







论文: https://arxiv.org/pdf/1812.00332.pdf
源码: https://github.com/MIT-HAN-LAB/ProxylessNAS
ProxylessNAS 是MIT韩松教授组发表在ICLR2019上的一篇论文,是对NAS方法的进一步补充和优化。这篇文章内容还真是蛮多的写了好久。。。-_-||
简介
Neural Architecture Search (NAS) 是目前在自动搜索神经网络结构的重要算法,然而NAS的使用却需要大量算力的支撑(
1
0
4
G
P
U
h
o
u
r
s
10^4 GPU hours
104GPUhours),在大规模数据集(ImageNet 1000)上应用难度会更大,因此为了避免高GPU内存占用,他们就使用了一些代理任务来解决这个问题,比如在更小数据集上(CIFAR10等)训练,或者使用小的block,或者减少训练次数。但这些使用代理任务的办法都无法保证能得到目标任务的最优解。为此这篇文章提出了一种不使用代理任务的方法ProxylessNAS能够直接在大规模的目标任务上搜索结构,能够解决NAS方法GPU高内存占用和计算耗时过长的问题。

Contribution
1、ProxylessNAS 不需要使用代理任务,直接在大规模的数据及上搜索整个网络
2、为NAS提供了一种新的路径剪枝的方式,展示了NAS与模型压缩之间的紧密关系,最终通过二值化的手段将内存消耗降低了一个量级
3、提出了一种基于梯度的方法(延迟正则化损失)来约束硬件指标。
4、在CIFAR10 和 Imagenet上进行试验,然后实现了state-of-the-art 准确率。
相关工作
1.基于 Proxy Tasks的NAS方法并没有考虑Latency性能的影响
2.现有的NAS方法采用的是使用stack堆叠block构成最终的网络,但实际的网络中是可以存在不同种类的block的
3.DARTS巧妙地将搜索空间转化为可微的形式,把结构和权重联联合优化,但DARTS仍然是基于Proxy Tasks的,所以在计算堆叠block的过程中仍然占用大量的GPU资源
4.DropPath 训练一个网络来评价一个结构,结构通过随机置零路径采样得到的。
方法
因为要搜索结构所以首先要对整个网络的搜索空间定义成超参数。另外PNAS搜索的不是block而是基于路径进行搜索
Construction of over-parameterized network
网络结构定义为
N
(
e
,
⋅
⋅
⋅
,
e
n
)
N(e, ···,e_n)
N(e,⋅⋅⋅,en) 其中
e
e
e表示一个有向无环图中一条确定的边,设
O
=
{
o
i
}
O=\{{o_i}\}
O={oi}表示N的候选基础元操作,对于每一条边都对应了这些操作,而网络搜索的就是每个
e
e
e该选择什么操作
O
O
O,
m
O
m_O
mO表示每条边上有并行的N条通路的混合操作,所以超参数化的网络结构可表示为以下形式。
N
(
e
=
m
O
1
,
⋅
⋅
⋅
,
e
n
=
m
O
n
)
N(e=m_O^1,···,e_n=m_O^n)
N(e=mO1,⋅⋅⋅,en=mOn)
对于一个输入
x
x
x,混合操作
m
O
m_O
mO的输出结果是基于
N
N
N条通路所形成的,在One-shot中
m
O
(
x
)
m_O(x)
mO(x)是
{
o
i
(
x
)
}
\{o_i(x)\}
{oi(x)}的和,当在DARTS中的时候
m
O
(
x
)
m_O(x)
mO(x)表示
{
o
i
(
x
)
}
\{o_i(x)\}
{oi(x)}的权重和,这个权重是通过对N条通路上的结构参数取softmax得到的。
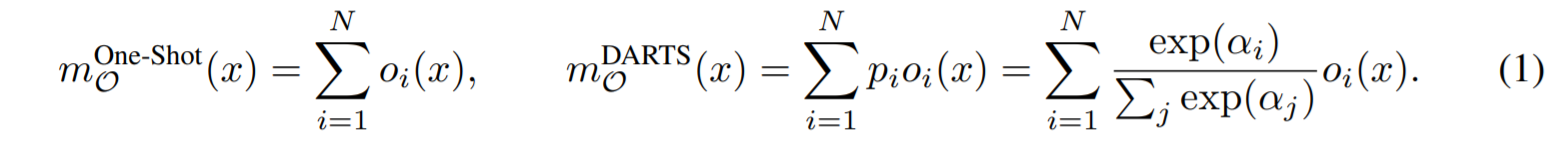

