










-
2021-8-17
A high fidelity synthetic face framework for computer vision
CG人脸生成
略读。用的类似3DMM的方法,分成了identity和expression。这优化好像是数据集的基向量和系数同时进行。采样时用GMM. expression采用了51维表示和15个姿态参数,他的标注方法我没看懂。。。texture没细看,大概用了blender,用vae在albedo texture data上表示。Hair用3D hair strands对单根头发表示。用Blender’s particle hair system,头发区域会deformed根据head shape change。头发颜色用三个标量表示,proportion of melanin(黑色素), pheomelanin(褐色素)and proportion of gray hairs(白发比例)。Hair的表示采用了volumetric flow direction and occupancy based parametrization. 每一个hair包括两个UV maps 表示length和density,和一个volume map表示flow direction. 可以用PCA进行降维. 此外还有illumination部分,用了HDR(environment map?),并用PCA进行降维。
项目需要,3D头发表示







-
2021-8-16
NeRF++: Analyzing and Improving Neural Radiance Fields
arXiv2021
NeRF理论上可能得到病态解,之所以没得到,如果在一个shape-radiance ambiguity中,不同角度很高频,是因为Nerf的网络结果对于方向比较低频,因为方向在MLP的靠后层送入,且只用了4阶傅里叶。第二点,此外远方场景有远距离生成不好,生成好的距离偏近的tradeoff,所以采用两个NeRF,内层和外层分别渲染. 内层为世界原点周围的半径为1的球。 对于半径r大于1的外层渲染,可以写成四元组 ( x ′ , y ′ , z ′ , 1 / r ) (x', y', z', 1/r) (x′,y′,z′,1/r),其中 ( x ′ , y ′ , z ′ ) (x', y', z') (x′,y′,z′)是unit vector.
项目需要,经典文章









-
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
ECCV2020 多视角生成,3D渲染
这个Related Work可能有用: Niemeyer et al.和Sitzmann et al. 用不需要3Dshape标注来生成2D图像. Volumetric方法相比mesh-based method能表示更好,更适合用梯度方法. 输入是5维,3维坐标和2维角度,输出是颜色和密度. 约束包括不同视角相同位置的密度一致. 该函数把位置 x \bm x x用8层FC映射到密度 σ \sigma σ,和256维向量,该向量和相机方向concate,得到RGB颜色. 渲染方程积分用分段采样近似。 输入直接送入网咯效果不好,从而用高频编码。此外用了Hierarchical volume sampling进行加速,用两个网络,coarse和fine. 先采样 N c N_c Nc个算coarse网络,再用coarse网络的 N c N_c Nc个位置的“颜色影响权重”形成分段constant分布进行采样. 一个sense优化一个网络. Loss就是重构,数据集似乎是一个sense的多个方向. 最大的收获还是点的建模方式
项目启发,经典文章







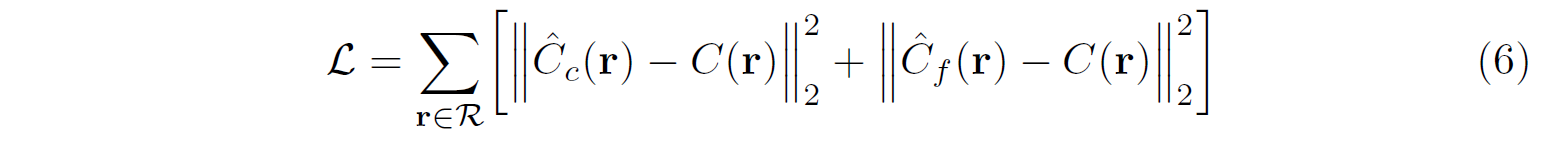


-
Improved StyleGAN Embedding: Where are the Good Latents?
arXiv2020 12 StyleGAN隐空间位置
略读。找个了StyleGAN的隐空间,适合做重构和编辑。在W Space中,先过LeakyReLU_5,再利用PCA进行whiten,得到P_N Space,对18个维度各自取值,形成P_N^+ 空间. 此时该空间很像标准高斯。Loss除了重构,还有P_N^+空间的L2。实验集中在重构、编辑、conditional embedding quality三部分
项目需要


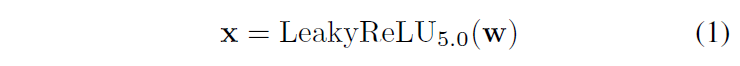
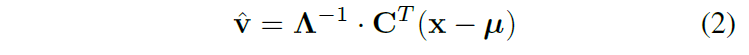
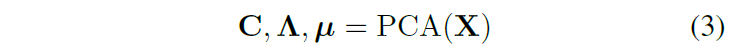
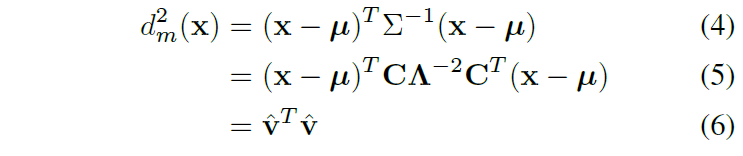

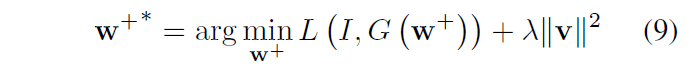


-
SEAN: Image Synthesis with Semantic Region-Adaptive Normalization
CVPR2020, Face Parsing的编辑
略读。和MaskGAN同任务. 类似SPADE,但是可以做编辑。loss包括conditional GAN、判别器的feature matching、perceptual loss. 具体见图。512维style




-
2021-7-31
CONFIG: Controllable Neural Face Image Generation
ECCV2020. Face Generation
略读。最大亮点是借用了个人脸生成器,也是他们微软的文章。并且认为这是两个Domain,但是能提出共性来。另外用VGGFace算perceptual loss作为fine-tune也是一个亮点吧。训练两个阶段,看图。此外,还有单张图的Fine-tune.
项目需要

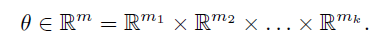

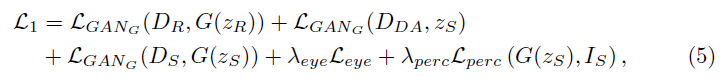
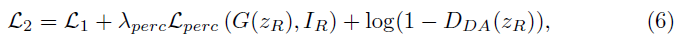





