






LTP(Language Technology Platform) 提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。(分词/词性/命名实体/语义角色/依存句法/语义依存,这几类功能的具体信息见链接4)
相关链接:
paper: N-LTP: An Open-source Neural Language Technology Platform for Chinese
link: https://arxiv.org/pdf/2009.11616.pdf
code: HIT-SCIR/ltp: Language Technology Platform (github.com)
底层模型:
其内核为基于Electra的联合模型:由一个共享编码器和几个处理不同任务的解码器组成。整个框架共享一个编码器,每个任务使用各自的任务解码器,所有任务使用一个联合学习机制同时进行优化。

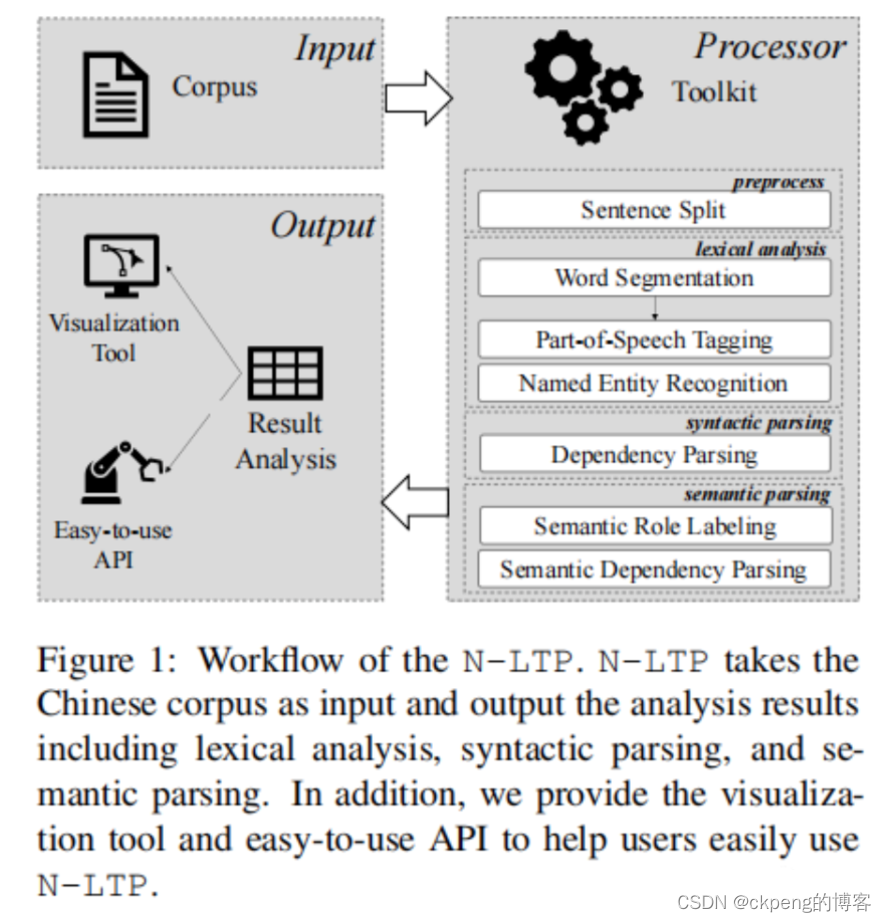
工作流程图:
快速使用/说明
import torch
from ltp import LTP
# 默认 huggingface 下载,可能需要代理
ltp = LTP("LTP/small") # 默认加载 Small 模型
# 也可以传入模型的路径,ltp = LTP("/path/to/your/model")
# /path/to/your/model 应当存在 config.json 和其他模型文件
# git上下载
# 将模型移动到 GPU 上
if torch.cuda.is_available():
# ltp.cuda()
ltp.to("cuda")
# 自定义词表(用于分词,可添加需要分词的关键词)
ltp.add_word("汤姆去", freq=2)
ltp.add_words(["外套", "外衣"], freq=2)
# 分词 cws、词性 pos、命名实体标注 ner、语义角色标注 srl、依存句法分析 dep、语义依存分析树 sdp、语义依存分析图 sdpg
output = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws", "pos", "ner", "srl", "dep", "sdp", "sdpg"])
# 使用字典格式作为返回结果
print(output.cws) # print(output[0]) / print(output['cws']) # 也可以使用下标访问
# [['他', '叫', '汤姆', '去', '拿', '外衣']]
print(output.pos)
# [['r', 'v', 'nh', 'v', 'v', 'n']]
print(output.sdp)
# [[('Nh', '汤姆')]]
# 使用感知机算法实现的分词、词性和命名实体识别,速度比较快,但是精度略低
ltp = LTP("LTP/legacy")
# cws, pos, ner = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws", "ner"]).to_tuple() # error: NER 需要 词性标注任务的结果
cws, pos, ner = ltp.pipeline(["他叫汤姆去拿外衣。"], tasks=["cws", "pos", "ner"]).to_tuple() # to tuple 可以自动转换为元组格式
# 使用元组格式作为返回结果
print(cws, pos, ner)词性明细

命名实体
















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









