







- Deep Multi-scale Convolutional Neural Network for Dynamic Scene
Deblurring 深度多因子卷积神经网络应用于动态场景去模糊 。其实就是【CNN用于运动图像去模糊】 - 原文链接:https://arxiv.org/pdf/1612.02177.pdf
- 作者发布的用于运动去模糊的训练数据集 GOPRO
dataset(现已经成为基于深度学习的去模糊算法最常用的数据集之一)下载地址:https://github.com/SeungjunNah/DeepDeblur_release
一、Introduction
传统方法都是依据以下式子做去模糊:
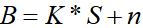
B:blurred image (Known)
S:sharp image (Unknow)
K:blur kernel (Unknow)
n:addictive noise(Known)
- K是作用在S上的模糊卷积核,是模糊的成因(例如在按下快门的一瞬间,你手抖了,或者说失去焦点,就会很容易造成呈像模糊)。
- 对于盲去模糊,【盲】的意思就是【无标签,无sharp image,无S】,另外在去模糊问题本身,K一直都是未知的,人们只能【假想出/假设出/模拟出】近似的K,然后通过在B上进行【退卷积】操作得到S:

这里的Kassume就是估计/假设出来的模糊卷积核,定义∝为退卷积操作。 - 传统方法是以上那样子做的,但是有以下缺点:
1) 难以获得实测清晰图像和模糊图像对用于训练图像去模糊网络;
2) 对于动态场景的图像去模糊问题,难以正确估计/假设出【Kassume模糊核】;
3) 去模糊问题需要较大的感受野。
故下面【本文工作】来了!
二、本文工作
-
弄了一个专门为运动去模糊创造的数据集,内含【sharp】和【blurred】两个文件夹,就是一对对的sharp和blurred图像,blurrd图像是通过对sharp图像进行一系列变换,得到的(作者用了参考文献17的方法,具体我没细看)
-
弄了一个【多尺度CNN模型】,对B进行端到端的学习,直接得到S,而不学习Kassume,得到的结果就没有那种因为模糊核估计错误而产生的【伪像】。另外该网络的设计其实是模仿传统方法的【由粗到细】优化方法(下面会说)。
网络结构如下:
-
作者通过三个多尺度的卷积神经网络,其中B1为待复原图像,分别降采样两次为B2 B3。
-
将降采样的结果分别输入到网络中得到相应分辨率尺寸下复原结果,并将复原结果作为下一阶段的输入,从而知道后续的复原【上面的图片要从下往上看】。
-
这种多尺度的策略,类似于传统的模糊核估计中的【由粗到细】的策略,将复杂的问题进行分解,逐步复原,先在低分辨率下复原大尺度的信息,然后再高分辨率下复原细节信息。简化问题的同时增大了图像的感受野。
PS:该博文只记录一下论文作者的思路和网络结构,实现细节没有看所以没写,以后觉得对本人研究工作有用了会翻出来仔细看一遍。















 4489
4489











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









