






论文:https://arxiv.org/pdf/1808.06670.pdf
摘要:
许多表示学习只使用已探索过的数据空间(称为像素级别),当一小部分数据十分关心语义级别时,该表示学习将不利于训练。论文提出了无监督表示学习,直接学习和估计信息内容,统计或结构约束。论文最大化输入信息和高级特征向量之间的互信息与通过对抗匹配先验分布来控制表示学习的特征。
介绍:
人工智能单元在预测和规划时不应该停留在像素级别或者传感器级别,而是应该在抽象表示级别。像素级别的非监督机器学习可以在不捕捉语义信息时表现的非常出色,但是它们并不是好的表示。解决学习一个训练目标的表示而不适用提前定义好的输入,一个简单解决办法是直接训练表示学习的函数,最大化输入和输出之间的互信息。在论文 MINE https://arxiv.org/pdf/1801.04062.pdf 中,提供了高效计算高维度神经网络输入输出之间互信息的计算解决方案。直接最大化输入和表示之间的互信息并不能有效的学习有用的表示信息,但是最大化表示和当地输入之间的平均互信息可以极大的提升表示质量。除了互信息外,表示学习的特征,比如结构也非常重要,论文结合最大化互信息和匹配先验(类似与AAE算法)来达到好的表现。论文主要贡献有:① 提出 DIM 算法,使用互信息神经网络估计明确的最大化输入和已经学习的高维度表示之间的互信息。② 最大化互信息可以全局或者当地信息优先,协调使得在表示和分类或者重建任务中更高效。③ 使用对抗学习约束表示信息的先验分布的统计特性 ④ 引入了两个提升表示学习质量的方法,一个是MINE 另一个是 https://arxiv.org/pdf/1710.05050.pdf 。
生成模型:
生成模型依赖重建和对抗,重建误差与互信息的联系可以如下表示
其中,X 和 Y 分别代表随机变量的输入和表示,而表示重建误差,
表示编码器的边缘分布的熵。在双向对抗模型(bi-directional adversarial models)训练编码器和解码器来匹配表示的联合分布,这样操作会增加边缘分布的熵或者减小重建误差。在 GAN 里面采用生成和对抗模型,辨别器来辨别真假图片时需要很高的互信息值,但是在高维度情境下,学习生成模型非常困难。同时,图片中不是所有信息都很重要,有时候一张图片只有一小部分的特征就可以表示整个图片的重要信息。
免解码器模型:
依赖最大化似然函数的算法(arXiv:1410.8516,2014),但该算法为了成立一个似然目标函数严格限制了编码器和输出空间。深度聚类算法(Unsupervised deep embedding for clustering analysis)在非监督聚类中表现优异,但是用途不广阔。NAT算法将表示作为一个监督学习中的噪声目标来进行非监督学习,不需要生成模型,但是需要一个推断机制将输入和噪声排列起来。NAT算法需要大量的采样,并需要训练先验分布,同时NAT算法如何影响输入数据的大小和表示的维度并不清楚。
互信息估计:
INFOMAX 主张最大化输入和输出之间的互信息。MINE 算法学习连续变量的神经网络估计的互信息,通过最大化编码器的输入和输出来约束变量和用于学习更好的生成模型。论文使用 KL 散度,使用层级化输入的结构来提升表示分类的能力。DIM 使用特征映射对应区域的层级化的采样,使用 1x1 的卷积来表示当地的小块区域和全局变量之间的互信息估计。
DIM:
定义式如下:
是一个关于 y 的 Dirac 函数。
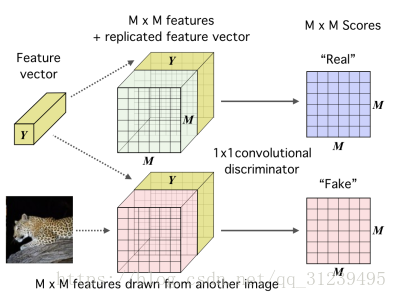
如左图所示为编码器的示意图:图像信息被编码为一个卷积神经网络,卷积过程直到映射 MXM 对应了输入的 MXM,使用全连接整合成一个特征向量,目标是训练这个神经网络,这个神经网络的输入的相关信息可在高层特征中抽离出来。
如上右图所示,我们提出一个高维向量 Y 和一个低级别 MXM 的映射通过一个鉴别器来打分,鉴别器由神经网络,全连接网络组成,假的采样通过与另一个图像的相同特征向量结合而描绘出来。
互信息的估计和最大化:
其中是一个基于参数 w 的鉴别函数,论文同时最大化和估计互信息
,如下公式:
因为编码器和MINE算法在优化目标函数的时候使用类似的计算方法,所以论文结合了最初的两种网络结构:
论文使用 JSD 散度公式,结合解码器和MINE的目标函数,得到如下公式:
其中,y(x)是一个更级别的表示,x' 是与 y 不相关的另外一个输入,,JSD散度公式更适合本论文最大化互信息,① JSD 的上届 log2,在计算时不会产生特别大的数 ② JSD 的梯度是无偏的。
最大化当地互信息:
上述公式是最大化输入和输出的互信息的,但是根本上我们的任务并不需要那么做,比如当地像素的噪声,如果最终的目标是分类,那么这个表示就不太优异。为了保证表示模型能够适应分类任务,我们最大化高级表示和当地小范围图像的平均互信息。因为相同的表示鼓励更高的互信息,某些区域的数据会共用了一部分数据,解码器可以选择输入信息的类型,但是当解码器通过某些特定输入信息时,不会因为其他的区域不包含上述噪声而增大互信息,这将使得解码器更倾向于输入中共享的信息。
如下图所示:最大化当地特征和高级特征向量之间的互信息,论文将图像编码成一个映射,该映射包含数据的一些结构特征,并且将该映射整合成一个全局特征向量(在上图可以看到)这个特征向量在每一个区域都连结低级特征映射,一个1x1的卷积鉴别器用来给真实图片和假图片打分,假图片是通过另外一张图像生成的映射而生成的。
公式转化如下:
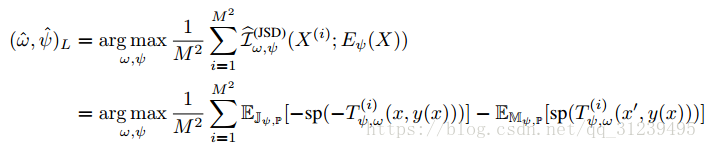
论文提出,当地互信息最大化虽然引入了真实和虚假图片的概率,但是并没有显著提高效果。
匹配表示与先验分布:
好的表示学习应该是简洁的、独立的、无纠缠的(disentangled)或者独立可控的。如图所示:训练解码器是为了疑惑鉴别器,使之不能分辨出真的图片和假的图片。真的采样取自先验分布,假的采样取自编码器。
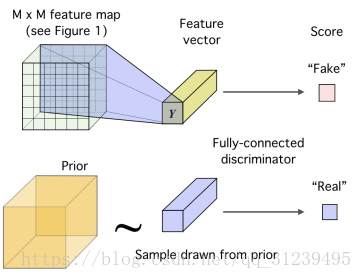
公式如下:训练编码器最小化散度
将全局互信息,区域互信息和先验分布匹配加到一起,得到如下公式:
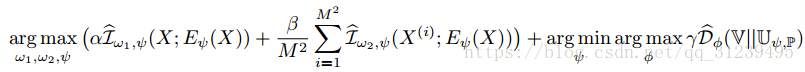
w1 和 w2 分别是鉴别器全局和区域目标的参数,α、β 和 γ 是超参数。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









