







本文为视频理解通用视觉框架OpenMMLab系列课程 第八讲 视频理解(3D卷积方法)的记录。
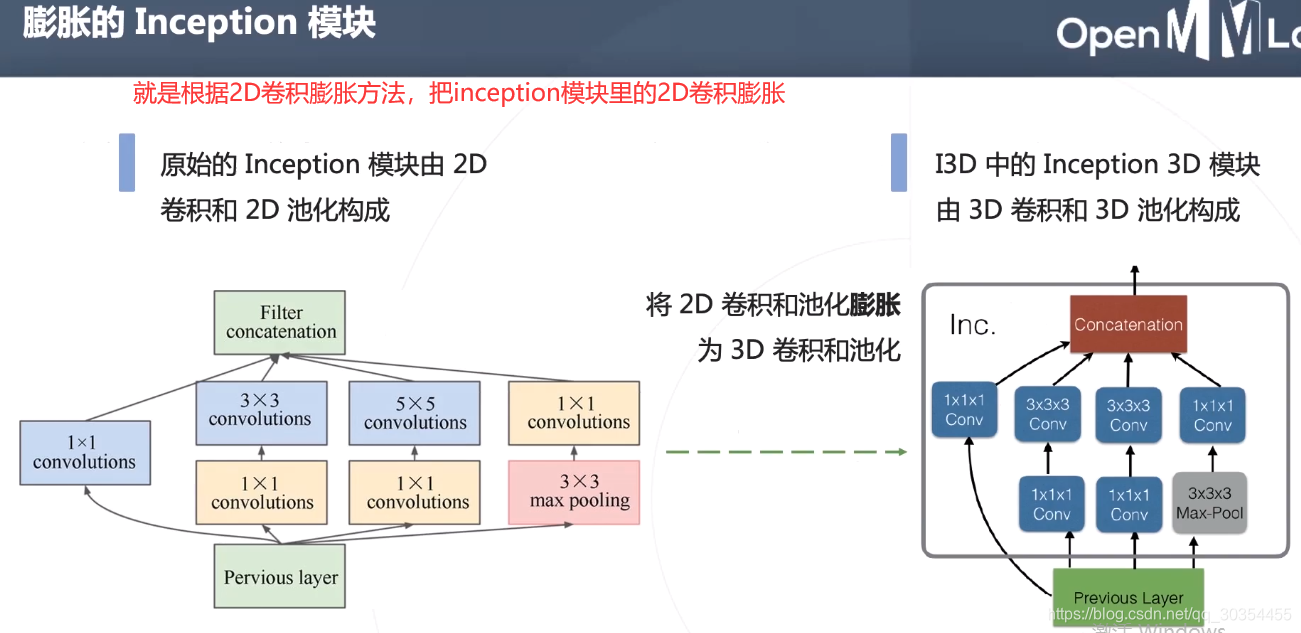
