







目录
导读:在人工智能快速发展的今天,各类大型语言模型(LLM)层出不穷,如何在众多选择中找到最适合自己需求的模型成为开发者面临的重要挑战。本文提出了一个全面的四维分类框架,从模型架构、功能用途、参数规模和部署方式四个关键维度对当前主流大模型进行系统化剖析。文章通过与Java概念的巧妙类比,帮助读者建立起对大模型的清晰认知。特别值得关注的是文章对推理大模型与指令大模型的深度对比分析,揭示了它们在能力侧重和应用场景上的本质差异。无论您是初探AI领域的开发者,还是寻求最佳模型选型方案的项目管理者,这篇文章都将为您提供一套实用的评估框架和选型指南,助力您在AI应用开发中做出更明智的决策。
一、引言:AI大模型分类的必要性
随着人工智能技术的迅猛发展,各大科技公司和研究机构纷纷推出了多款大型语言模型(LLM)产品。这些模型在功能、性能和应用场景上各有特点,给用户选择和应用带来了一定挑战。建立一个系统化的分类框架变得尤为必要,它不仅能帮助开发者和企业更准确地选择适合自己需求的模型,还能促进我们对大模型技术本质的深入理解。
本文将从四个关键维度对当前主流大模型进行分类解析,通过与软件工程中熟悉的Java概念进行类比,帮助读者建立起对AI大模型的系统性认知。由于涉及较多人工智能、机器学习领域的专业术语,我们将重点聚焦于核心概念的解释与应用价值的分析。
二、大模型分类的四大维度概述
为了全面理解AI大模型的特性与差异,我们将从以下四个维度进行分类分析:
- 模型架构维度:探讨模型的内部结构设计,如自回归模型、自编码模型等
- 功能用途维度:分析模型的专长与应用场景,如指令执行型、逻辑推理型等
- 参数规模维度:考察模型的参数量级及其对性能的影响
- 部署方式维度:研究模型的部署选择及其适用环境
这四个维度相互关联又各具特色,共同构成了评估和选择大模型的完整框架。接下来,我们将深入探讨每个维度的具体内容。
三、模型架构维度详解
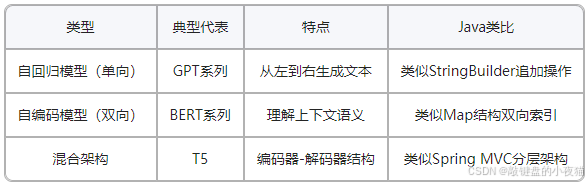
模型架构是大模型的核心设计理念,决定了模型处理信息的方式。理解不同架构的特点,有助于我们选择适合特定任务的模型类型。
1. 自回归模型(单向)
典型代表:GPT系列(Generative Pre-trained Transformer)
技术原理:自回归模型采用单向注意力机制,从左到右顺序处理文本,每次生成新词时只能看到之前已生成的内容,而看不到后续内容。这类似于人类写作的自然流程,非常适合文本生成任务。
特点与优势:
- 擅长连贯性强的内容创作
- 生成质量高,逻辑流畅
- 适合对话、故事创作等生成性任务
局限性:
- 无法同时访问上下文的全部信息
- 在理解复杂语义关系时可能表现不佳
Java类比:类似于StringBuilder的追加操作,每次只能在已有内容的基础上向后追加,无法回溯修改前面的内容。
StringBuilder text = new StringBuilder();
text.append("AI").append("大模型").append("正在");
// 每次只能基于已有内容继续添加,类似GPT只能看到之前的内容
text.append("revolutionizing软件开发");2. 自编码模型(双向)
典型代表:BERT系列(Bidirectional Encoder Representations from Transformers)
技术原理:自编码模型使用双向注意力机制,能够同时处理句子中的前后文信息,使模型获得更全面的上下文理解能力。这种设计特别适合语义理解与分析任务。
特点与优势:
- 深度理解文本语义和上下文关系
- 擅长分类、匹配、实体识别等理解任务
- 上下文感知能力强
局限性:
- 生成能力相对较弱
- 不太适合开放式文本生成
Java类比:类似Map结构的双向索引,可以从任意位置快速访问和关联数据,实现多维度的信息查询与处理。
Map<String, String> contextMap = new HashMap<>();
contextMap.put("前文", "人工智能技术");
contextMap.put("当前", "BERT模型");
contextMap.put("后文", "双向理解");
// 可以同时访问任意位置的信息,类似BERT可以双向理解3. 混合架构
典型代表:T5(Text-to-Text Transfer Transformer)
技术原理:混合架构结合了编码器与解码器的优势,先使用编码器理解输入文本的全部上下文,再使用解码器生成目标输出。这种设计灵活性高,能够适应多种类型的任务。
特点与优势:
- 兼具理解和生成的能力
- 适应性强,通过调整输入输出格式解决多种任务
- 在复杂任务上表现优异
局限性:
- 计算复杂度较高
- 对资源要求更高
Java类比:类似Spring MVC的分层架构,将输入处理(Controller)、业务逻辑(Service)和输出生成(View)分离,实现灵活的信息流转与处理。
