







https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/6-1-actor-critic/
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
【强化学习】Actor-Critic详解
之前在强化学习分类中,我们提到了Policy-based与Value-based两种方式,然而有一种算法合并了Value-based (比如 Q learning) 和 Policy-based (比如 Policy Gradients) 两类强化学习算法,就是Actor-Critic方法
1、算法思想
Actor-Critic算法分为两部分,我们分开来看actor的前身是policy gradient他可以轻松地在连续动作空间内选择合适的动作,value-based的Qlearning做这件事就会因为空间过大而爆炸,但是又因为Actor是基于回合更新的所以学习效率比较慢,这时候我们发现可以使用一个value-based的算法作为Critic就可以实现单步更新。这样两种算法相互补充就形成了我们的Actor-Critic
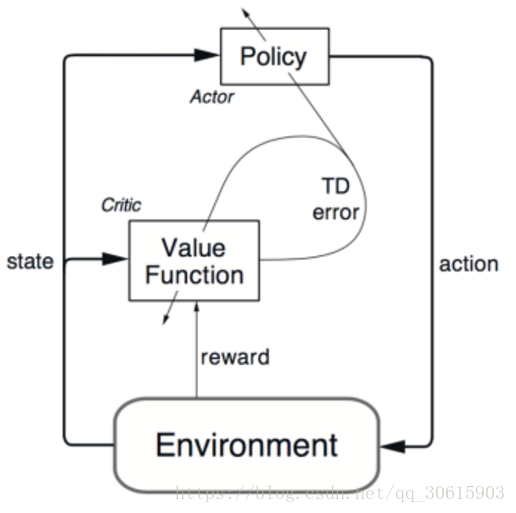
Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率。
Actor Critic优点:可以进行单步更新, 相较于传统的PG回合更新要快.
Actor Critic缺点:Actor的行为取决于 Critic 的Value,但是因为 Critic本身就很难收敛和actor一起更新的话就更难收敛了。(为了解决收敛问题, Deepmind 提出了 Actor Critic 升级版 Deep Deterministic Policy Gradient,后者融合了 DQN 的优势, 解决了收敛难的问题,之后我会详细解释这种算法)
2、公式推导
Actor(玩家):为了玩转这个游戏得到尽量高的reward,需要一个策略:输入state,输出action,即上面的第2步。(可以用神经网络来近似这个函数。剩下的任务就是如何训练神经网络,得更高的reward。这个网络就被称为actor)
Critic(评委):因为actor是基于策略policy的所以需要critic来计算出对应actor的value来反馈给actor,告诉他表现得好不好。所以就要使用到之前的Q值。(当然这个Q-function所以也可以用神经网络来近似。这个网络被称为critic。)
再提一下之前用过的符号
-策略 π ( s ) π(s) π(s)表示了agent的action,其输出是单个的action动作,而是选择动作的概率分布,所以一个状态下的所有动作概率加和应当为 1
- π ( a ∣ s ) π(a|s) π(a∣s)表示策略
首先来看Critic的策略值函数即策略 π \pi π的 V π ( s ) V_\pi(s) Vπ(s)具体推导方式请参考之前Qlearning的推导方式
V π ( s ) = E π [ r + γ V π ( s ′ ) ] V_\pi(s)=E_\pi[r + \gamma V_\pi(s')] Vπ(s)=Eπ[r+γVπ(s′)]
策略的动作值函数如下
Q π ( s , a ) = R s a + γ V π ( s ′ ) Q_π(s,a)=R^a_s+γV_π(s′) Qπ(s,a)=Rsa+γVπ(s′)
此处提出了优势函数A,优势函数表示在状态 s 下,选择动作 a 有多好。如果 action a 比 average 要好,那么,advantage function 就是 positive 的,否则,就是 negative 的。
A π ( s , a ) = Q π ( s , a ) − V π ( s ) = r + γ V π ( s ′ ) − V π ( s ) A_\pi(s,a)=Q_π(s,a)-V_\pi(s)= r + γV_π(s′) -V_\pi(s) Aπ(s,a)=Qπ(s,a)−Vπ(s)=r+γVπ(s′)−Vπ(s)
前置条件下面两个公式是等价的因为使用了likelihood ratio似然比的方法,所以可能各种资料写的不一样,大家注意不要被搞蒙了
∇ θ π θ ( s , a ) = π θ ( s , a ) ∇ θ π θ ( s , a ) π θ ( s , a ) = π θ ( s , a ) ∇ θ l o g π θ ( s , a ) ∇_θπ_θ(s,a)=π_θ(s,a)\frac{∇_θπ_θ(s,a)}{π_θ(s,a)}=π_θ(s,a)∇_θlogπ_θ(s,a) ∇θπθ(s,a)=πθ(s,a)πθ(s,a)∇θπθ(s,a)=πθ(s,a)∇θlogπθ(s,a)
接下来我们看Actor,这部分假设采取policy Gradient这样的话使用策略梯度定理
∇
θ
J
(
θ
)
=
∑
s
∈
S
d
(
s
)
∑
a
∈
A
π
θ
(
s
,
a
)
∇
θ
l
o
g
π
(
a
∣
s
;
θ
)
Q
π
(
s
,
a
)
∇_θJ(θ)=∑_{s∈S}d(s)∑_{a∈A}π_θ(s,a)∇_θlogπ(a|s;\theta)Q_{π}(s,a)
∇θJ(θ)=∑s∈Sd(s)∑a∈Aπθ(s,a)∇θlogπ(a∣s;θ)Qπ(s,a)
∇
θ
J
(
θ
)
=
E
π
θ
[
∇
θ
l
o
g
π
θ
(
s
,
a
)
Q
π
θ
(
s
,
a
)
]
∇_θJ(θ)=E_{π_θ}[∇_θlogπ_θ(s,a)Q_{π_θ}(s,a)]
∇θJ(θ)=Eπθ[∇θlogπθ(s,a)Qπθ(s,a)]
此处将
Q
π
(
s
,
a
)
Q_{π}(s,a)
Qπ(s,a)换成上文提到的
A
π
(
s
,
a
)
A_\pi(s,a)
Aπ(s,a)
∇
θ
J
(
θ
)
=
∑
s
∈
S
d
(
s
)
∑
a
∈
A
π
θ
(
s
,