-
2021-7-29
Two-phase Hair Image Synthesis by Self-Enhancing Generative Model
Journal of Computer Graphics Forum 2019. Hair generation
Pix2pix+头发精修. 除了用gabor filter提orientation map,还提出了texture map,直接用gabor filter响应最大的值。Gabor filter公式写得好。Loss包括pixel-level reconstruction(数据集成对有监督)、adv、gram matrix(这个公式写得好,要除以CHW)、feature matching生成图算一次orientation map和texture map和输入保持一致。整个网络输入是2channle的,一个是前景segmentation,一个是笔画走向. 这篇文章还能做超分,没细看
Hair项目需要







-
2021-7-22
Towards High Fidelity Face Relighting with Realistic Shadows
CVPR2021
略读,能产生shadow的relighting,几乎没看懂。。没用在Lab空间做,而是在YUV空间。数据集为DPR的造数据集和Extended Yale Face Database B,网络预测了ratio image R t R_t Rt和光照 l p l_p lp,其中shadow border weights更加强调了阴影区域. 此外还算了环境光。shadow mask则是根据3D shape和SH光照推算
顶会光照文

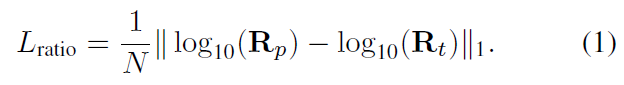
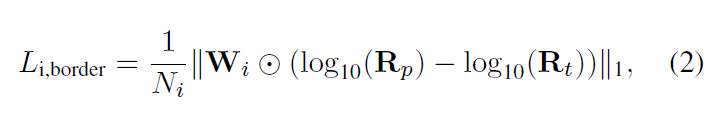


-
2021-7-22
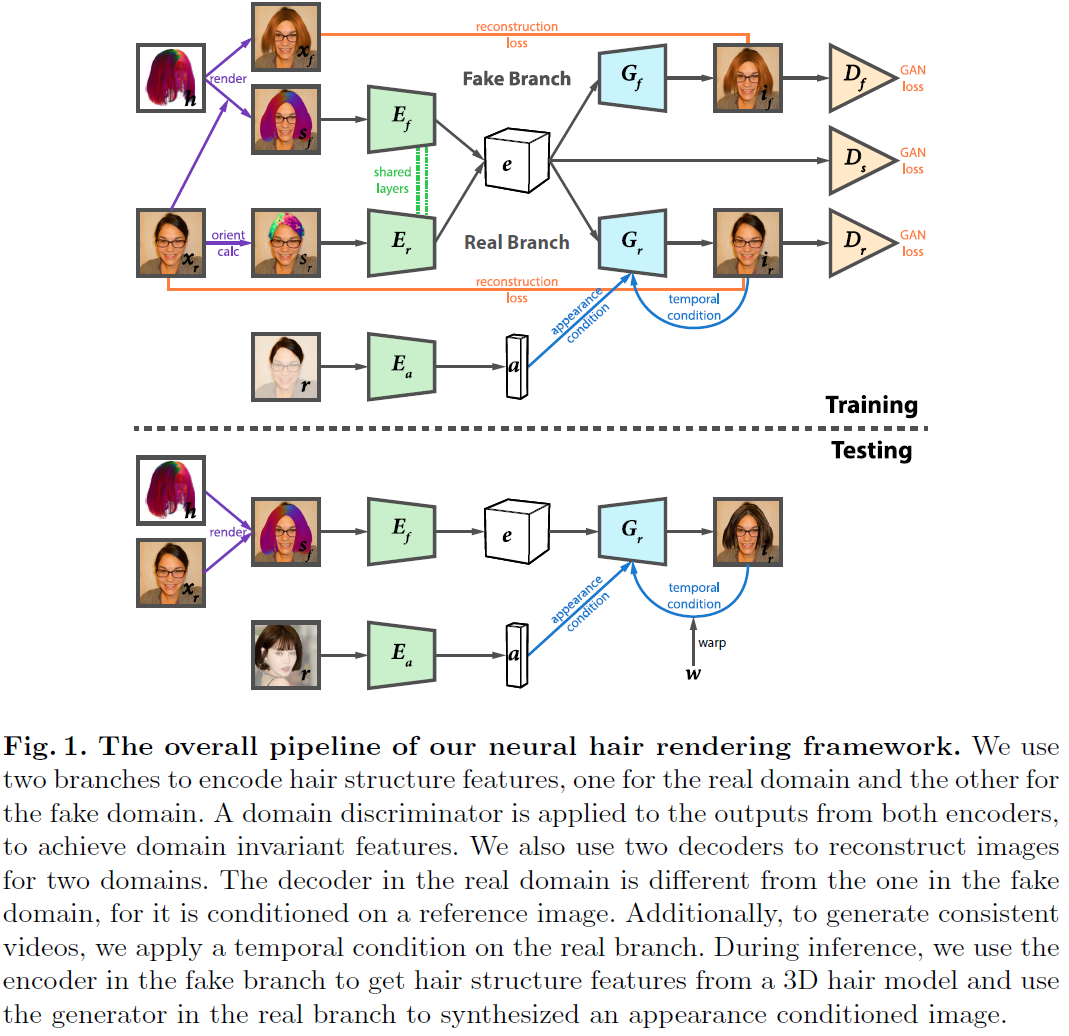
Neural Hair Rendering
ECCV2020 Hair render
头发编辑。头发分为structure和appearance两部分。在real分支中, S r S_r Sr是通过一个方向filter提取的, E a E_a Ea提取appearance, G r G_r Gr生成真实头发重构。 S f S_f Sf则利用 h h h和 x r x_r xr进行渲染得到, E f E_f Ef提取和 E r E_r Er相同内容,包括ID和hair 的shape和structure. x f x_f xf永远是黄头发, G f G_f Gf生成黄发人进行重构。训练分两阶段,先按照公式7训练,再fine-tune实现video的temporally-smooth(不同帧之间头发的丝滑过度),fine-tune时,50%概率利用motion flow来warp上一时刻的图像,另50%概率给0. a a a和wrap image一起concatenate之后,通过SPADE的方式送入 G r G_r Gr
项目需要,Neural rendering