// 类似MVC架构
// 编码器 - 类似Controller处理输入
public class Encoder {
public EncodedRepresentation process(String input) {
// 双向处理输入文本
return new EncodedRepresentation(input);
}
}
// 解码器 - 类似View生成输出
public class Decoder {
public String generate(EncodedRepresentation representation) {
// 基于编码表示生成输出
return "生成的文本";
}
}四、功能用途维度详解

从功能用途角度看,大模型可以根据其专长与设计目标进行分类,不同类型的模型适合解决不同性质的问题。
1. 指令大模型
概念阐释:指令大模型专注于理解并执行用户的具体指令,将复杂的指令转化为具体的输出结果。这类模型经过了专门的指令微调(Instruction Fine-tuning),使其能够准确理解人类意图。
典型场景:需求实现、内容创作、代码生成等任务导向型应用。
Java开发示例:
// 用户输入指令:
// "创建一个RESTful API端点,用于查询用户订单历史"
// 模型可能生成的代码:
@RestController
@RequestMapping("/api/orders")
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("/user/{userId}")
public ResponseEntity<List<Order>> getUserOrders(
@PathVariable Long userId,
@RequestParam(required = false) LocalDate startDate,
@RequestParam(required = false) LocalDate endDate) {
List<Order> orders = orderService.findUserOrders(userId, startDate, endDate);
return ResponseEntity.ok(orders);
}
}代表模型:GPT-4, Claude, 通义千问
优势与适用场景:
- 擅长遵循复杂指令和多步骤任务
- 适合需要具体输出的生产环境
- 在内容创作、代码生成等领域表现出色
2. 推理大模型
概念阐释:推理大模型专注于逻辑分析、问题求解和深度思考,通常经过特殊的推理能力强化训练。这类模型不仅能够提供答案,更能展示详细的推理过程和分析思路。
典型场景:问题诊断、算法设计、数学求解、逻辑推理等需要深度思考的任务。
Java开发示例:分析内存溢出异常原因
// 用户输入:
// "我的Java应用频繁出现OutOfMemoryError,堆转储显示大量ArrayList实例没有被回收"
// 模型分析过程:
/*
1. 分析问题表象:OutOfMemoryError表明堆内存不足
2. 分析可能原因:大量ArrayList实例未被回收说明可能存在内存泄漏
3. 推理可能场景:
- 集合被静态引用但未清理
- 对象引用未显式置null
- 实现了自定义equals/hashCode导致哈希碰撞
4. 建议排查方案:
- 检查静态集合使用
- 审查长生命周期对象
- 使用内存分析工具定位泄漏源
*/代表模型:DeepSeek-R1、Google Minerva、Claude 3 Opus
优势与适用场景:
- 擅长解决需要步骤分解的复杂问题
- 在故障排查、算法设计等领域表现突出
- 能够提供详细的分析过程和推理链
五、参数规模维度详解
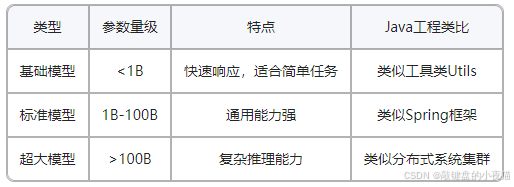
参数规模是衡量模型复杂度和潜在能力的重要指标。不同规模的模型在性能、资源需求和适用场景上存在显著差异。
1. 基础模型
参数量级:小于1B(十亿)参数
技术特性:
- 训练成本较低,对计算资源要求不高
- 推理速度快,延迟低
- 能够在资源受限环境下运行
优势与局限:
- 响应迅速,适合实时应用
- 能够处理基础任务,但复杂问题解决能力有限
- 适合特定领域的专用场景
Java工程类比:类似于Java中的工具类(Utils),专注于解决特定、明确的问题,体积小巧但功能有限。
// 类似于轻量级工具类
public class StringUtils {
public static boolean isEmpty(String str) {
return str == null || str.trim().length() == 0;
}
public static String capitalize(String str) {