a
)
∇
θ
l
o
g
π
(
a
∣
s
;
θ
)
A
π
(
s
,
a
)
∇_θJ(θ)=∑_{s∈S}d(s)∑_{a∈A}π_θ(s,a)∇_θlogπ(a|s;\theta)A_{\pi}(s,a)
∇θJ(θ)=∑s∈Sd(s)∑a∈Aπθ(s,a)∇θlogπ(a∣s;θ)Aπ(s,a)
∇
θ
J
(
θ
)
=
E
π
θ
[
∇
θ
l
o
g
π
θ
(
s
,
a
)
A
π
θ
(
s
,
a
)
]
∇_θJ(θ)=E_{π_θ}[∇_θlogπ_θ(s,a)A_{\pi_θ}(s,a)]
∇θJ(θ)=Eπθ[∇θlogπθ(s,a)Aπθ(s,a)]
更新公式如下
下面几种形式都是一样的所以千万不要蒙
θ
t
+
1
←
θ
t
+
α
A
π
θ
(
s
,
a
)
∇
θ
l
o
g
π
θ
(
s
,
a
)
\theta_{t+1}←\theta_t+\alpha A_{\pi_θ}(s,a) ∇_θlogπ_θ(s,a)
θt+1←θt+αAπθ(s,a)∇θlogπθ(s,a)
θ
t
+
1
←
θ
t
+
α
A
π
θ
(
s
,
a
)
∇
θ
π
(
A
t
∣
S
t
,
θ
)
π
(
A
t
∣
S
t
,
θ
)
\theta_{t+1}←\theta_t+\alpha A_{\pi_θ}(s,a)\frac{∇_θπ(A_t|S_t,\theta)}{π(A_t|S_t,\theta)}
θt+1←θt+αAπθ(s,a)π(At∣St,θ)∇θπ(At∣St,θ)
θ
t
+
1
←
θ
t
+
α
(
r
+
γ
V
π
(
s
t
+
1
)
−
V
π
(
s
t
)
)
∇
θ
π
(
A
t
∣
S
t
,
θ
)
π
(
A
t
∣
S
t
,
θ
)
\theta_{t+1}←\theta_t+\alpha (r + γV_π(s_{t+1}) -V_\pi(s_t))\frac{∇_θπ(A_t|S_t,\theta)}{π(A_t|S_t,\theta)}
θt+1←θt+α(r+γVπ(st+1)−Vπ(st))π(At∣St,θ)∇θπ(At∣St,θ)
损失函数如下
A可看做是常数所以可以求和平均打开期望,又因为损失函数要求最小所以加个"-"变换为解最小的问题
Actor:
L
π
=
−
1
n
∑
i
=
1
n
A
π
(
s
,
a
)
l
o
g
π
(
s
,
a
)
L_\pi =-\frac{1}{n}\sum_{i=1}^nA_{\pi}(s,a) logπ(s,a )
Lπ=−n1∑i=1nAπ(s,a)logπ(s,a)
值迭代可以直接使用均方误差MSE作为损失函数
Critic:
L
v
=
1
n
∑
i
=
1
n
e
i
2
L_v = \frac{1}{n}\sum_{i=1}^ne_i^2
Lv=n1∑i=1nei2
n-step的伪代码如下

3、代码实现
import numpy as np
import tensorflow as tf
import gym
np.random.seed(2)
tf.set_random_seed(2) # reproducible
# 超参数
OUTPUT_GRAPH = False
MAX_EPISODE = 3000
DISPLAY_REWARD_THRESHOLD = 200 # 刷新阈值
MAX_EP_STEPS = 1000 #最大迭代次数
RENDER = False # 渲染开关
GAMMA = 0.9 # 衰变值
LR_A = 0.001 # Actor学习率
LR_C = 0.01 # Critic学习率
env = gym.make('CartPole-v0')
env.seed(1)
env = env.unwrapped
N_F = env.observation_space.shape[0] # 状态空间
N_A = env.action_space.n # 动作空间
class Actor(object):
def __init__(self, sess, n_features, n_actions, lr=0.001):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.a = tf.placeholder(tf.int32, None, "act")
self.td_error = tf.placeholder(tf.float32, None, "td_error") # TD_error
with tf.variable_scope('Actor'):
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.acts_prob = tf.layers.dense(
inputs=l1,
units=n_actions, # output units
activation=tf.nn.softmax, # get action probabilities
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='acts_prob'
)
with tf.variable_scope('exp_v'):
log_prob = tf.log(self.acts_prob[0, self.a])
self.exp_v = tf.reduce_mean(log_prob * self.td_error) # advantage (TD_error) guided loss
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(-self.exp_v) # minimize(-exp_v) = maximize(exp_v)
def learn(self, s, a, td):
s = s[np.newaxis, :]
feed_dict = {self.s: s, self.a: a, self.td_error: td}