上图视频链接 -
2021-7-21
GIF: Generative Interpretable Faces
3DV2020 CG人脸生成
结合StyleGAN2和CG。把人脸3D的texture rendering和normal rendering放到了noise中直接相加(为什么要这样做?这样的话style vector就不能用texture和normal的信息了呀。另外代码中noise过了三次卷积,可能是为了对齐shape,并做一些后处理)人脸用了FLAME的子集RingNet建模,它比3DMM好像多了人脸转交pose的信息,FLAME中pose采用了 θ ∈ R 15 \bm \theta \in \mathbb R^{15} θ∈R15,包括axis-angle rotations for global rotation and rotations aroundjoints for neck, jaw, and eyeballs). 此外还有一个Texture consistency,好像是在不改变style embedding、appearance和lighting的情况下,再生成一张脸,约束脸部的texture map保持一样(这样两张脸不是不能对的很齐嘛)
CG人脸生成
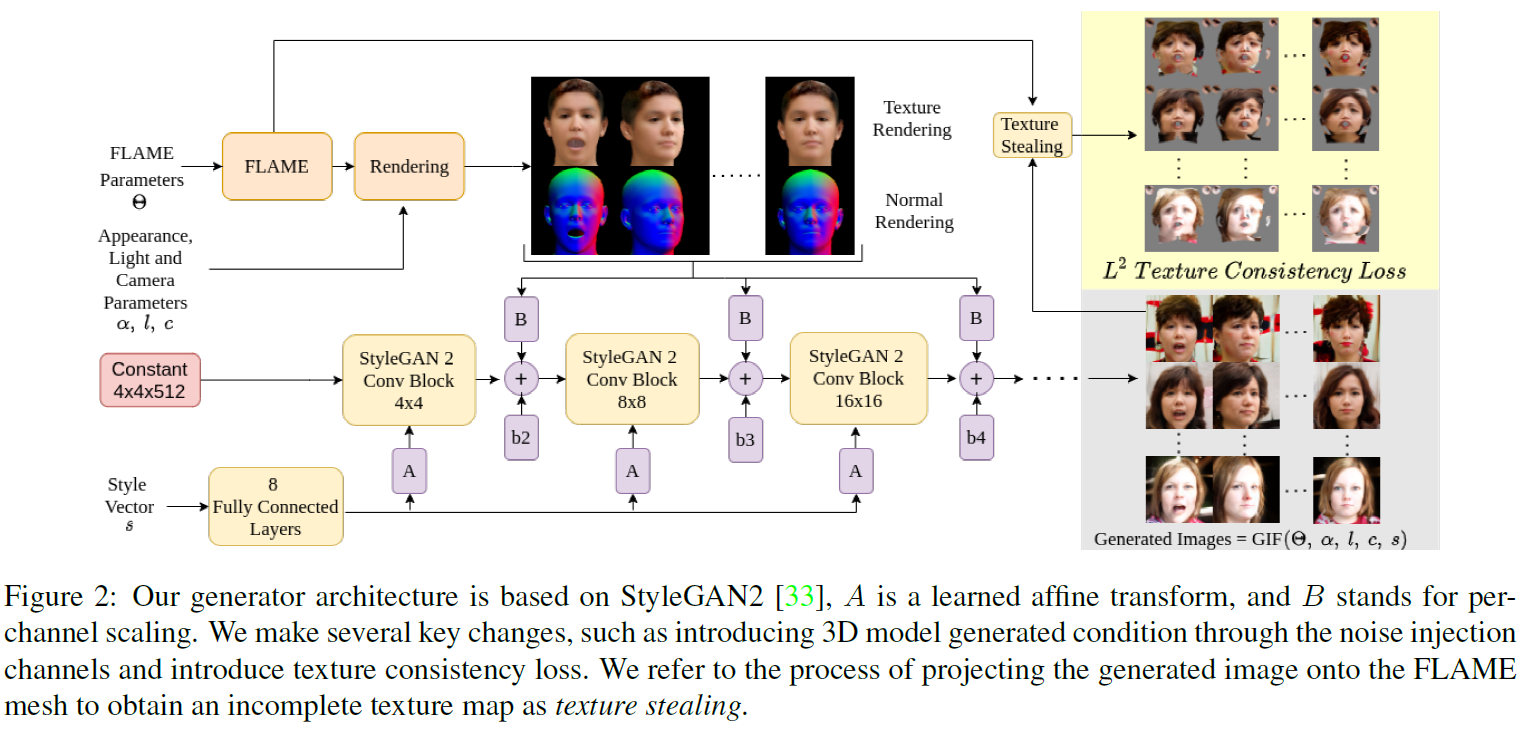



-
2021-7-21
Relighting Images in the Wild with a Self-Supervised Siamese Auto-Encoder
WACV2021 Relighting with self-supervised
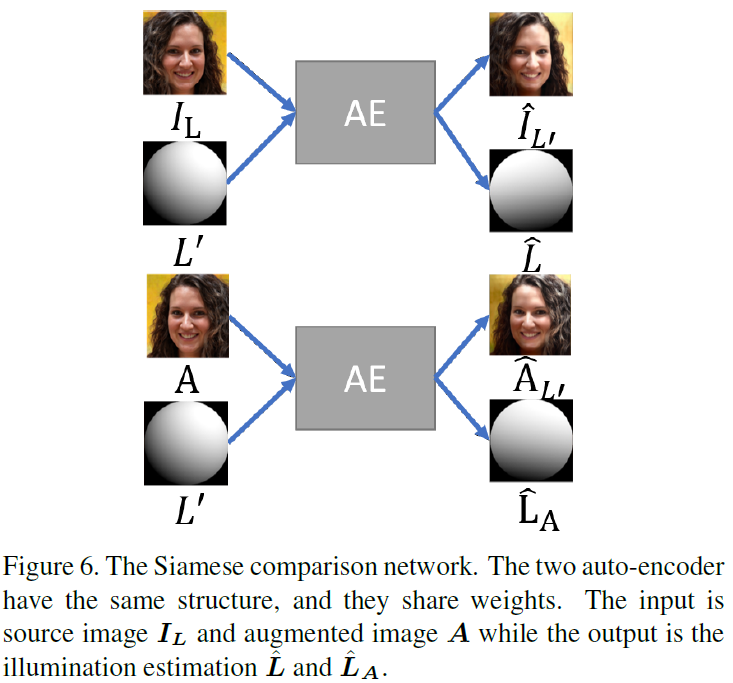
略读。Loss分三项 1. GAN 2. reconstruction 3. 图像翻转、旋转、inversion(自己提的一个操作)扩充后SH的约束。(这我感觉做不出来吧,约束太少了,怎么保证光照信息不会全0呢,以及怎么保证光照随SH单调。图像反转后域是不是都变了?)而且公式5、6怀疑正负号有错。
自监督光照

