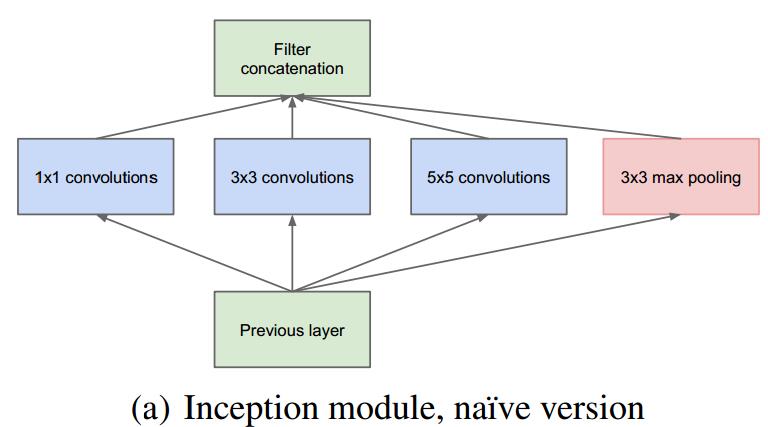
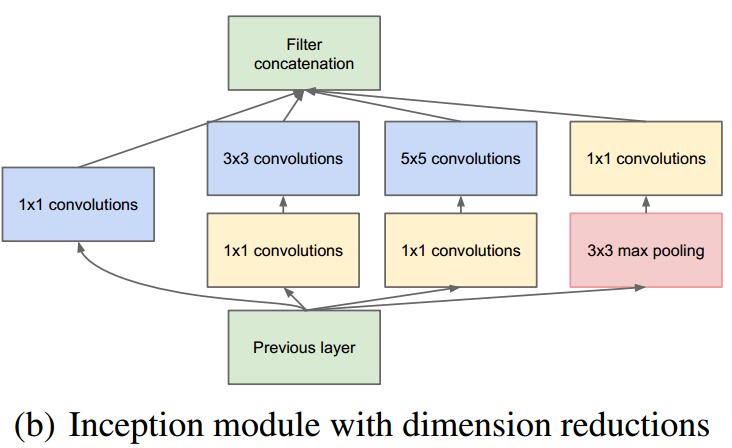
卷积神经网络需要耗费大量的计算资源,为了降低算力成本,作者在和
卷积层之前添加了额外的
卷积层,来限制输入信道的数量。尽管添加额外的卷积操作似乎是反直觉的,但是
卷积比
卷积要廉价很多,而且输入信道数量减少也有利于降低算力成本。需要注意的是,
卷积在最大池化层之后,而不是之前。添加了这些额外的
卷积之后,就构成了可实现降维的Inception模块:
使用Inception (V1)模块构建的GoogleNet:
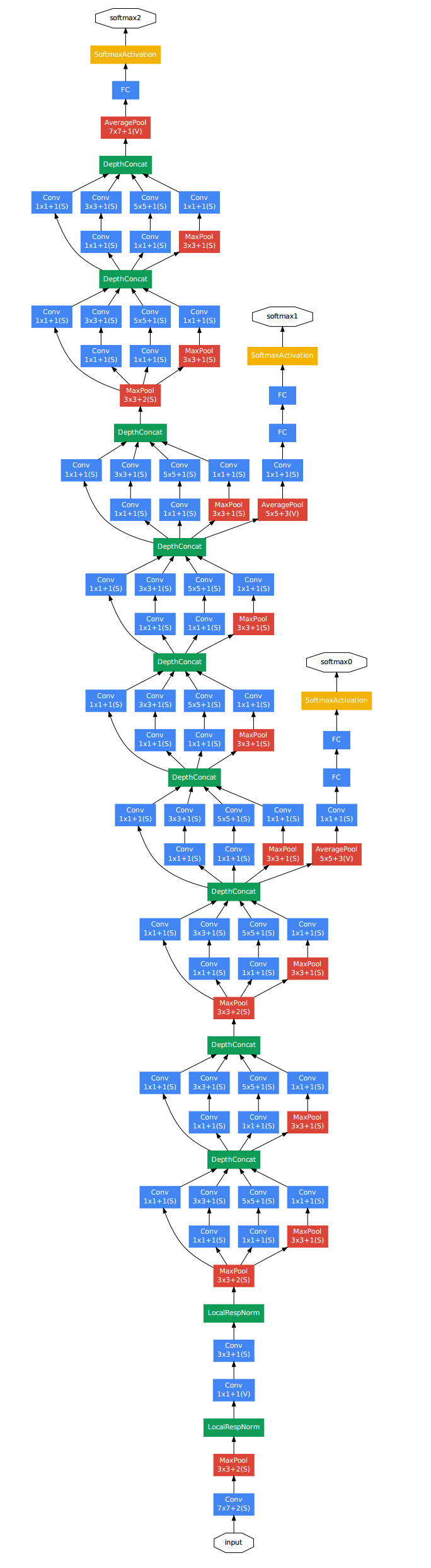
上图的GoogleNet结构中使用了9个线性堆叠的Inception模块。它有22层(包括池化层的话是27层)。该模型的在最后一个Inception模块使用全局平均池化。
这是一个深层分类器,和所有的深层网络一样,它也会遇到梯度消失问题。为了阻止该网络中间梯度的小时过程,作者引入了两个辅助分类器,它们对其中两个Inception模块的输出执行softmax操作,然后在同样的标签上使用计算辅助损失。总损失即辅助损失和真实损失的加权和。在GoogleNet的论文中,两个辅助分类器的权重值是0.3.辅助损失只是用于训练,在推断过程中并不使用。
Inception V2
Inception v2 和 Inception v3 来自同一篇论文《Rethinking the Inception Architecture for Computer Vision》。在这篇论文中,作者积极探索拓展网络的方法,旨在通过恰当的分解卷积与积极的正则化尽可能高效地利用添加的计算。
问题:
- 减少特征的表征性瓶颈。直观上来说,当卷积不会大幅度改变输入维度时,神经网络可能会执行地更好。过多地减少维度可能会造成信息的损失,这也成为”表征性瓶颈“
- 使用更优秀的因子分解方法,卷积才能在计算复杂度上更加高效
解决方案:
- 将
的卷积分解为
两个
的卷积运算以提升计算速度。尽管这有点违反直觉,但是