Learning Binarized Path
为了降低内存占用,文章提出适用二值化路径的方式来节约内存,二值化方式如下
首先从Path的角度,在所有的路径中只保留1条path
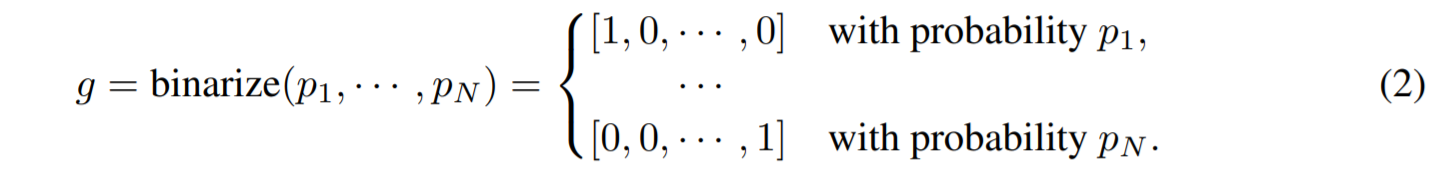
当确定了路径之后,再考虑二值化gate
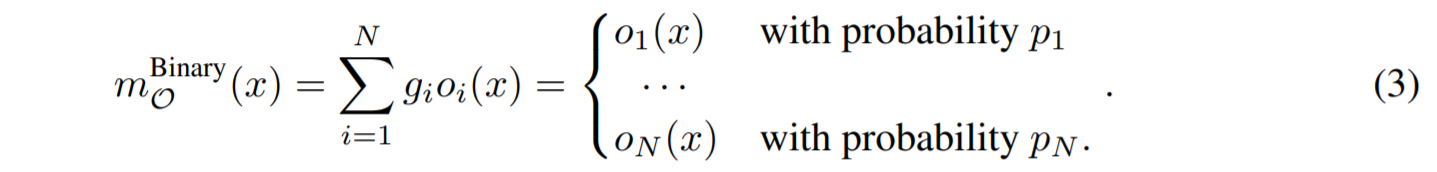
Training Binarized Architecture Parameters
因为想要训练权重就要考虑如何更新weight和architecture
训练weight首先要固定好architecture,然后根据公式随机采样二值化gate,得到一个网络结构进行训练
训练architecture参数就要先固定weight然后重置gate在验证集上更新architecture参数。
两个训练需要交替进行,一旦训architecture参数训练完成,我们就能通过修剪冗余的路径得到紧凑的网络结构,这样我们就能很容易的选择权值最高的路径。
architecture parameters更新不同于weights,文章使用了一种基于梯度的方法学习architecture parameters
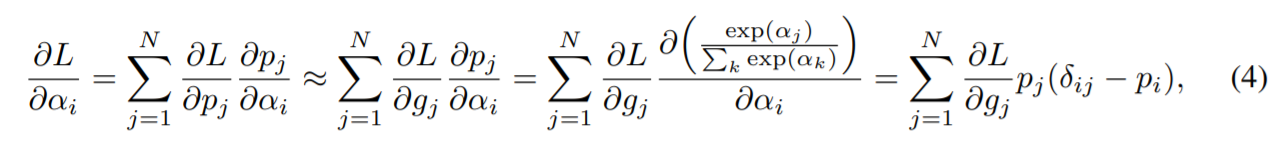
因为存在N条path,因此在更新architecture的时候回需要N倍的GPU内存占用,为了解决这个问题,文中根据多项式分布采样两条path,这样就可以把候选操作从N降到2,同时path weight和gate也要重置。
然后使用采样的到的两个path通过公式(4)更新architecture parameters。
最终通过对architecture parameters计算softmax得到path weight,然后需要进行比例放缩来更新architecture parameters以保持没有被采样得到的path weight不变
Handling Non-Differentiable hardware Metrics
处理不可微分的硬件指标,想要构建一个可以使用网络更新优化的可微函数
让Latency可微
想要可微就需要把网络的延迟建模成一个连续的函数
假设跟定一个候选操作集合
{
o
j
}
\{o_j\}
{oj}那么对于每一个
o
j
o_j
oj都有一个指定的权重
p
j
p_j
pj来表示每个
o
j
o_j
oj被选择的概率,为此为了建立期望映射,就可以把操作与latency的关系写成如下公式:
E
[
l
a
t
e
n
c
y
i
]
=
∑
j
p
j
i
∗
F
(
o
j
i
)
E[latency_i]=\sum_j p_j^i * F(o_j^i)
E[latencyi]=j∑pji∗F(oji)
因为上述公式的
E
[
l
a
t
e
n
c
y
i
]
E[latency_i]
E[latencyi]表示的是第i个block中,
l
a
t
e
n
c
y
i
latency_i
latencyi的数学期望,其中F就是将
o
j
o_j
oj映射成latency的函数,因此对于整个网络来说
E
[
l
a
t
e
n
c
y
]
=
∑
i
E
[
l
a
t
e
n
c
y
i
]
E[latency] = \sum_i E[latency_i]
E[latency]=i∑E[latencyi]
然后这事就成了

此时latency可微了之后就能够名正言顺的加入到loss里面
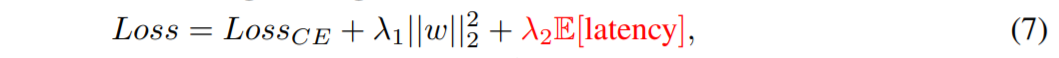
Reinforce-Based Approach
这里是针对binary Gate提出的一种优化方案,使用reinforce的方法来训练二值化权重。

实验
实验分别在Cifar-10和ImageNet上做了实验



















 934
934











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