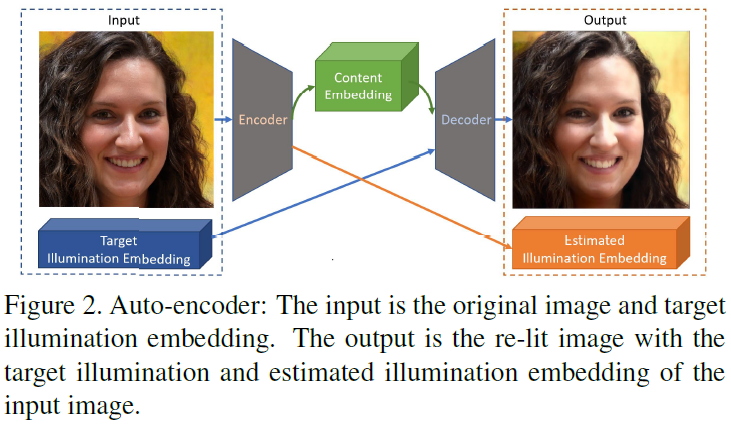
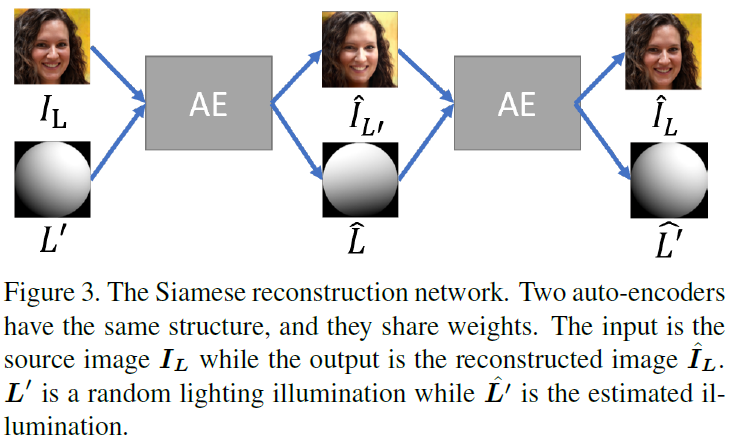
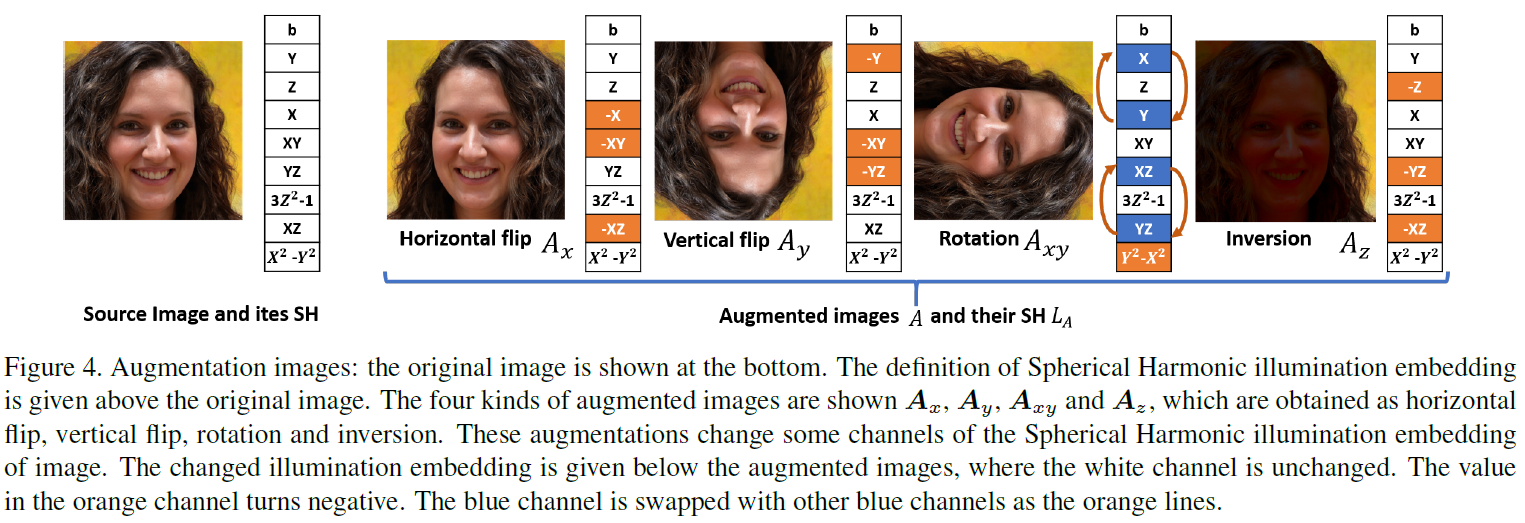



-
2021-7-21
Real-Time Hair Rendering using Sequential Adversarial Networks
ECCV2018 头发渲染
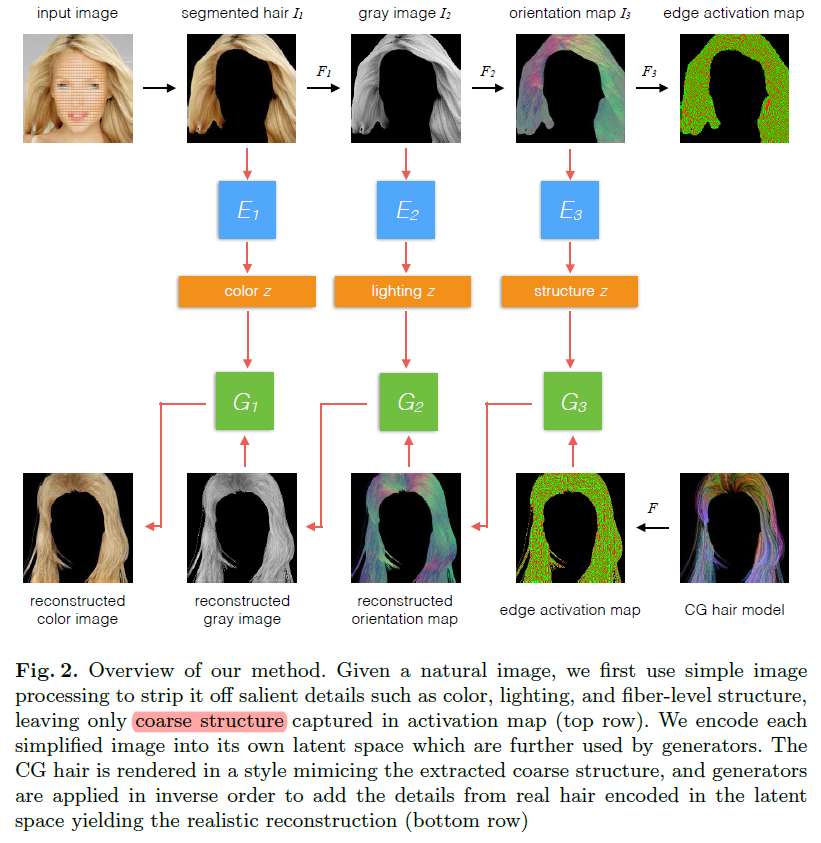
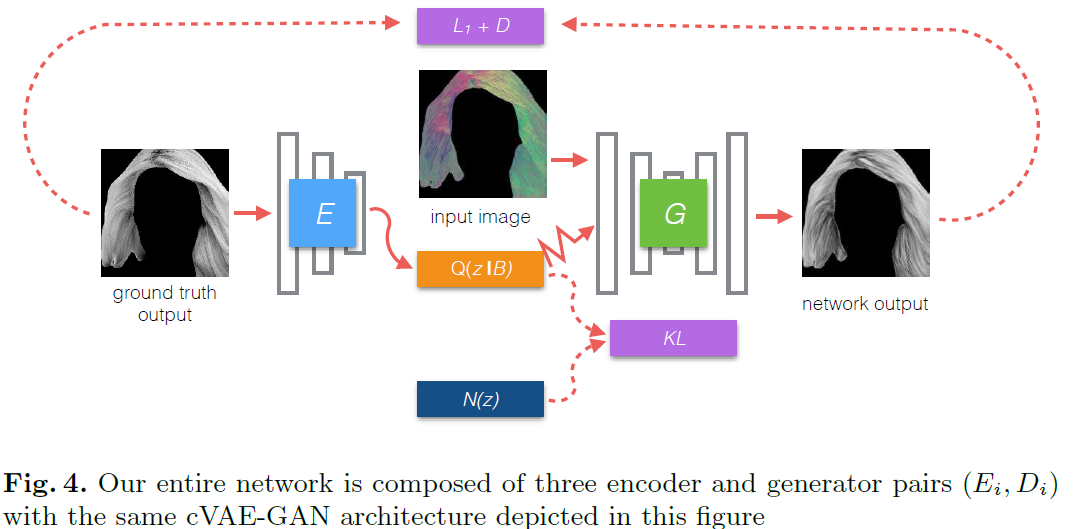
利用3个独立的autoencoder,实现从CG hair model到真实头发的渲染. CG hair model中每条线都是一根头发。头发可以把颜色、光照、结构一步步解耦出来。每一个autoencoder采用了VAE+GAN. 数据为CelebAHQ自行分割。从gray图到orientation map采用了DoG filter.
头发渲染,项目需要