if (isEmpty(str)) return str;
return Character.toUpperCase(str.charAt(0)) + str.substring(1);
}
}2. 标准模型
参数量级:1B至100B参数
技术特性:
- 平衡了性能与资源消耗
- 通用能力较强,适应多种任务
- 部署要求适中,主流服务器可承载
优势与局限:
- 具备良好的语义理解和生成能力
- 在大多数任务上表现稳定
- 训练和部署成本可控
Java工程类比:类似于Spring框架,功能全面、适应性强,能够处理大部分常见需求,但也需要一定的系统资源支持。
// 类似于多功能框架
@Service
public class ContentProcessor {
@Autowired
private DataRepository repository;
@Autowired
private ValidationService validator;
public ProcessResult handle(ContentRequest request) {
// 复杂业务逻辑处理
// 融合多种能力
return new ProcessResult();
}
}3. 超大模型
参数量级:大于100B参数
技术特性:
- 拥有强大的推理与理解能力
- 能够处理极其复杂的任务
- 对计算资源要求极高
优势与局限:
- 在复杂推理、创意生成等方面表现卓越
- 具备较强的零样本和少样本学习能力
- 部署和运行成本高昂
Java工程类比:类似于分布式系统集群,由多个子系统协同工作,能力强大但资源消耗大,适合处理高复杂度任务。
// 类似于分布式系统架构
public class DistributedAISystem {
private final List<ComputeNode> nodes;
private final LoadBalancer balancer;
private final StateManager stateManager;
public DistributedAISystem(int clusterSize) {
this.nodes = new ArrayList<>(clusterSize);
// 初始化复杂分布式系统
// 需要大量计算资源和协调机制
}
public Result processComplexQuery(Query query) {
// 分布式处理复杂查询
return new Result();
}
}六、部署方式维度详解
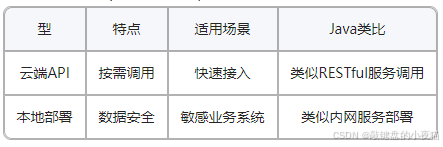
部署方式决定了模型如何被实际应用,影响数据安全、访问速度和集成便捷性。不同的部署方案适合不同的业务场景和安全需求。
1. 云端API
技术特性:
- 通过API接口远程调用模型服务
- 由服务提供商负责基础设施维护
- 按需付费,无需前期硬件投入
优势与适用场景:
- 快速集成,开发周期短
- 持续获得模型更新和优化
- 适合对时效性要求高、预算有限的场景
安全考量:
- 数据需要传输至第三方服务器
- 对敏感信息处理需谨慎
Java类比:类似RESTful服务调用,客户端通过HTTP请求调用远程服务,无需关心具体实现细节。
// 类似于API调用
@Service
public class CloudAIService {
private final RestTemplate restTemplate;
private final String apiEndpoint = "https://api.ai-provider.com/v1/completions";
private final String apiKey;
public CloudAIService(@Value("${ai.api.key}") String apiKey) {
this.restTemplate = new RestTemplate();
this.apiKey = apiKey;
}
public String generateContent(String prompt) {
HttpHeaders headers = new HttpHeaders();
headers.set("Authorization", "Bearer " + apiKey);
headers.setContentType(MediaType.APPLICATION_JSON);
Map<String, Object> requestBody = Map.of(
"prompt", prompt,
"max_tokens", 1000
);
HttpEntity<Map<String, Object>> entity = new HttpEntity<>(requestBody, headers);
