







Spark推荐系统,干货,心得
点击上方蓝字关注~
在之前的文章有发一篇关于spark推荐系统,里面介绍了一套推荐系统实现的简单流程,其中在推荐算法中召回部分常用的有协同过滤,协同过滤简单可以理解为通过用户的行为进行推荐商品(啤酒纸尿布的故事) ,也可以用来找用户之间,物品之间的相似度。
以下是通过spark2.0实现在A类与B类两类商品中,通过用户行为找出A类与B类商品的相似度,进行推荐
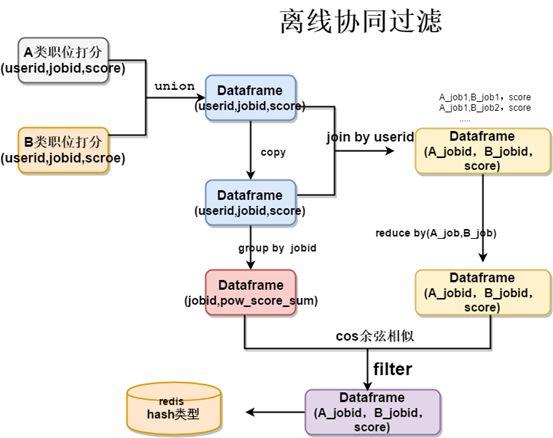
1、将每个用户对每个商品进行打分(打分可以通过,比如用户浏览就是1分,用户假如购物车2分,用户收藏3分,用户支付4分),形成user-item-score矩阵
2、copy一份user-item-score矩阵,与原始user-item-score矩阵按照userid进行join,可以形成
item-item-score矩阵
3、user-item-score矩阵按照itemid进行group操作形成每个itemid的平方 和的得分开方
4、将第2步的item-item-score,reducebykey操作(key为(item,item)) ,相当于把相同的item,item的score求和
5、将步骤3与步骤4的结果进行求cos相似度
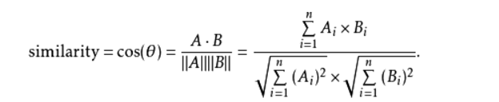
(余弦相似度公式)
6、将item与item相似度矩阵存入redishash类
使用:如果一个用户购买item1,通过查询redis获取与item1相似的其他items,将其他items 取topN进行推荐
spark2.0代码实现
1、商品商品推荐
import breeze.numerics.{pow, sqrt}
import com.badou.common.Conf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{col, udf}
object MyItemCf {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("MyItemCf").master("local")
.enableHiveSupport()
.config("spark.sql.warehouse.dir", Conf.WAREHOUSE_LOCATION).getOrCreate()
val userItemDf = spark.sql("select user_id,cast (item_id as bigint),cast(rating as double) from udata limit 100")
userItemDf.show()
val userItemDf2 = spark.sql("select user_id as user_id2,cast(item_id as bigint) as item_id2,cast(rating as double) as rating2 from udata")
userItemDf2.show()
val joinDf = userItemDf.join(userItemDf2, userItemDf("user_id") === userItemDf2("user_id2"))
.filter("item_id < item_id2")
joinDf.show()
import spark.implicits._
//user_id,score_id
val userScoreSum = userItemDf.rdd.map(x => (x(1).toString, x(2).toString)).groupByKey()
.mapValues(x => sqrt(x.toArray.map(line => pow(line.toDouble, 2)).sum))
val df_item_sum = userScoreSum.toDF("item_id_sum", "rating_sqrt_sum")
// //定义udf 两列进行相乘
val product_udf = udf((s1: Int, s2: Int) => s1.toDouble * s2.toDouble)
val df_product = joinDf.withColumn("rating_product", product_udf(col("rating"), col("rating2")))
.select("item_id", "item_id2", "rating_product")
val df_sim_group = df_product.groupBy("item_id", "item_id2").agg("rating_product" -> "sum").withColumnRenamed("sum(rating_product)", "rating_sum_pro")
df_sim_group.show()
//
val df_sim = df_sim_group
.join(df_item_sum, df_sim_group("item_id") === df_item_sum("item_id_sum"))
.drop("item_id_sum")
.withColumnRenamed("rating_sqrt_sum", "rating_sqrt_item_id_sum")
.join(df_item_sum, df_sim_group("item_id2") === df_item_sum("item_id_sum"))
.drop("item_id_sum")
.withColumnRenamed("rating_sqrt_sum", "rating_sqrt_item_id2_sum")
val sim_udf = udf((pro: Double, s1: Double, s2: Double) => pro / (s1 * s2))
val df_res = df_sim.withColumn("sim", sim_udf(col("rating_sum_pro"), col("rating_sqrt_item_id_sum"), col("rating_sqrt_item_id2_sum"))).select("item_id", "item_id2", "sim")
df_res.show()
}
}
2、用户与用户推荐
package com.badou.alg