-
2021-7-17
GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields
CVPR2021 Best Paper, Neural Rendering
该方法利用无标注数据集,实现图像基于3D的生成。具体为,每一个3D方向点映射到特征空间 f \bm f f和volume density σ \sigma σ, 经过Composition Operator C \mathcal C C, π v o l \pi_{vol} πvol是一个物理渲染过程,这里只渲染到了低纬度,高维采用 π θ n e u r a l \pi_{\theta}^{neural} πθneural进行2D渲染。整体是GAN的结构。(一些没搞懂的问题,shape和style如何分离的,STR如何获得)
项目需要,3D编辑好文
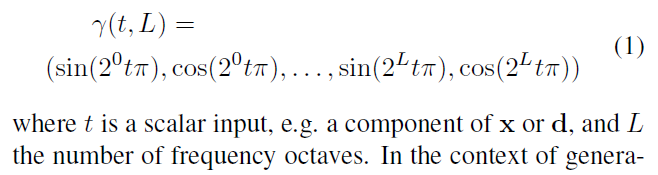
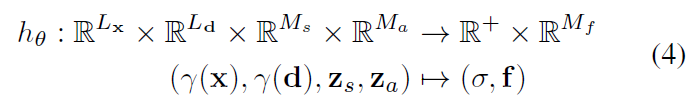


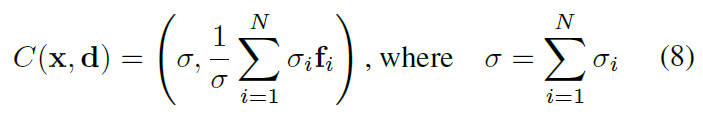
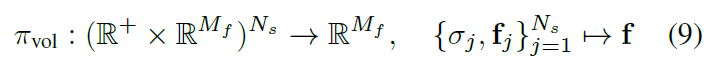

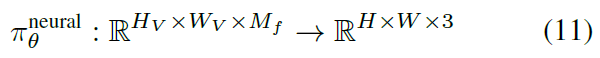
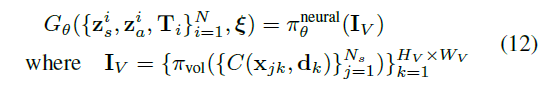






-
2021-6-29
Image-to-image Translation via Hierarchical Style Disentanglement
CVPR2021 oral, multi-att,multi-modal,instance-level人脸属性编辑
该方法像是ModularGAN的加强版,编辑过程包括E,T,G. E负责编码得到整张图的Feature map,T负责转换feature map,来使图像attribute符合style,G负责把feature map转为图像。注意T是不同属性tags用不同的参数. 判别器则精细到了tags-attribute,即不同属性的不同取值用一个D,有点类似StarGAN v2. Loss包括各种重构,风格编码重构,对抗. 风格编码从高斯分布提取,经过M网络转换,也可以从图像中通过F网络提取,这一块也很想StarGAN v2. 一些细节:把属性分为了tags,每个tags有不同的取值。中判别器是对于每种属性(文中的tags)的每种取值(文中的attributes)各一个。为了缓解编辑时属性两侧取值的无关属性不平衡(例如黄头发女性多,改变发色可能影响性别),把无关属性取值也输入D当中,形成cGAN(感觉上这样能防止一部分变无关属性吧)。网络结构backbone是一堆resblock,有StarGANv2的感觉。
项目需要,人脸编辑好文



 -
2021.6.27
SC-FEGAN: Face Editing Generative Adversarial Network with User’s Sketch and Color
ICCV2019 交互式编辑
其实我觉得这个方法更像是inpainting,重点是造数据,模拟mask生成(随机画线),color map通过face parsing提取各自部分的中位数颜色得到,sketch也有方法提取,头发区域用GFC特殊提取;生成器用了gated conv. Loss包括WGAN-GP、像素重构、perceptual loss重构、style gram matrix重构,total variance(只用重构图像就能重构这么好呀)
项目需要、有趣工作