_, exp_v = self.sess.run([self.train_op, self.exp_v], feed_dict)
return exp_v
def choose_action(self, s):
s = s[np.newaxis, :]
probs = self.sess.run(self.acts_prob, {self.s: s}) # 获取所有操作的概率
return np.random.choice(np.arange(probs.shape[1]), p=probs.ravel()) # return a int
class Critic(object):
def __init__(self, sess, n_features, lr=0.01):
self.sess = sess
self.s = tf.placeholder(tf.float32, [1, n_features], "state")
self.v_ = tf.placeholder(tf.float32, [1, 1], "v_next")
self.r = tf.placeholder(tf.float32, None, 'r')
with tf.variable_scope('Critic'):
l1 = tf.layers.dense(
inputs=self.s,
units=20, # number of hidden units
activation=tf.nn.relu, # None
# have to be linear to make sure the convergence of actor.
# But linear approximator seems hardly learns the correct Q.
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='l1'
)
self.v = tf.layers.dense(
inputs=l1,
units=1, # output units
activation=None,
kernel_initializer=tf.random_normal_initializer(0., .1), # weights
bias_initializer=tf.constant_initializer(0.1), # biases
name='V'
)
with tf.variable_scope('squared_TD_error'):
self.td_error = self.r + GAMMA * self.v_ - self.v
self.loss = tf.square(self.td_error) # TD_error = (r+gamma*V_next) - V_eval
with tf.variable_scope('train'):
self.train_op = tf.train.AdamOptimizer(lr).minimize(self.loss)
def learn(self, s, r, s_):
s, s_ = s[np.newaxis, :], s_[np.newaxis, :]
v_ = self.sess.run(self.v, {self.s: s_})
td_error, _ = self.sess.run([self.td_error, self.train_op],
{self.s: s, self.v_: v_, self.r: r})
return td_error
sess = tf.Session()
actor = Actor(sess, n_features=N_F, n_actions=N_A, lr=LR_A) # 初始化Actor
critic = Critic(sess, n_features=N_F, lr=LR_C) # 初始化Critic
sess.run(tf.global_variables_initializer()) # 初始化参数
if OUTPUT_GRAPH:
tf.summary.FileWriter("logs/", sess.graph) # 输出日志
# 开始迭代过程 对应伪代码部分
for i_episode in range(MAX_EPISODE):
s = env.reset() # 环境初始化
t = 0
track_r = [] # 每回合的所有奖励
while True:
if RENDER: env.render()
a = actor.choose_action(s) # Actor选取动作
s_, r, done, info = env.step(a) # 环境反馈
if done: r = -20 # 回合结束的惩罚
track_r.append(r) # 记录回报值r
td_error = critic.learn(s, r, s_) # Critic 学习
actor.learn(s, a, td_error) # Actor 学习
s = s_
t += 1
if done or t >= MAX_EP_STEPS:
# 回合结束, 打印回合累积奖励
ep_rs_sum = sum(track_r)
if 'running_reward' not in globals():
running_reward = ep_rs_sum
else:
running_reward = running_reward * 0.95 + ep_rs_sum * 0.05
if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering
print("episode:", i_episode, " reward:", int(running_reward))
break

















 4624
4624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









