







第一章
机器学习:
就是从已知的数据中寻找规律,用来预测未知的样本
1.基本术语
1.1数据集
包含事物或对象某些方面特征的集合
1.2特征
模型输入需要数值化,对于较为抽象的输入,如声音等信息,需要将其转化为数值,才能输入模型。转化后的输入,被称作特征
1.3特征向量
就是把事物所有的属性转化为一组数值向量
1.4训练集
用于模型训练的训练数据集合
1.5测试集
最终用于评判算法模型效果的数据集合
1.6分类
预测值为类别(离散值)或在类别上的概率的分布
1.7回归
预测值为数值型(连续值)
1.8泛化能力
学习的模型适用于新样本的能力
2.假设空间
样本特征的所有可能假设组成
3.版本空间
存在着与训练集一致的假设集合
4.归纳偏好
机器学习在某种学习过程中在假设空间对假设进行的选择
5.机器学习应用
很多时候,我们有数据,希望找到规律,但规律很复杂,所以希望靠机器来挖掘规律
知道花朵的大小、颜色等信息,来判断花的种类
知道身体血压、血脂等指标,来预测是否患病
知道房屋的大小、位置等信息,来预测房价
知道企业的业务、规模等信息,来预测股价
第二章
2.1训练误差
在训练集上的误差
注意:在新样本的 误差称为泛化误差
2.2过拟合
1.模型失去了泛化能力。
2.模型在训练集和验证集上都有很好的表现,但在测试集上表现很差,一般认为是发生了过拟合
2.3欠拟合
模型没能建立起合理的输入输出之间的映射。当输入训练集中的样本时,预测结果与标注结果依然相差很大
2.4评估方法
2.4.1留出法
将数据集分为两个互斥集合,分别作为训练集和测试集
2.4.2交叉验证法
初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果
2.4.3自助法
对数据集A进行随机采样复制到数据集B中,然后再将该样本放回A中,重复M次采样,将B作为训练集,A作为测试集。
2.4.4调参与最终模型
先建立模型,并将模型权重随机初始化,之后将训练样本输入模型,可以得到模型预测值。使用模型预测值和真实标签可以计算损失值。通过loss可以计算梯度,调整权重参数,从而得到最终模型
2.5性能度量
2.5.1错误率
分类错误的样本数占总样本的比率
2.5.2精度
精度=1-错误率
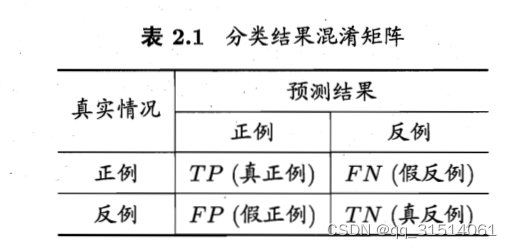
2.5.3查准率
也称为准确率
2.5.4查全率
也称为召回率
P为查准率,R为查全率
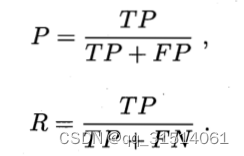
2.5.5F1
用于学习器比较谁优
2.5.6ROC曲线
横轴:假正例率
纵轴:真正例率
2.5.7AUC曲线
ROC曲线下的面积















 1013
1013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