import breeze.numerics.{pow, sqrt}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.{col, udf}
object MyUserCf {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").enableHiveSupport().getOrCreate()
val userItemDf = spark.sql("select * from udata limit 100")
val userItemDf2 = spark.sql("select user_id as user_id2,item_id as item_id2,rating as rating2 from badou.udata")
val joinDf = userItemDf.join(userItemDf2, userItemDf("item_id") === userItemDf2("item_id2")).filter("user_id < user_id2")
// .groupBy("user_id", "user_id2")
/*
+-------+-------+------+---------+--------+--------+-------+
|user_id|item_id|rating|timestamp|user_id2|item_id2|rating2|
+-------+-------+------+---------+--------+--------+-------+
| 196| 242| 3|881250949| 721| 242| 3|
| 196| 242| 3|881250949| 720| 242| 4|
| 196| 242| 3|881250949| 500| 242| 3|
| 196| 242| 3|881250949| 845| 242| 4|
*/
import spark.implicits._
//user_id,score_id
val userScoreSum = userItemDf.rdd.map(x => (x(0).toString, x(2).toString)).groupByKey()
.mapValues(x => sqrt(x.toArray.map(line => pow(line.toDouble, 2)).sum))
val df_user_sum = userScoreSum.toDF("user_id_sum", "rating_sqrt_sum")
/*
+-----------+------------------+
|user_id_sum| rating_sqrt_sum|
+-----------+------------------+
| 273|17.378147196982766|
| 528|28.160255680657446|
| 584|17.916472867168917|
| 736|16.186414056238647|
| 456| 52.40229002629561|
| 312| 66.83561924602779|
*/
//定义udf 两列进行相乘
val product_udf = udf((s1: Int, s2: Int) => s1.toDouble * s2.toDouble)
val df_product = joinDf.withColumn("rating_product", product_udf(col("rating"), col("rating2")))
.select("user_id", "user_id2", "rating_product")
val df_sim_group = df_product.groupBy("user_id", "user_id2").agg("rating_product" -> "sum").withColumnRenamed("sum(rating_product)", "rating_sum_pro")
/*
+-------+--------+---------------+
|user_id|user_id2|rating_sum_pro |
+-------+--------+---------------+
| 296| 296 | 354832.0|
| 467| 467 | 77126.0|
| 691| 691 | 32030.0|
| 675| 675 | 18856.0|
*/
val df_sim = df_sim_group
.join(df_user_sum,df_sim_group("user_id")===df_user_sum("user_id_sum"))
.drop("user_id_sum")
.withColumnRenamed("rating_sqrt_sum","rating_sqrt_user_id_sum")
.join(df_user_sum,df_sim_group("user_id2")===df_user_sum("user_id_sum"))
.drop("user_id_sum")
.withColumnRenamed("rating_sqrt_sum","rating_sqrt_user_id2_sum")
df_sim.show()
// val df_user_sum1 = df_user_sum.withColumnRenamed("rating_sqrt_sum","rating_sqrt_sum1")
// val df_sim =df_sim_1.join(df_user_sum,df_product("user_id2")===df_user_sum("user_id_sum")).drop("user_id_sum")
val sim_udf = udf((pro:Double,s1:Double,s2:Double)=>pro/(s1*s2))
val df_res = df_sim.withColumn("sim",sim_udf(col("rating_sum_pro"),col("rating_sqrt_user_id_sum"),col("rating_sqrt_user_id2_sum"))).select("user_id","user_id2","sim")
df_res.show()
}
}
推荐阅读:
Spark推荐系统

长按识别二维码关注我们















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









