







二分类
二分类的损失函数一般使用交叉熵,二分类的label不用编码成onehot
在二分的情况下,模型最后需要预测的结果只有两种情况,对于每个类别我们的预测得到的概率为 p 和 1−p ,此时表达式为的底数是 loge():
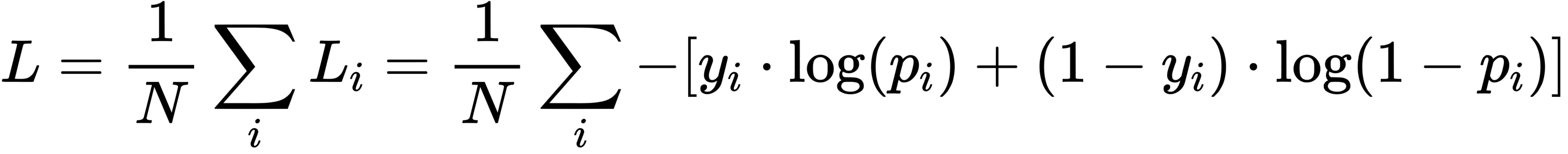
其中:
-yi表示样本i的label,正类为 1 ,负类为 0,由于只有两类,0和1就能单独表示标签了,不用独热编码。
- pi表示样本i预测为正类的概率
多分类
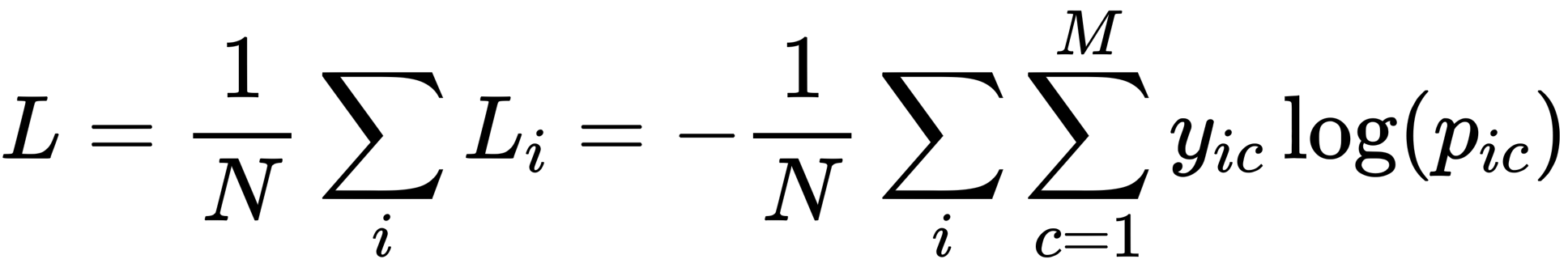
多分类由于每条样本只属于一个或多个类别,算loss的时候只需要算样本属于的那个类别的loss,上面公式中yic就是一个指示函数,取值为0或者1。属于该类别就为1,否则为0,所以其他不属于该类别的loss为0️⃣。
binary_crossentropy 这里会返回跟输入一样的batch,如果一个batch内有多个样本,会先把多个样本求平均再返回。这里的y_true输入的是01的标签,y_pred输入的是经过激活函数归一化到【0,1】的概率分布
sigmoid_cross_entropy_with_logits 这个函数的区别就是,这里的y_pred是直接神经网络的最后一层输出,叫logits,他会自动先求一个sigmoid的,再求交叉熵
label = [[1], [0], [1], [0], [0], [0], [0]]
pred = [[0.8], [0.33], [0.77], [0.66], [0.55], [0.002], [0.213]]
比如有这么一个训练样本,维度是【7,1】表示有7个batch,每个batch内一个样本,所以返回的loss维度就是跟batch一样的,知识少了第二维,loss维度是【7,】,没有第二维
第一个样本的loss =-1*ln(0.8),第二个loss=-(1-0)*ln(1-0.33) 这里是直接套用公式,模型预估的其实是正样本的概率,这里的label=0,预估的概率是0.33,那么正样本的概率就是1-0.33
然后依次计算,算出来的和用tensorflow 算法前几位是一样的,因为精度问题,后几位不一样。
import tensorflow as tf
import numpy as np
label = [[1], [0], [1], [0], [0], [0], [0]]
pred = [[0.8], [0.33], [0.77], [0.66], [0.55], [0.002], [0.213]]
pred_after_sigmoid = tf.nn.sigmoid(pred)
print(pred_after_sigmoid)
tf_loss = tf.keras.losses.binary_crossentropy(y_true=tlabel,y_pred=pred)
print("tf_loss", tf_loss)
tf_loss_aftersigmoid = tf.keras.losses.binary_crossentropy(y_true=label,y_pred=pred_after_sigmoid)
print("tf_loss_aftersigmoid", tf.expand_dims(tf_loss_aftersigmoid, axis=1))
cal_loss = -1 * label * tf.math.log(pred)
print(cal_loss)
print(-1 * np.log(0.67))
print(-1 * tf.math.log(tf.cast(0.6899745, dtype=tf.float64)))
loss1 = tf.nn.sigmoid_cross_entropy_with_logits(tf.cast(label, tf.float64), tf.cast(pred, tf.float64))
print(loss1)
print("*" * 1000)
label2 = tf.constant([[1, 1], [0, 0]], dtype=tf.int32)
pred2 = tf.constant([[0.7, 0.6], [0.3, 0.2]], dtype=tf.float32)
loss2 = tf.keras.losses.binary_crossentropy(y_true=label2, y_pred=pred2)
print(loss2)
print("*" * 1000)
label3 = tf.constant([[1], [1], [0], [0]], dtype=tf.int32)
pred3 = tf.constant([[0.7], [0.6], [0.3], [0.2]], dtype=tf.float32)
loss3 = tf.keras.losses.binary_crossentropy(y_true=label3, y_pred=pred3)
print(loss3)















 1687
1687











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









