






1、算法简介:
2014年6⽉,Alex Rodriguez和Alessandro Laio在Science上发表了⼀篇名《Clustering by fast search and find of density peaks》的文章,提供了⼀种简洁而优美的聚类算法,是⼀种基于密度的聚类方法,可以识别各种形状的类簇,并且参数很容易确定。它克服了DBSCAN中不同类的密度差别大、邻域范围难以设定的问题,鲁棒性强。
2、算法对于数据集的假设:
在这个算法中对数据集有两条假设:
1.数据集在空间分布并不均匀,数据中局部高密度点被一些局部低密度点包围
2.数据集中局部高密度点之间的相对距离较大
3、算法相关公式:
1)密度计算: 其中
![]() ,密度计算有两种计算方式:1.传统的欧式距离计算距离,将距离小于点的数量直接作为密度,2.计算欧式距离并计算高斯函数值,将所有点值的和作为密度。
,密度计算有两种计算方式:1.传统的欧式距离计算距离,将距离小于点的数量直接作为密度,2.计算欧式距离并计算高斯函数值,将所有点值的和作为密度。
2)局部高密度点距离计算: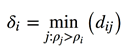 ,当dij是密度最高的点时:
,当dij是密度最高的点时:![]() 。
。
4、算法过程
1)计算数据密度
根据设定的截断距离,计算每个数据点的局部密度
2)局部高密度点距离
计算每个点到高于自身局部密度值点的最小距离。得到
3)根据密度与距离估计中心点
对每⼀个点,绘制出局部密度与高局部密度点距离
的散点图

可以看出上图中的大部分数据都具有较小的距离,但是有一些数据有着较大的距离与密度,这样的点我们选择为聚类中心点。同时将有着较高距离较低密度的点确定为异常点

4)划分剩余数据点(聚类过程)
把每个数据点归类到比他们的密度更大的最相近的类中心所属的类别中。

代码实现:
1)密度计算
%% 密度计算函数
function data_density=cal_density(data,cut_dist)
data_len=size(data,1);
data_density=zeros(1,data_len);
for idata_len=1:data_len
temp_dist=pdist2(data,data(idata_len,:));
data_density(idata_len)=sum(exp(-(temp_dist./cut_dist).^2));
end
end2)距离计算
%% 计算delta
function data_delta=cal_delta(data,data_density)
data_len=size(data,1);
data_delta=zeros(1,data_len);
for idata_len=1:data_len
index=data_density>data_density(idata_len);
if sum(index)~=0
data_delta(idata_len)=min(pdist2(data(idata_len,:),data(index,:)));
else
data_delta(idata_len)=max(pdist2(data(idata_len,:),data));
end
end
end3)聚类中心点寻找
%% 寻找聚类中心点
function [center,center_index]=find_center(data,data_delta,data_density,cut_dist)
R=data_density.*data_delta;
[sort_R,R_index]=sort(R,"descend");
gama=abs(sort_R(1:end-1)-sort_R(2:end));
[sort_gama,gama_idnex]=sort(gama,"descend");
gmeans=mean(sort_gama(2:end));
%寻找疑似聚类中心点
temp_center=data(R_index(gama>gmeans),:);
temp_center_index=R_index(gama>gmeans);
%进一步筛选中心点
temp_center_dist=pdist2(temp_center,temp_center);
temp_center_len=size(temp_center,1);
center=[];
center_index=[];
%判断中心点之间距离是否小于2倍截断距离并中心点去重
for icenter_len=1:temp_center_len
temp_index=find(temp_center_dist(icenter_len,:)<2*cut_dist);
[~,max_density_index]=max(data_density(temp_center_index(temp_index)));
if sum(center_index==temp_center_index(temp_index(max_density_index)))==0
center=[center;temp_center(temp_index(max_density_index),:)];
center_index=[center_index,temp_center_index(temp_index(max_density_index))];
end
% center(icenter_len,:)=temp_center(temp_index(max_density_index),:);
end
end4)聚类过程
%% 聚类算法
function cluster=Clustering(data,center,center_index,data_density)
data_len=size(data,1);
data_dist=pdist2(data,data);
cluster=zeros(1,data_len);
% 标记中心点序号
for i=1:size(center_index,2)
cluster(center_index(i))=i;
end
% 对数据密度进行降序排序
[sort_density,sort_index]=sort(data_density,"descend");
for idata_len=1:data_len
%判断当前数据点是否被分类
if cluster(sort_index(idata_len))==0
near=sort_index(idata_len);
while 1
near_density=find(data_density>data_density(near));
near_dist=data_dist(near,near_density);
[~,min_index]=min(near_dist);
if cluster(near_density(min_index))
cluster(sort_index(idata_len))=cluster(near_density(min_index));
break;
else
near=near_density(min_index);
end
end
end
end
end













 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