ResponseEntity<Map> response = restTemplate.postForEntity(apiEndpoint, entity, Map.class);
return extractContentFromResponse(response.getBody());
}
}2. 本地部署
技术特性:
- 模型在本地服务器或设备上运行
- 数据不出本地网络
- 完全自主控制运行环境
优势与适用场景:
- 数据隐私保护,适合处理敏感信息
- 无网络依赖,可在离线环境使用
- 适合金融、医疗、政府等高安全性要求场景
部署挑战:
- 需要专业的硬件支持
- 维护成本较高
- 模型更新可能不及时
Java类比:类似于内网服务部署,所有处理都在可控的环境中进行,数据不出内网。
// 类似于内网部署服务
@Configuration
public class LocalAIConfig {
@Bean
public AIModelService localAIService() {
// 加载本地部署的模型
Path modelPath = Paths.get("/opt/ai/models/local_model.bin");
return new LocalAIModelService(modelPath);
}
@Bean
public SecurityConfig securityConfig() {
// 配置数据安全策略
return new SecurityConfig(AccessLevel.RESTRICTED);
}
}七、重点聚焦:推理大模型 vs 指令大模型的深度对比
推理大模型和指令大模型代表了当前大模型研发的两个重要方向,它们在能力侧重和应用场景上有明显区别。深入理解它们的差异,有助于我们根据实际需求做出更准确的选择。
1. 推理大模型详解
核心技术特点:
- 经过强化学习或专门训练,增强逻辑推理能力
- 擅长分析因果关系和进行系统思考
- 能够分解复杂问题并提供结构化解答
技术原理解析: 推理大模型通常采用思维链(Chain-of-Thought)方法进行训练,使模型学会像人类一样展示推理步骤。在实际应用中,这些模型倾向于先分析问题结构,然后逐步构建解决方案,而非直接给出答案。
适用场景举例:
- Java异常堆栈分析:能够从异常信息推理出可能的原因
- 系统设计模式选择:根据需求特点推荐最佳设计模式
- 算法复杂度优化:分析算法瓶颈并提出改进方案
代码示例:
public class MathSolver {
public static void main(String[] args) {
String problem = "已知x+y=15, x-y=3,求x和y的值";
// 推理大模型的思考过程:
// 步骤1: 建立方程组
// 方程1: x + y = 15
// 方程2: x - y = 3
// 步骤2: 从方程2得知 x = y + 3
// 步骤3: 代入方程1: (y + 3) + y = 15
// 步骤4: 化简: 2y + 3 = 15
// 步骤5: 继续: 2y = 12
// 步骤6: 求解: y = 6
// 步骤7: 代回求x: x = y + 3 = 6 + 3 = 9
// 步骤8: 验证: 9 + 6 = 15 ✓, 9 - 6 = 3 ✓
// 最终答案: x = 9, y = 6
}
}代表模型及特色:
- DeepSeek-R1:中国团队开发,数学推理能力突出
- Google Minerva:在科学计算和数学解题上表现优异
- GPT-4:通用推理能力强,解决问题策略多样
2. 指令大模型详解
核心技术特点:
- 经过指令微调(RLHF),提高指令遵循能力
- 擅长理解复杂任务需求并按要求执行
- 输出风格和内容可以精确控制
技术原理解析: 指令大模型通过大量人类反馈数据进行强化学习,使模型学会准确理解和执行用户指令。这些模型特别注重输出的格式、风格和内容符合指令要求,而非仅关注内容的正确性。
适用场景举例:
- 根据需求生成API文档:按照标准格式生成完整文档
- 将用户故事转化为技术方案:理解业务需求并转化为技术实现
- 自动化测试用例生成:根据功能描述生成测试代码
代码示例:
// 示例:指令模型处理用户需求
// 用户输入:
// "我需要一个Java方法,接收用户id列表,返回这些用户的订单总数,
// 需要考虑线程安全并添加适当的错误处理"
// 模型输出:
/**
* 计算多个用户的订单总数
* @param userIds 用户ID列表
* @return 所有用户的订单总和
* @throws IllegalArgumentException 当用户列表为null时抛出
*/
public synchronized int getTotalOrders(List<Long> userIds) {
if (userIds == null) {