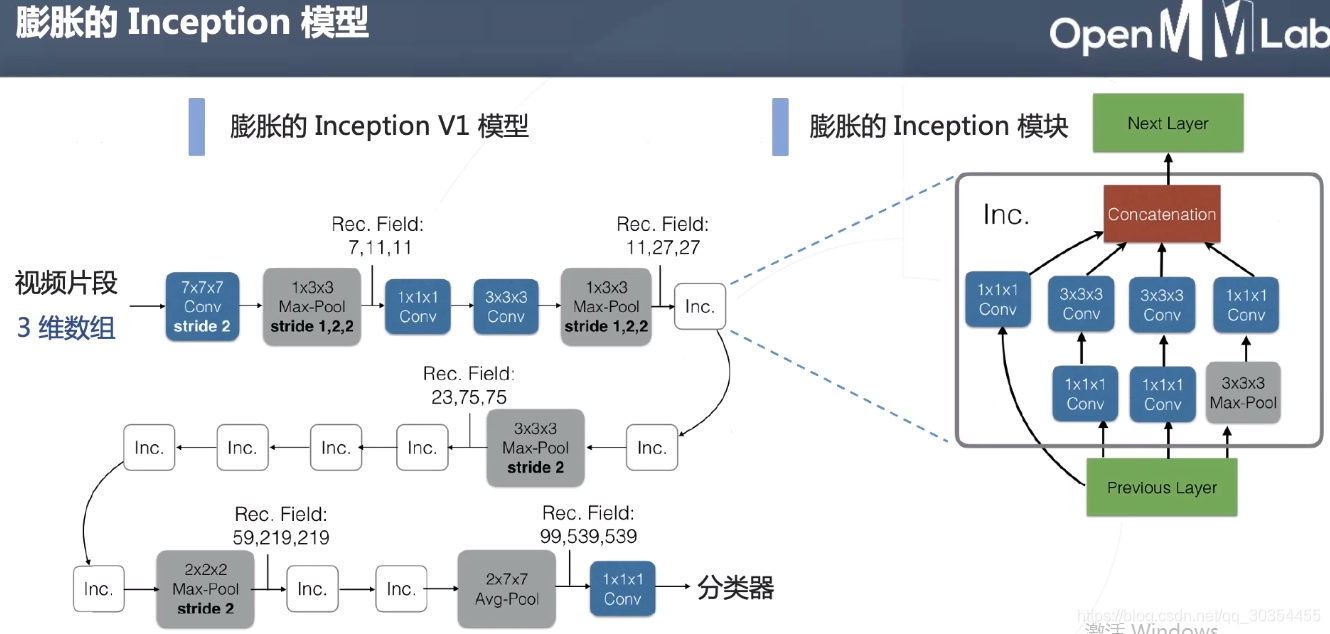
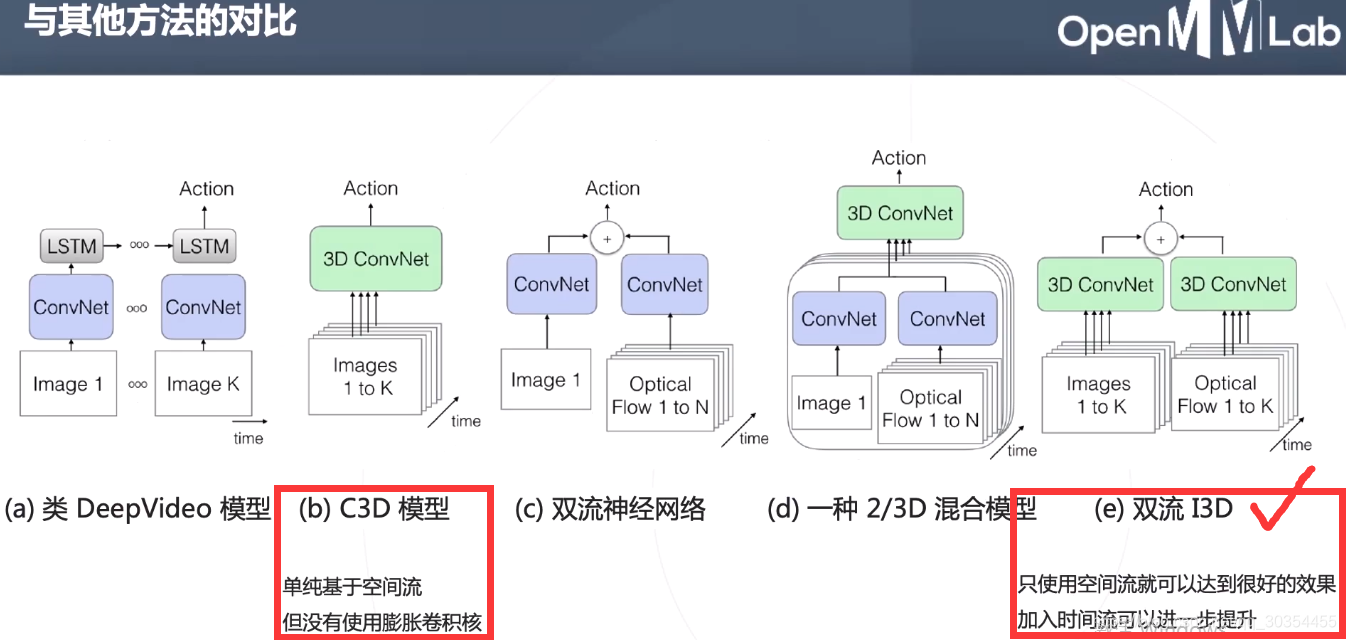

更高效的3D卷积网络:

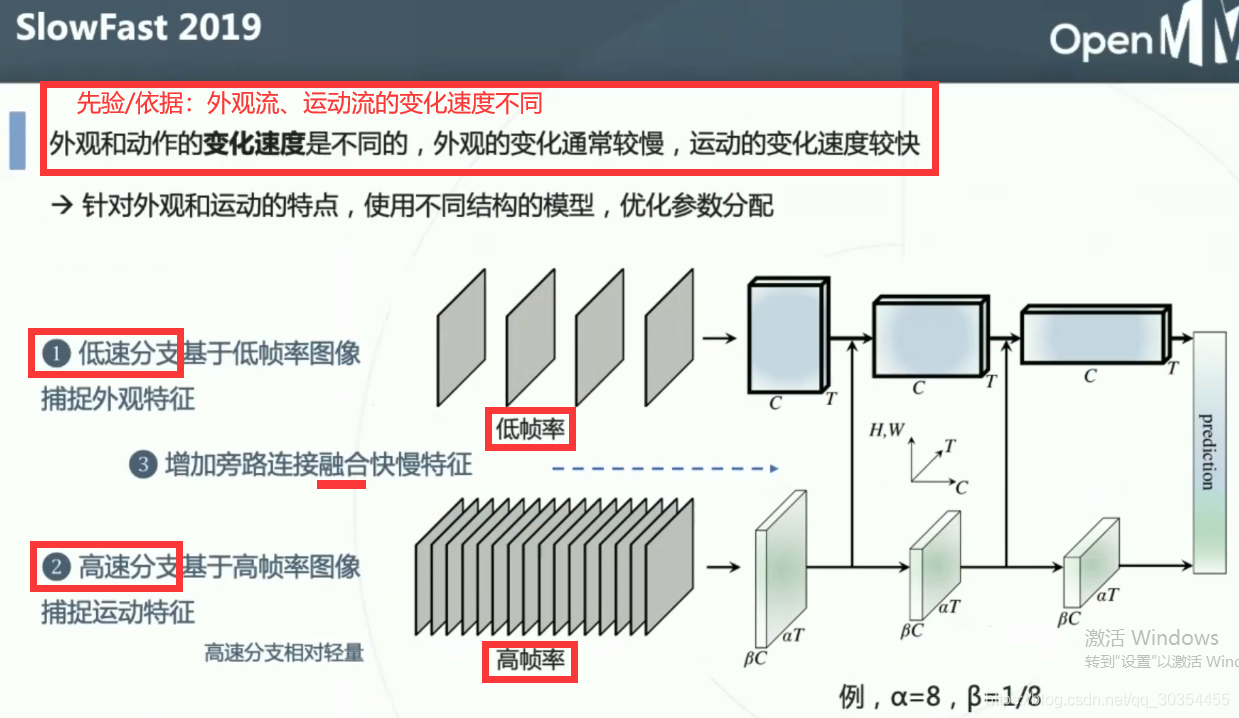