- 前一版Inception中的
- 前一版Inception中的
- 此外,醉着将
的卷积核分解为
和
两个卷积。例如,一个
的卷积,然后执行一个
的卷积。他们还发现这种方法在成本上要比单个

- 次数如果n=3,则与上一张结构图一样(同样
- 次数如果n=3,则与上一张结构图一样(同样
- 其次,模块中的滤波器组被扩展(即变得更宽而不是更深),以解决表征性瓶颈:

Inception v2模块便包含了以上三中Inception模块。
Inception v3
问题:
- 作者注意到辅助分类器直到训练过程快结束时才有较多贡献,那时准确率接近饱和。作者认为辅助分类器的功能时正则化,尤其是它们具备BatchNorm和Dropout操作时。
- 是否能够改进Inception v2而无需大幅更改模块仍需调查
解决方案:
Inception v3整合了前面Inception v2中所提到的所有升级,还使用了:
- RMSProp优化器
- Factorized
卷积
- 辅助分类器使用了BatchNorm
- 标签平滑(添加到损失公式的一种正则项,旨在阻止网络对某一类别过分自信,即阻止过拟合)
Inception v4
nception v4 和 Inception -ResNet 在同一篇论文《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》中介绍。
在改论文中,研究者介绍到,Inception架构可以用很低的计算成本达到很高的性能。而在传统的网络架构中引入残差连接去到了优秀的效果,其结果与Inception v3网络当时的最新版本相近。这使得人们好奇,如果将Inception架构和残差连接起来会是什么样的效果。在这篇论文中,研究者通过研究明确地证实了,结合残差连接可以显著加速Inception地训练。也有一些证据表明残差Inception网络在相近的成本下略微超过没有残差网络的Inception网络。















 990
990











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









