






弱监督视频多目标实例分割新SOTA(代码已开源):
Paper: Solve the Puzzle of Instance Segmentation in Videos: A Weakly Supervised Framework with Spatio-Temporal Collaboration
PDF: https://arxiv.org/pdf/2212.07592.pdf
Code: https://github.com/ylqi/STC-Seg

众所周知,视频多目标跟踪与分割(Multi-Object Tracking and Segmentation,MOTS)的标注需要给每个视频帧中的每个目标描绘轮廓(Mask-Level Label),工作量十分巨大。我们希望仅仅利用更弱一级的标注——目标检测框(Box-Level Label),作为标注信息来训练视频多目标分割模型。
在图像弱监督多目标分割中,因为边界信息的缺乏,仅仅使用Box-Level的标注很难训练模型预测出较好的轮廓;然而在视频中,视频的时空信息往往包含了大量的轮廓信息,因此我们可以利用时空分析方法,包括视频深度估计方法、光流预测方法,来提取出目标的轮廓特征。
基于上述思路,STC-Seg[1]首先利用自监督的视频深度估计和光流预测方法获得深度(Depth)和光流(Optical Flow),利用它们生成Pseudo-Label来配合Box-Label的标注:
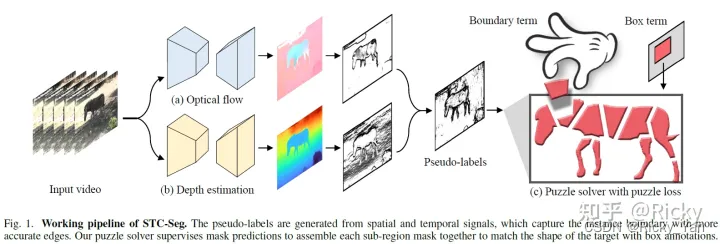
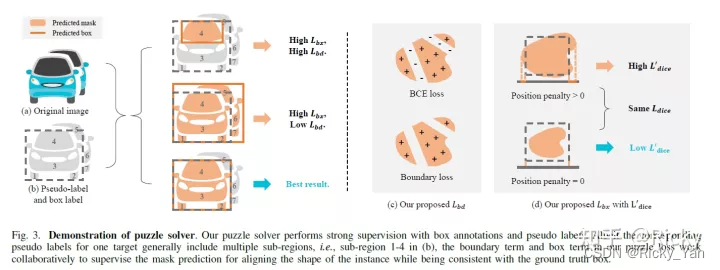
STC-Seg的损失函数(Loss)包括两项:(1)Boundary Term(2)Box Term。前者负责Pseudo-Label的监督,后者负责Box-Label的监督,像拼图一样将Pseudo-Label里的一块一块拼成一个完整的Mask。方法的系统框架如下:
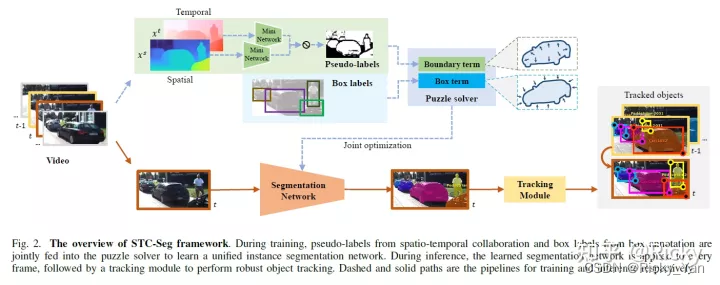
其中的目标分割网络(Segmentation Network)可以选取任何多目标分割网络,例如CondInst[2]。
损失函数中的Boundary Term利用Pseudo-Label的负采样像素点(相似度高的区域,即非轮廓区域)来训练模型(其实就是去掉了正样本部分的交叉熵):
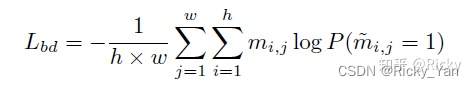
为了平衡Boundary Term导致预测的Mask往外扩的趋势,在Box Term的损失函数中,STC-Seg在Dice Loss的基础上做了改动:
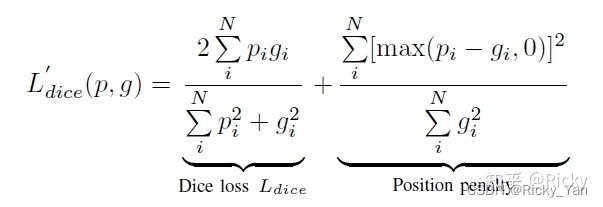
最终Box Term和Boundary Term相互约束实现平衡:
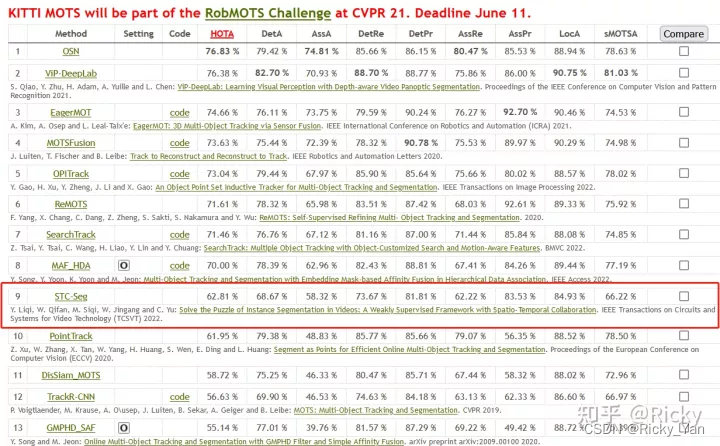
在KITTI MOTS的官网榜单上,弱监督的STC-Seg的效果超越了经典的全监督学习的方法PointTrack和TrackR-CNN:
可以看到轮廓预测地非常丝滑(而 TrackR-CNN 和 MaskTrack R-CNN 都不那么贴合真实物体):

References
[1] Yan, Liqi, et al. “Solve the Puzzle of Instance Segmentation in Videos: A Weakly Supervised Framework with Spatio-Temporal Collaboration.” IEEE Transactions on Circuits and Systems for Video Technology (2022).
[2] Z. Tian, C. Shen, and H. Chen, “Conditional convolutions for instance segmentation,” in ECCV, 2020.















 5908
5908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