第一种:2D卷积和3D卷积混合使用。
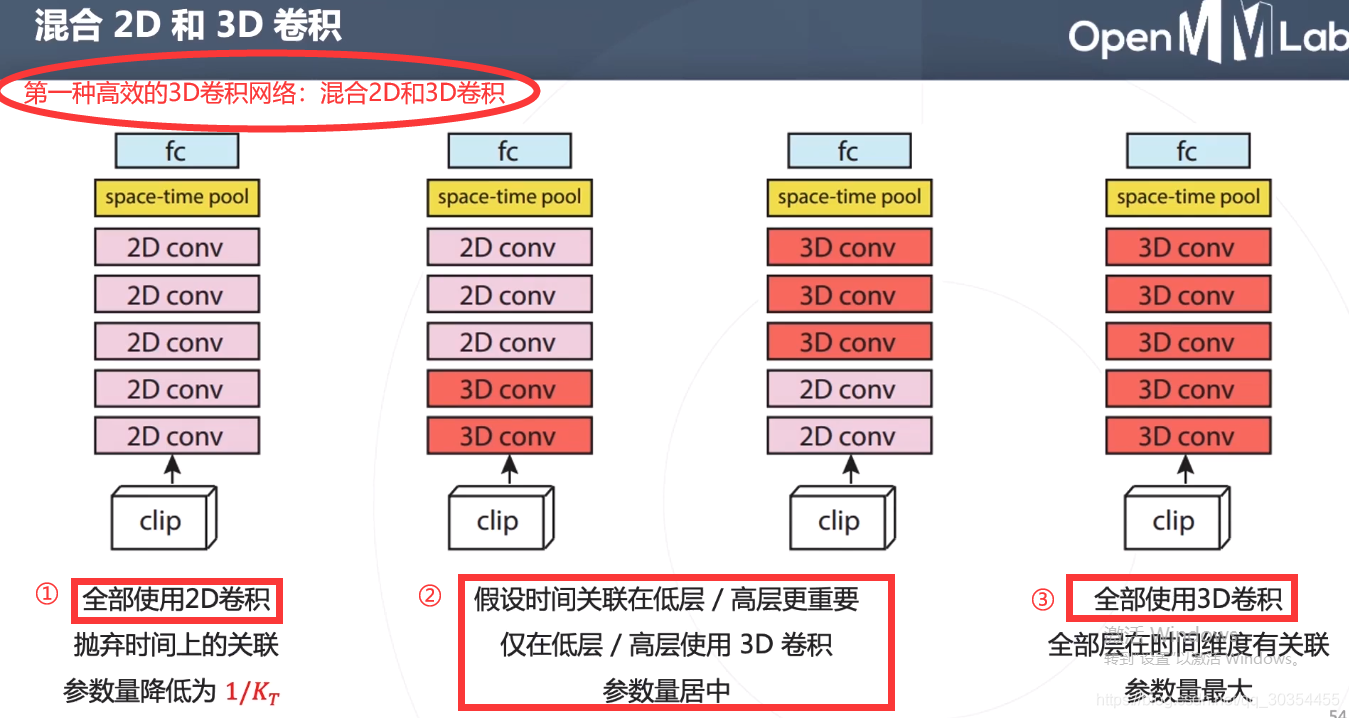
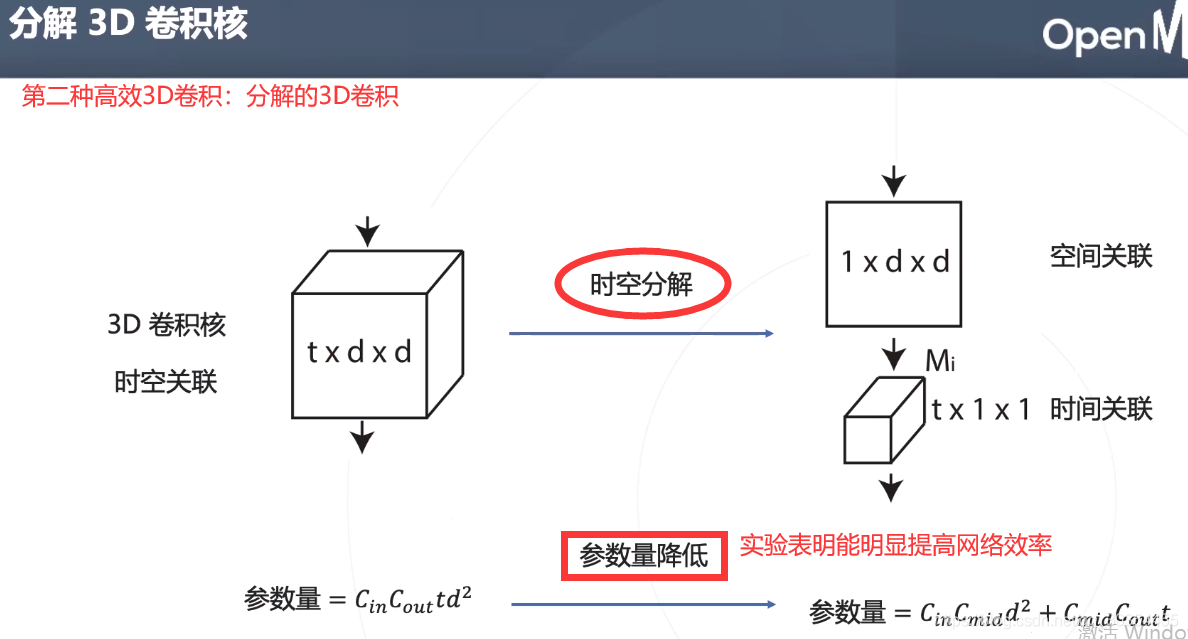
