







 文章探讨了使用支持向量机(SVM)解决车间调度问题,并引入麻雀搜索算法优化SVM参数,以提高收盘价预测的准确性。通过实例展示了优化前后预测性能的对比和改进效果。
文章探讨了使用支持向量机(SVM)解决车间调度问题,并引入麻雀搜索算法优化SVM参数,以提高收盘价预测的准确性。通过实例展示了优化前后预测性能的对比和改进效果。
一、车间调度问题
支持向量机(support vector machines,SVM)是一种二 分类模型,在分类小样本数据的问题上有着很大的优势, 可用来解决分类问题和回归问题。其优点在于能够克服 局部最小值,具有良好的鲁棒性和准确性,能够很好地解 决过拟合问题并且泛化能力好。其基本内容是求出可以 正确划分训练集数据并寻找最优分类超平面
二、麻雀搜索算法
1.算法介绍
麻雀搜索算法是近两年提出的新兴群智能优化算法,具备算法原理简单、收敛速度快等优势。该算法基于麻雀种群的社会行为将麻雀个体分为发现、加入者以及警戒者,发现者能力较强可以找到食物并为同类指明方向,公式为:

式中:t和T分别为算法当前以及最大更新次数,∝为随机数,其取值范围为1,1;Q同样为随机数,但服从正态分布;L为所有元素都是1的行短阵,其列数由待求解问题维度确定;R2为大于0小于1的预警值,ST为大于0.5小于1的安全值。
加入者则通过观察发现者的食物来源以便取而代之,公式为:

式中:Xp(t+1)为所有发现者中位置更新后的最佳位置;A+ = AT(AAT)-1其中,A为所有元素随机取值为1或-1的行矩阵,列数为求解问题维度;Xworst为当前种群中的最劣位置;n为种群中麻雀数量.
警戒者需要时刻留意当前环境,以便发现危险立即飞往安全环境。位置更新公式为:

式中:Xbest为当前种群中的最佳位置;β为随机数且遵循标准正态分布;fi, fg, fw分别为目前个体、当前种群最优、最劣的适应度值;k在-1,1范围内随机取值,E的作用是防止分母为0.
2.部分代码
代码如下(示例):
% 支持向量机用于收盘价预测,首先是未优化的,其次是优化后的
%% 清空环境
tic;clc;clear;close all;format compact
%% 加载数据
load data
% 归一化
[a,inputns]=mapminmax(data',0,1);%归一化函数要求输入为行向量
data_trans=data_process(5,a);%% 对时间序列预测建立滚动序列,即用1到m个数据预测第m+1个数据,然后用2到m+1个数据预测第m+2个数据
input=data_trans(:,1:end-1);
output=data_trans(:,end);
%% 数据集 前75%训练 后25%预测
m=round(size(data_trans,1)*0.75);
Pn_train=input(1:m,:);
Tn_train=output(1:m,:);
Pn_test=input(m+1:end,:);
Tn_test=output(m+1:end,:);
%% 1.没有优化的SVM
bestc=0.001;bestg=10;%c和g随机赋值 表示没有优化的SVM
t=0;%t=0为线性核函数,1-多项式。2rbf核函数
kernelFunction = 'rbf'; % 或者其他的核函数,如'linear'
boxConstraint = 1; % C值
epsilon = 0.1; % Epsilon-insensitive区域半径
model = fitrsvm(Pn_train, Tn_train, 'KernelFunction', kernelFunction, 'BoxConstraint', boxConstraint, 'Epsilon', epsilon);
predict2 = predict(model, Pn_test);
% 反归一化,为后面的结果计算做准备
predict0=mapminmax('reverse',predict2',inputns);%测试实际输出反归一化
T_test=mapminmax('reverse',Tn_test',inputns);%测试集期望输出反归一化
T_train=mapminmax('reverse',Tn_train',inputns);%训练集期望输出反归一化
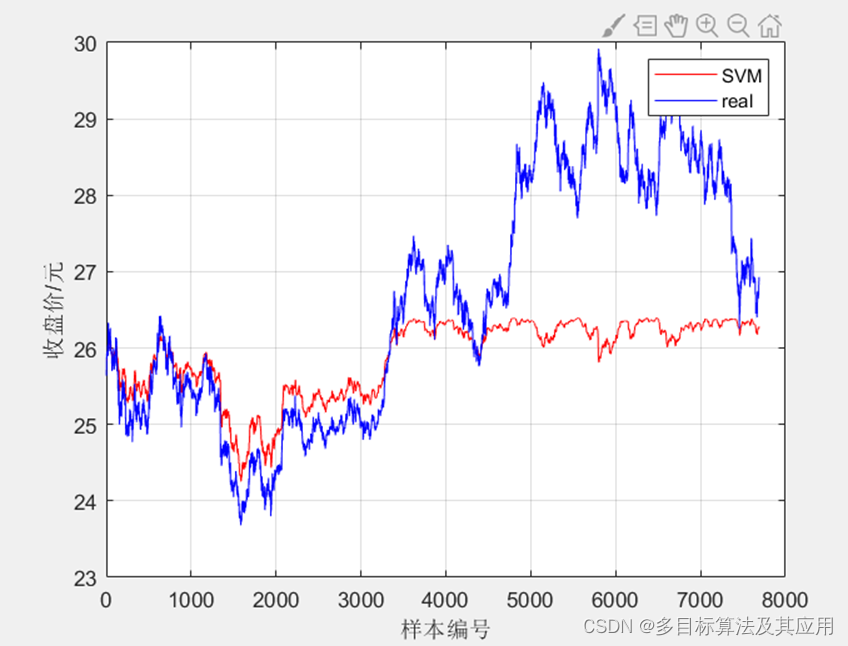
figure
plot(predict0,'r-')
hold on;grid on
plot(T_test,'b-')
xlabel('样本编号')
ylabel('收盘价/元')
legend("SVM","real");
figure
error_svm=abs(predict0-T_test)./T_test*100;%测试集每个样本的相对误差
plot(error_svm,'r-*')
xlabel('样本编号')
ylabel('收盘价相对误差/%')
%% 2.设计SSA优化SVM,用于选择最佳的C和G
pop=10; % 麻雀数量
Max_iteration=20; % 最大迭代次数
dim=2; % 优化lstm的3个参数
lb = [10^(-3),0.001];%下边界
ub = [10^1,0.03];%上边界
% Pn_train=input(1:m,:);
% Tn_train=output(1:m,:);
% Pn_test=input(m+1:end,:);
% Tn_test=output(m+1:end,:);
fobj = @(x) fun(x,Pn_train,Tn_train,Pn_test,Tn_test);
%基础麻雀算法
[Best_pos,Best_score,SSA_curve]=SSA(pop,Max_iteration,lb,ub,dim,fobj); %开始优化
figure;
plot(SSA_curve,'r-');
xlabel('进化代数');
ylabel('适应度值(均方差)');
title('适应度曲线')
grid on;
kernelFunction = 'rbf'; % 或者其他的核函数,如'linear'
boxConstraint = Best_pos(1); % C值
epsilon = Best_pos(2); % Epsilon-insensitive区域半径
% 用训练好的参数重新对模型进行训练
model = fitrsvm(Pn_train, Tn_train, 'KernelFunction', kernelFunction, 'BoxConstraint', boxConstraint, 'Epsilon', epsilon);
predictions = predict(model, Pn_test);
% 反归一化
predict_tr=mapminmax('reverse',Tn_test',inputns);
predict1=mapminmax('reverse',predictions',inputns);
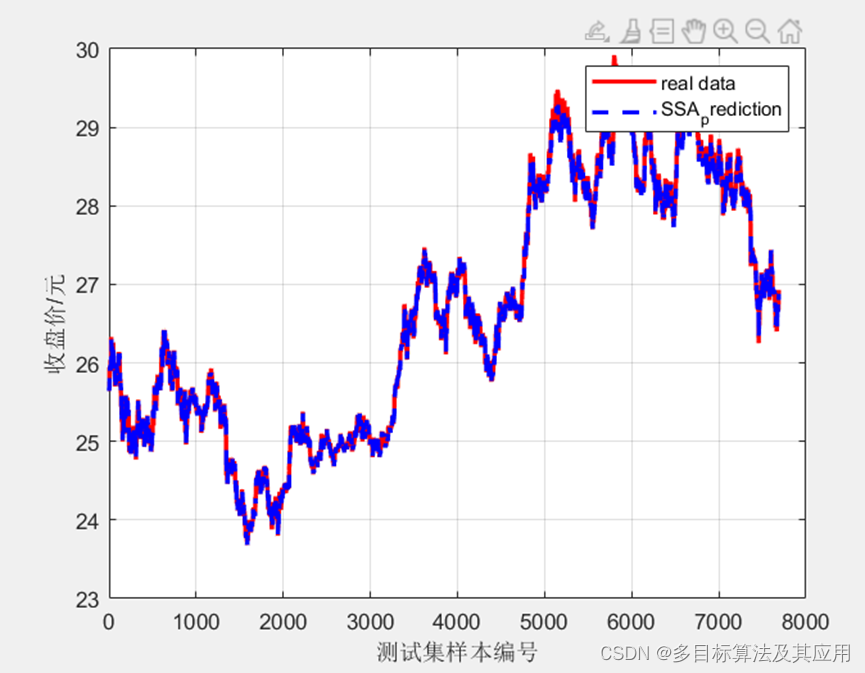
figure
plot(T_test, 'r-', 'LineWidth', 2); % 原始曲线,增加线条宽度便于区分
hold on;
grid on;
plot(predict1, 'b--', 'LineWidth', 2); % 预测曲线,使用点划线
xlabel('测试集样本编号')
ylabel('收盘价/元')
legend('real data', 'SSA_prediction');
%% 结果分析
disp('优化前的均方误差')
mse_svm=mse(predict0-T_test)
disp('优化前的平均相对误差')
mre_svm=sum(abs(predict0-T_test)./T_test)/length(T_test)
disp('优化前的平均绝对误差')
abs_svm=mean(abs(predict0-T_test))
disp('优化前的归一化均方误差')
a=sum((predict0-T_test).^2)/length(T_test);
b=sum((predict0-mean(predict0)).^2)/(length(T_test)-1);
one_svm=a/b
disp('优化后的测试集均方根误差')
rmse_svm=sqrt(mse(predict1-T_test))
disp('优化后的均方误差')
mse_pso_svm=mse(predict1-T_test)
disp('优化后的平均相对误差')
mre_pso_svm=sum(abs(predict1-T_test)./T_test)/length(T_test)
disp('优化后的平均绝对误差')
abs_pso_svm=mean(abs(predict1-T_test))
disp('优化后的归一化均方误差')
a1=sum((predict1-T_test).^2)/length(T_test);
b1=sum((predict1-mean(predict1)).^2)/(length(T_test)-1);
one_pso_svm=a1/b1
toc %结束计时
三、总算法优化结果
未优化前:
优化后:

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









