






论文:https://arxiv.org/pdf/1801.04062.pdf
摘要:
论文指出,可以使用神经网络梯度下降算法对高维度连续随机变量间的互信息进行估计,MINE 算法在维度上和样本大小上是线性可测量的,可使用反向传播算法训练。MINE算法可以最大或者最小化互信息,提升生成模型的对抗训练,突破监督学习分类任务的瓶颈。
介绍:
互信息的定义如下公式所示:![]() 是一个联合概率分布,
是一个联合概率分布,![]() 与
与![]() 是边缘概率分布,互信息用于捕捉变量之间的统计独立性。
是边缘概率分布,互信息用于捕捉变量之间的统计独立性。
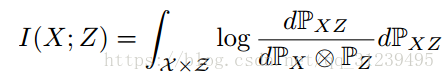
由于电脑计算只能计算离散变量或者在限定场景条件,一般的方法是无参数的(比如基于向量的似然估计,核密度估计等),或者依赖于高斯分布进行近似,但是上述方法都在度量采样样本大小和维度上表现不够好,也就不能被成为通用目的问题解决方案。论文提出了使用变量之间的KL散度来度量互信息,该KL散度方法也用于对抗网络,对对抗网络是GAN的基础(GAN训练一个生成模型而不需要明显的数据分布的假设)。论文主要贡献有以下几点:① 论文引入了MINE算法,MINE算法可度量,灵活,可使用反向传播算法训练并提供理论分析依据。② 论文使用互信息估计,并进行最大和最小化 ③ 论文提升了对抗生成网络的重建和推断能力 ④ 论文使用的Information Bottleneck 方法优异与 variational bottleneck方法。
背景:
互信息用来描述随机变量之间的信息相关度,互信息越大,变量之间的相关度越强,公式可以转化如下:
![]()
其中H是熵,熵可以理解为惊喜度,若越是惊喜度越高,熵越大,事情发生的概率越低。互信息的公式还可以写成如下形式:![]() 散度表示两个分布之间的距离,距离越远,散度越大。
散度表示两个分布之间的距离,距离越远,散度越大。
![]()
![]() 定义如下:
定义如下:
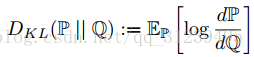
散度的两种表示:
MINE算法一个关键技巧就是使用了两种散度表示方式,如下公式所示:
![]()
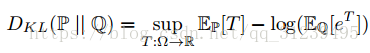
![]()
![]()
互信息神经网络估计:
论文提出使用神经网络进行估计,公式如下:
![]()
![]() 是一个神经网络互信息,定义如下:公式(10)使用联合分布
是一个神经网络互信息,定义如下:公式(10)使用联合分布![]() 与边缘分布
与边缘分布![]() ,
,![]() 可以通过梯度下降求进行最大化处理,神经网络保证了该公式可以以任意精度近似逼近互信息公式。
可以通过梯度下降求进行最大化处理,神经网络保证了该公式可以以任意精度近似逼近互信息公式。
![]()
MINE的定义:此公式也可以通过![]() 定义。但是
定义。但是![]() 相对于
相对于![]() 有更低的下届,会导致估计更加宽松不准确,SGD(Stochastic Gradient Decent)应用与MINE算法是偏置的。(后续论证)
有更低的下届,会导致估计更加宽松不准确,SGD(Stochastic Gradient Decent)应用与MINE算法是偏置的。(后续论证)
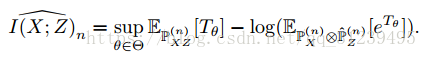
论文算法如下:

初始化神经网络参数![]() ;
;
从联合分布中采样:![]() ,
,
从边缘分布中采样:![]() ,
,
通过![]() 估计下届:
估计下届:![]() ,
,
评估偏置,对梯度进行更正:![]()
更新梯度:![]()
直到收敛
在上述算法中,对梯度进行更正的公式如下:
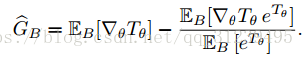
使用moving average 可以减少上述公式第二项的偏置,对梯度的偏置进行更正可以很大程度上提高MINE的表现.
理论依据:一致性和采样复杂性的论证是为了使得MINE算法进行神经网络估计更有理论依据。
consistency(一致性):
![]()
sample complexity(采样复杂性):
![]()
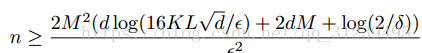
思考:
MINE算法应该是和其他的生成模型算法结合使用,就想HER算法和DDPG联合使用一样?

















 7174
7174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









