






- One-hot
- Bag of Words
- N-gram
- TF-IDF
上述方法都或多或少存在一定的问题:转换得到的向量维度很高,需要较长的训练实践;没有考虑单词与单词之间的关系,只是进行了统计。
与这些表示方法不同,深度学习也可以用于文本表示,还可以将其映射到一个低纬空间。其中比较典型的例子有:FastText、Word2Vec和Bert。
FastText
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络,输入层、隐含层和输出层。
fastText是建立在embedding上进行词嵌入的模型,embedding的原理与理解如下:
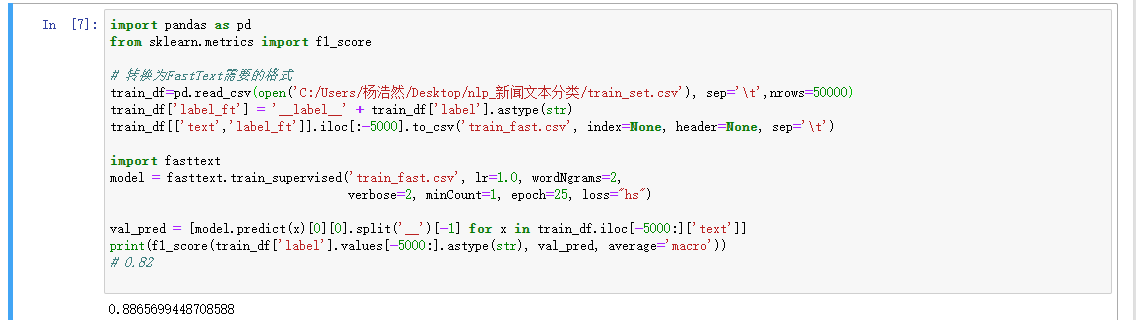
由于ONE-HOT在词嵌入中的若遇到字典词过多会导致词嵌入维度过高,矩阵过于稀疏的情况,并且无法考虑词与词之间的相似性,所以有了embedding,将句子样本的词进行one-hot,后拼接,得到词向量再进行低维嵌入,这就是EBD的基本方法: 接下来使用官方给出的BS进行实验,数据量使用4W5,验证集使用5000,得到F1_score为0.886
接下来使用官方给出的BS进行实验,数据量使用4W5,验证集使用5000,得到F1_score为0.886
 再更改代码,调整参数,使用K折交叉验证增加模型的泛化能力:
再更改代码,调整参数,使用K折交叉验证增加模型的泛化能力:

 使用的交叉验证反而不如直接拿尽量多的数据进行训练,所以可以知道本数据集是欠拟合状态,需要更多的数据进行训练,所以不进行交叉验证来直接调整参数,使用此参数的模型验证集效果最好:
使用的交叉验证反而不如直接拿尽量多的数据进行训练,所以可以知道本数据集是欠拟合状态,需要更多的数据进行训练,所以不进行交叉验证来直接调整参数,使用此参数的模型验证集效果最好: 验证集F1能达到0.9
验证集F1能达到0.9















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