这里VGG Loss居然这么影响效果 -
2021.6.25
MichiGAN: Multi-Input-Conditioned Hair Image Generation for Portrait Editing
SIGGRAPH2020 编辑头发,基于学习,Barbershop和LOHO的之前工作
精读。头发分appearance(颜色)、structure(直、卷等)、shape三个部分。
I o u t = G ( M , O , I r e f , I ) I_{out}=\mathcal G(M, O, I_{ref}, I) Iout=G(M,O,Iref,I),其中 M M M是shape mask, O O O是Gabor filters(方向检测)的feature map, I r e f I_{ref} Iref提供了appearance. background需要和头发区域巧妙融合在一起,所以在backbone靠后层不断用mask blend. 训练loss就是Lab空间重构、gabor kernel 的feature map重构、perceptual loss、对抗. (所以这里也没有真实成对数据啊,效果到底怎么样未知). 此外该文章可以用于交互式编辑. 该文章细节处需要inpainting方法
项目需要









-
2021.6.23
Barbershop: GAN-based Image Compositing using Segmentation Masks
arXiv2106 StyleGAN2 embedding操纵,类似LOLO,编辑头发,也能编辑其他区域
精读,设计FS空间,其中F是StyleGAN2生成的中间一层 32 × × 512 32\times\times512 32××512,S是剩下的W噪声 10 × 512 10\times 512 10×512. 方法是先重构,向最终Segmentation对齐,对于每张输入图和 最终Segmentation中从该图来的Semantic Mask重叠 的位置,F直接复制过来,否则从重构的W生成. 最终Blend图的F来自各个对齐图的F. S则可以来自另外的图像. S控制了更精细的appearance. 为了和Mask图像对齐,引入了人脸Segmentation网络,并优化. align F还用了Gram Matrix的loss(Gram matrix到底怎么用的,这里似乎是匹配内容,而LOHO似乎匹配风格),其他基本都是LPIPS Loss. User Study显示该方法远好于LOHO和MichiGAN. 主要该方法对于不一致的人脸鲁棒一些吧
项目需要







-
2021.6.21
LOHO: Latent Optimization of Hairstyles via Orthogonalization
CVPR2021 StyleGAN2 embedding操纵,类似Image2StyleGAN++,编辑头发
精读,基于优化,得到StyleGAN2的 W + , N \mathcal {W}^+,\mathcal N W+,N. 头发分成1)perceptual structure;2)appearance;3)style. Loss分为 L f L_f Lf用perceptual loss保持person1的id; L r L_r Lr用perceptual loss保持person2的structure; L a L_a La用vgg feature average pooling保持person3的appearance; L s L_s Ls用vgg feature的gram matrix保持style,以上loss都是有各自mask的. L n L_n Ln noise map损失用于让 n ∈ N n\in \mathcal N n∈N正则化(?). 优化时分了两步,第一步先专心优化形状。传梯度时,投影的方法剔除了person2的style和appearance影响. 数据集来自FFHQ. 该方法需要头发较为对齐
项目需要



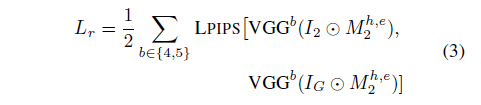
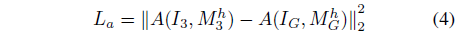





-
2021.5.26
Im2Vec: Synthesizing Vector Graphics without Vector Supervision
CVPR2021 oral
矢量图重构,训练不需要标注
结构化生成 paper reading









-
2020.12.15
House-GAN: Relational Generative Adversarial Networks for Graph-constrained House Layout Generation
ECCV2020 oral
房型图生成,Conv-MPN输入,CONV-MPN是对GNN的一种结点用3维图像信息的扩展
图+GAN paper reading







-
2020.11.16
AOT: Appearance Optimal Transport Based Identity Swapping for Forgery Detection
NeurIPS2020 略读(只扫了一眼方法)
对其他论文的换脸之后进行精修。基于最优传输Appearance Optimal Transport(AOT). 和Portrait lighting transfer using a mass transport approach类似. 换脸之后得到 X r X_r Xr,用Perceptual Encoder提特征,得到 F X r 1 F_{X_r}^1 FXr1, F X r 2 F_{X_r}^2 FXr2等。和真实图片的特征 F x t 1 F_{x_t}^1 Fxt1, F x t 2 F_{x_t}^2 Fxt2等之间解最优传输(实际上是在 v v v上解,不是在像素上, v = ( f , x , n ) v=(f,x,n) v=(f,x,n),除了特征 f f f外,还有像素级position、normal),不好直接解,借鉴WGAN的方式,用了两层和三层的全连接小网络。最后Face Decoder的loss包括如下截图. L M S D \mathcal L_{MSD} LMSD是一个亮点,编辑后,对真实和虚假图像进行随机Mask融合,然后用D去猜Mask
导师推荐









-
2020.9.2
Image2StyleGAN++: How to Edit the Embedded Images?
CVPR2020 StyleGAN embedding操纵
跳读。基于Image2StyleGAN做了一些改进。1:优化涉及到了noise。并且先优化w,再优化noise(优化noise不会提升PSNR),然后再优化w,挺好的思路。2)设计了很多Mask,这样可以做两张图像之间的融合,利用mask。3)设计了Style Loss,我觉得好像就还是单层的VGG Perceptual Loss. 4)从不同的spatial位置对卷积中间的特征结果进行融合。基于这些改进,做了非常非常多的application,有些没有细看。比较有借鉴意义的是stylegan做inpainting、基于mask的local style transfer和attribute transfer
StyleGAN猜w和n






-
Image2StyleGAN: How to Embed Images Into the StyleGAN Latent Space?
ICCV2019 StyleGAN猜latent code
读的还行吧,不算精读,不算扫读。方法很直接,对StyleGAN里的参数w进行优化,优化的初始值很重要,对于人脸这种比较一致的集合,初始化成w的平均值会比较好;对于猫狗这种差异大的,初始化成一个U(-1, 1). loss function两项:1)perceptual loss;2)pixel-level loss. 用这些w做了不少实验,包括interpolation、combination(style transfer)、把图像反转/平移之类的再进行优化。
StyleGAN猜w







-
2020-9-1
StyleFlow: Aribute-conditioned Exploration of StyleGAN-Generated Images using Conditional Continuous Normalizing Flows
arXiv 202008 StyleGAN based 光照编辑
文章很长,方法部分读的细,实验几乎只看了几眼图。StyleGAN中的w到Image这一段不动,但是要编辑,就需要一个合理的w。所以本文设计了一个神经网络Φ用于给定先验分布z和属性a,生成合理的w;换句话说就是学习了一个映射。这个过程建模成了continuous normalizing flows(比较复杂,是一个ODE)。w、a、Image先采样,形成数据集。然后训练Φ。目标函数:1)让 z 0 z_0 z0通过约束L2符合高斯;2)让w的概率最高。(这里很难讲,建议看原文)。编辑的时候,光照只改变7-11层的w,比较靠后,不用全变。
jiping老师推荐,和DisentangledGAN功能上很像