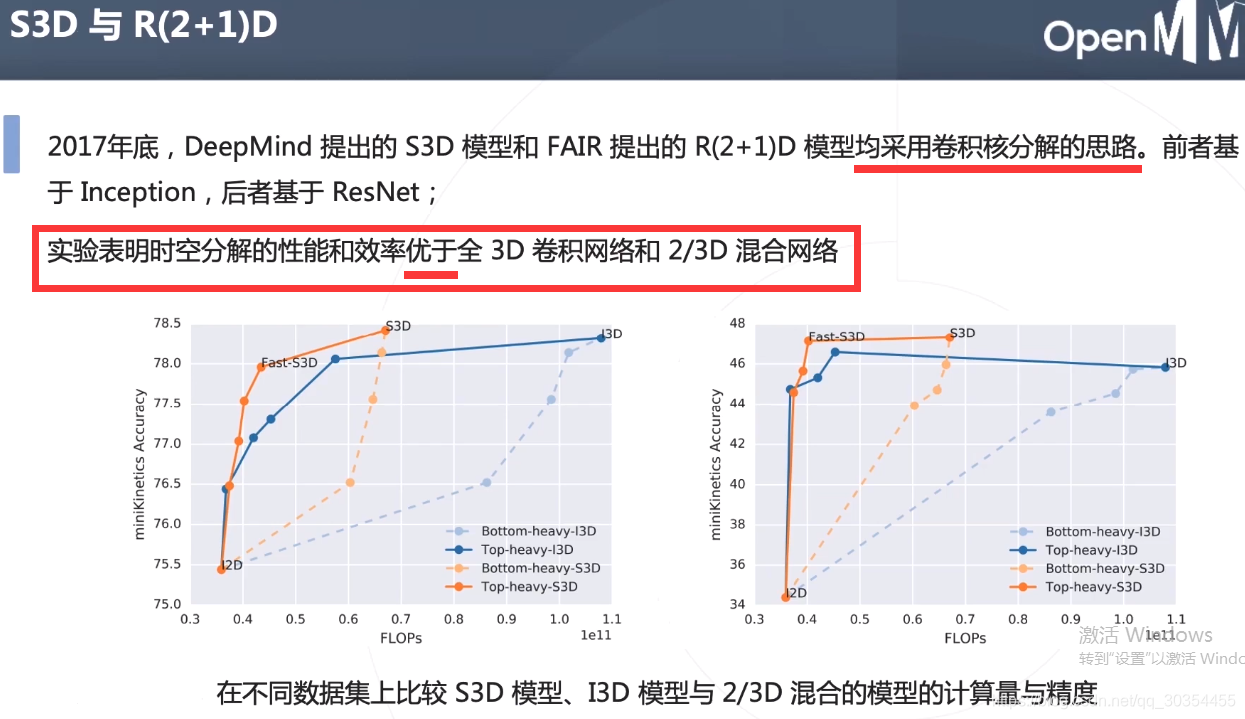
第二种:把3D卷积分解成空间、时间维度。
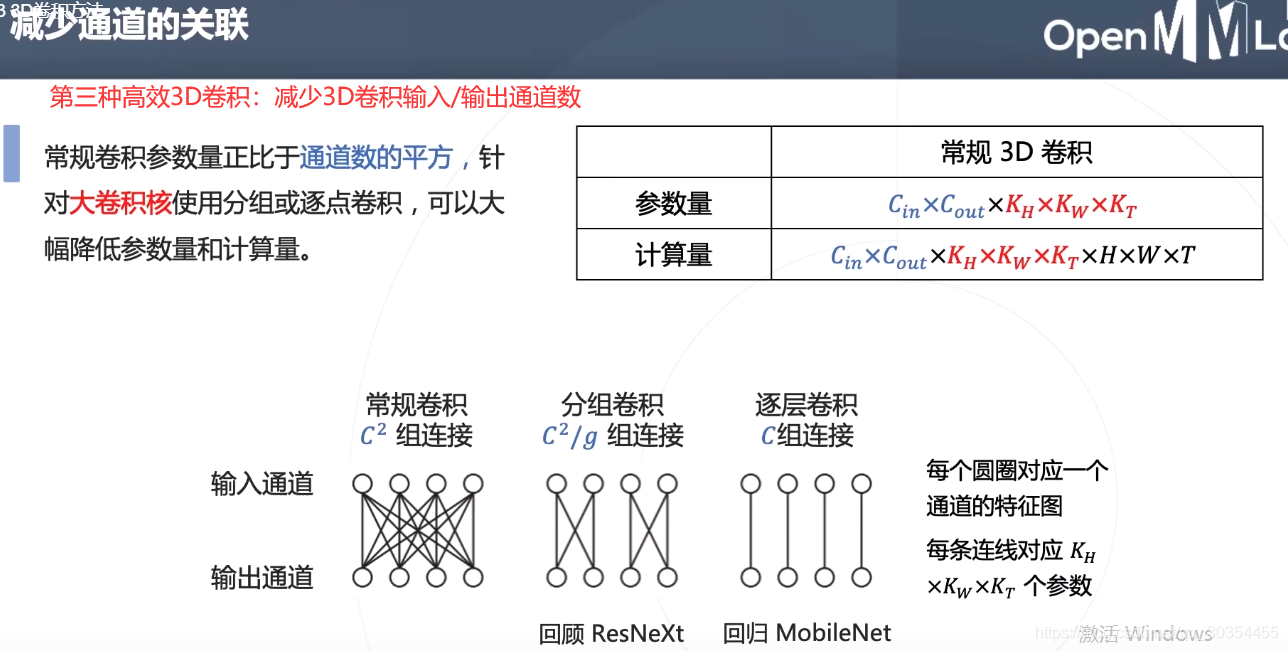
第三种:减少3D卷积的输入/输出通道数。
本文为视频理解通用视觉框架OpenMMLab系列课程 第八讲 视频理解(3D卷积方法)的记录。
第一种:2D卷积和3D卷积混合使用。
第二种:把3D卷积分解成空间、时间维度。
第三种:减少3D卷积的输入/输出通道数。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





















 1271
1271