throw new IllegalArgumentException("User ID list cannot be null");
}
try {
return userIds.stream()
.filter(Objects::nonNull)
.mapToInt(userId -> {
try {
return orderService.getOrderCount(userId);
} catch (ServiceException e) {
logger.warn("Failed to get order count for user: " + userId, e);
return 0; // 错误时返回0订单数
}
})
.sum();
} catch (Exception e) {
logger.error("Error calculating total orders", e);
throw new ServiceException("Failed to calculate total orders", e);
}
}代表模型及特色:
- GPT-3.5/4:指令遵循能力强,适应多种任务场景
- Claude 3:在复杂指令理解和执行上表现出色
- 阿里云通义千问:中文指令处理能力优秀,适合本地化场景
3. 两类模型的系统性对比
| 维度 | 推理大模型 | 指令大模型 |
|---|---|---|
| 核心能力 | 逻辑推理、数学计算、问题分析 | 指令理解与执行、内容生成与格式化 |
| 输入特点 | 适合开放性问题和复杂分析需求 | 适合明确指令和具体任务要求 |
| 典型输入示例 | "请解释Java并发中的ABA问题及其解决方案" | "请用Java 8编写一个线程安全的LRU缓存实现" |
| 输出特点 | 提供详细推理过程和分析思路 | 直接生成符合要求的结果内容 |
| 处理方式 | 倾向于分解问题、逐步分析 | 倾向于理解需求、直接执行 |
| 适用场景 | 系统故障排查、算法设计、方案评估 | 代码生成、文档撰写、内容创作 |
| 评估指标 | 答案准确性、推理逻辑性 | 指令遵循度、输出符合度 |
| 开发适用性 | 适合需要深度思考的设计阶段 | 适合需要快速实现的编码阶段 |
实践案例分析:
在实际软件开发中,这两类模型可以互补使用:
- 设计阶段:使用推理大模型分析系统架构选择,评估各方案的优缺点
输入:"我需要设计一个高并发订单系统,应该选择何种数据库架构?" 推理大模型回应:[详细分析各选项的优缺点、适用场景和性能特点] - 实现阶段:使用指令大模型根据设计生成具体代码
输入:"基于上述设计,请生成订单服务的核心类代码" 指令大模型回应:[直接生成完整可用的代码实现]
八、结论与实践建议
模型选择的综合考量因素
在选择适合的AI大模型时,应综合考虑以下因素:
- 任务性质与复杂度:
- 对于需要深度分析和推理的问题,推荐选择推理大模型
- 对于明确的生成与创作任务,推荐选择指令大模型
- 资源约束与性能需求:
- 资源受限环境可考虑小参数模型或云API方式
- 实时性要求高的场景应选择本地部署的小型专用模型
- 安全与隐私要求:
- 处理敏感数据时,优先考虑本地部署方案
- 一般应用可采用云API,降低实施成本和技术门槛
- 专业领域适配性:
- 特定领域任务应考虑选择针对该领域微调的专业模型
- 通用任务可使用大型通用模型
面向开发者的模型选型指南
- 初步探索阶段:
- 推荐使用云API形式的指令大模型,如GPT-3.5或Claude
- 重点关注易用性和快速集成能力
- 项目开发阶段:
- 根据具体功能需求,结合使用指令模型和推理模型
- 考虑模型的API稳定性和文档完善度
- 生产环境部署:
- 评估数据安全需求,确定部署方式
- 考虑建立混合架构,敏感操作使用本地模型,一般任务使用云API
- 成本效益平衡:
- 小型项目可优先使用按需付费的云服务
- 大规模应用可考虑本地部署专用模型降低长期成本
未来发展趋势展望
随着AI技术的持续发展,大模型领域将呈现以下趋势:
- 专业化与通用化并行:
- 通用大模型将继续扩展参数规模和能力边界
- 同时出现更多针对特定领域优化的小型专业模型
- 混合能力模型兴起:
- 推理能力与指令遵循能力将融合发展
- 多模态能力将成为标准配置
- 部署方式多元化:
- 边缘计算部署将变得普遍
- 联邦学习等保护隐私的技术将广泛应用
- 自主优化能力增强:
- 模型将具备更强的自我评估和学习能力
- 减少人工干预的自适应系统将成为发展方向
在这个快速发展的领域,开发者需要持续关注新技术动态,灵活调整选型策略,充分发挥AI大模型的强大能力,为软件开发带来前所未有的效率提升和创新可能。


















 2952
2952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