-
2020-8-31
Analyzing and Improving the Image Quality of StyleGAN
CVPR2020 StyleGAN2
精读,写的真tm好。对StyleGAN进行了修补。(1)为了防止生成图像中的局部“水滴”瑕疵,没有直接采用in,用另一种结构进行替换。比较复杂,建议看原文。总之这种新结构把in、adain的shift,都放到了网络权重上。(2)Lazy regularization,过16minibatches才算一次参数L1。(3)Path length regularization. 约束了外部风格w对生成图像的影响偏导,让path稳定。(4)换掉progressive growing的网络结构,实验表明,生成器用低分辨率到高分辨率skip 叠加的方式,判别器用residual net更好(residual本来就是为了做分类)(5)这样的生成结构在高分辨率的结果锐利、但不真实,所以倍增了channel数量。论文还做了images到latent space的映射,没细看;该映射也可以用来进行伪造判定。
StyleFlow前置、经典文章,不得不看










-
2020-8-11
Illumination-invariant Face Recognition with Deep Relit Face Images
WACV19 Relighting
扫读,只读了Relighting有关的方法部分。用Relighting可以做face recognition。relighting方法比较trivial,不过亮点是球谐光照的漫反射写的比较详细,而且是和neural face editing不一样的写法,而且写的更贴近原理,不过两种表达方式等价。用E2FAR的方法估计shape,设计了一个DLRN的预训好的resnet估计lighting,albedo似乎从剩下的部分算出来。另外这边文章用的是BFM-2017
Relighting相关




-
2020-8-11
Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning
CVPR20 物理人脸生成
扫读,实验部分大致看了relighting相关。很好的文章啊!生成的时候把人脸分成3DMM那一堆,每个参数都用vae训了一下,让它能到人工设计分布。生成中用网络生成,训练分两大步,第一步imitative learning和rendering生成的计算face recognition id loss,68特征点loss,光照预测loss,和人脸部分平均颜色回归。这里光照预测用的应该是3DFaceDeepReconstruction。第二大步,为了精细解绑,设计了contrastive loss,对于只改变表情,计算rendering在表情改变前后的flow field,并warp到网络生成的图像上,和网络直接生成的结果做差,进行对比;另一方面,对于只改变光照,要求id不变,hair segmentation probability map不变,68特征点不变。用了Style GAN的网络。无成对数据训练!文章末尾还进行了一些latent space理论特性的验证
Relighting相关






-
2020-8-10
SfSNet: Learning Shape, Reflectance and Illuminance of Faces ‘in the wild’
CVPR2018 人脸3D重建和再生成
扫读,没读实验。这论文可能时间有点久,现在看来可能有些trivial。另外论文写的奇怪,训练过程到底是什么样的。哪些loss对应生成数据,哪些loss对应真实数据?我猜应该是image-level的对应真实,其他的对应生成吧。朗博反射模型。残差的网络结构可能是个亮点
人脸3D重建




-
2020-8-09
Towards High-fidelity Nonlinear 3D Face Morphable Model
CVPR19 人脸3D重建
扫读,没读实验。仅仅读了方法部分,nonlinear 3DMM改进版。考虑到nonlinear 3DMM中正则项会丢失很多shape和albedo细节,把原先学的shape和albedo当作代理Proxy,让Encoder再生成一个真正的shape和albedo,训的时候用新的shape和albedo proxy在一起,优化新的shape;新的albedo同理。不优化新shape和新albedo在一起的那支,因为会让新shape获得在新albedo和albedo proxy之间的不好解。另外生成的网络换成了两路global+local,local有四个,每个去预测单独的部分
Nonlinear 3DMM后续作品





-
2020-8-09
On Learning 3D Face Morphable Model from In-the-wild Images
PAMI19 人脸3D重建
扫读,没读实验。重读。3DMM的nonlinear版。比较有趣的是albedo用了UV坐标系,并且shape也用了UV坐标系,很神奇,我觉的y的UV坐标系不是固定的吗?不过都用UV图像可以用CNN网络训练。3阶球谐光照和漫反射。用一个外部的Mask分割只重建人脸区域,并且能免去头发等遮挡。Loss有图像重构、特征点重构(似乎在UV坐标系上进行)、VGG Perception Loss。正则化项很有启发,albedo要对称、albedo要局部一致(这个loss有点迷)、shape要平滑(total variance)。由于优化空间太大,所以先用其他方法生成shape、texture、projection matrix的ground truth重构,待初步收敛再真正训练。可以做relighting,这里relighting不知道为什么感觉背景也变了,不懂。。。
经典人脸3D重建、Relighting相关









-
2020-7-30
Accurate 3D Face Reconstruction withWeakly-Supervised Learning: From Single Image to Image Set
CVPRW2019 人脸3D重建
3DMM + HS光照,HS9个系数。一共学习239个系数。Loss很naive啊,和ground truth之间pixel重构,68特征点重构(不知道是不是能从3D模型直接得到3D特征点),FaceNet的输出作为feature的inception loss。还有两项正则化,分别是3DMM系数的L2,还有一个没看懂的。。flattening constrain to penalize the texture map variance。这Loss不会像None Linear 3DMM说的那样产生病态解嘛?对同人的多张图片的3DMM中id系数进行加权训练,学一个正的权重系数网络。
人脸3D重建 Relighting被huawei推荐






-
2020-7-29
Face Alignment in Full Pose Range: A 3D Total Solution
3DDFA 3D人脸重建
实验部分没读。级联生成人脸参数。旋转参数用了四元数,因为欧拉角会出现两组欧拉角映射到一组姿态的问题。Loss应该就是直接和Ground Truth反向传播时因为不同参数发挥的作用重要程度可能不同,所以弄很多种不同的优化策略,又是雅可比矩阵、又是泰勒展开。。。搞出来PAF和PNCC两种特征图。
Relighting DPR采用



-
2020-7-22
Portrait lighting transfer using a mass transport approach
SIGGRAPH2017 Relighting DIP方法 样例级
扫读。和颜色直方图方法类似。构建图像的复合向量:c = {2维像素位置、3维RGB、3维法向}叉乘,然后再和参考图像之间构成一一映射,使得 c c c之间的距离和最小。这个和推土距离同理,只不过推土距离是一维的,这个8维。不同维度之间可以有不同的权重系数。这个映射可能会产生不好结果,尤其是姿态差异大时,所以会在每个像素用高斯模糊去多次采样,谓之正则化。另外,这种算法比较耗时,所以换成一种迭代的方式,我没有细看。如果只想改变亮度,则可以在Lab空间中的L分量上搞,不用RGB。当分辨率过高时,设计了一种两阶段的方式。实验没有细看。
Relighting CG这边的文章





-
2020-7-20
Single Image Portrait Relighting
TOG2019 环境光Relighting
实验部分没怎么读。采了一个很复杂的数据集,每个人7个机位,然后套上一堆不同的环境光。然后直接用神经网络训。Loss就是ground truth,恒等重构,还有光着重构。autoencoder结构,把环境光照解出来。造数据集的过程是亮点,可以参考。
光照文章





-
2020-7-16
Learning Physics-guided Face Relighting under Directional Light
CVPR2020 relighting
扫读。把人脸分解出反照、形状三部分,然后换光源方向和大小,重新渲染。用了一个residual阶段来预测非漫反射光,是个亮点。用visibility来标记可见与不可见区域。公式推的不错。这个图片好像只能是黑背景?训练方面用PMS先得到albedo、shading、residual,当作ground truth,然后训练,loss可以选用L1、L2、LPIPS等等。该方法可以用于复杂环境光,但是我没看懂到底怎么做的
光照文章


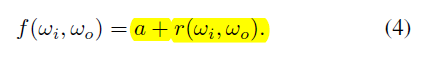




-
2020-7-15
Deep Single-Image Portrait Relighting
ICCV2019 Relighting
扫读。先用3DDFA拿人脸3DMM形状参数,再用ARAP based method(ESGP2007)通过特征点三角剖分进行精修。再用SfsNet进行光照提取和渲染,造数据集,包括目标光照和图像ground truth。 神经网络训一波,光照重构、人脸生成图像重构、GAN对抗、perception loss. 分辨率512到1024. 数据集从Celeba-HQ构造. Multi-Pie测试、算定量指标(这个数据集光照成对)。
光照文章







-
2020-6-13
A Morphable Model For The Synthesis Of 3D Faces
SIGGRAPH1999 3DMM
把人脸分解为shape和texture,用pca得到shape和texture的低维表达。其中低维表达的系数 α , β \alpha, \beta α,β服从高斯分布,是主要优化的参数。 S ˉ \bar S Sˉ, C ˉ \bar C Cˉ是平均脸,主要优化对象。 ρ \rho ρ是照相机参数,也是优化对象。“随机”梯度下降优化时似乎是对一小块区域进行优化。
3D人脸经典文章










-
2020-6-4
Face2Face: Real-time Face Capture and Reenactment of RGB Videos
CVPR16 视频表情操纵,经典文章
关注人脸生成,表情操纵,嘴巴召回。multi-linear PCA model去进行人脸生成。 a i d a_{id} aid和 a a l b a_{alb} aalb是均值, α , β , δ \alpha, \beta,\delta α,β,δ是标准差。各个E看起来是标准高斯分布。
视频人脸经典文章


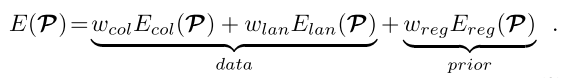


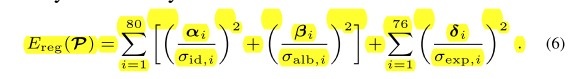
上述内容说明了如何进行人脸生成。下一part说明如何进行表情操纵


下一part说明如何补嘴巴。嘴巴会根据一个距离度量,对target 每一帧进行改进kmeans的10类聚类,和其他每个样本距离都最小的作为cluster的representative。作为召回库。召回时选一个距离最近的cluster。





-
2020-5-22
Image super-resolution using very deep residual channel attention networks
ECCV2018 超分
对超分不了解,不过应该是一篇经典文章了。贡献:1、网络非常深,有10个Residual Group,每个Residual Group有20个Residual channel attention block,每个block内又有差不多4层卷积。。。2、residual in residual,嵌套残差。3、channel attention引入residual group,注意是channel不是spatial,每个channel出一个系数,然后乘上 X g , b X_{g,b} Xg,b,再加到 F g , b − 1 F_{g,b-1} Fg,b−1。4、本文一再强调图像中的高频和低频部分应该用不同的处理,低频直接过,高频靠生成,所以Residual in residual和channel attention应运而生。Loss就直接和ground truth算L1,不是GAN结构。实验很充分,BI/BD两种图像退化策略,PSNR/SSIM算相似度,resnet-50算top1和top5error,超分尺度2 3 4 8,看起来对纹理类细节很好. 更多数据集之类的细节看论文。
课程需要






-
2020-5-7
Neural Face Editing with Intrinsic Image Disentangling
CVPR2017 人脸物理分解 编辑
人脸的物理分解。数据集无监督。先用3DMM预训练,Loss包括 N e N_e Ne的重构, Z L Z_L ZL光照的重构, ∇ A e \nabla A_e ∇Ae的范数, ∇ S e \nabla S_e ∇Se的范数。 U V UV UV的重构, N i N_i Ni的重构。这里UV的implicit coordinate system没太看懂。预训练完成后,Loss包括adv和rec(auto-encoder)。人脸编辑靠DFI类似方法。
3D人脸



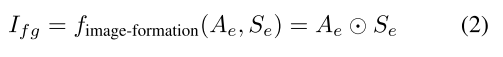

-
2020-4-29
Few-shot Video-to-Video Synthesis
NeulrIPS2019
vid2vid的instance-level扩展。很复杂,主要是在vid2vid的生成路改进(也即除了光流路的另一路)。这里example会决定卷积核的参数,当一张example图时,E_F卷好多层,每一层过E_P得到卷积核参数,参数分为三个part, θ S l , θ γ l , θ S l \theta_S^l, \theta_{\gamma}^l, \theta_S^l θSl,θγl,θSl。这里 p ^ H l \hat{p}_H^l p^Hl似乎是normalized features,最好看源代码。当example的数量K>1时,也即一个人的一堆图片,采用一种attention方式,认真看结构图,这里attention会和每一个example对应的source有关,也会和当前帧的source有关!这个方式原文说和SPADE是一样的。另外,本文loss与vid2vid一致。




链接:https://nvlabs.github.io/few-shot-vid2vid/web_gifs/face.gif -
2020-4-29
Video-to-Video Synthesis
NeurlIPS2018
成对数据下的视频到视频。看作是pix2pix的扩展真实图像的预测用了光流和直接预测两支。网络的输入包括前L-1帧的生成和带上当前时刻的前L帧的原图。三个生成模块,分别用来预测光流;生成和这两者之间的Mask;判别器CGAN有图像级别的,和一段T帧的固定序列级别的两部分。pix2pix中的ground truth约束被换成了预测光流场。街区数据库的训练分了前景和背景,还用了和pix2pix-HD中的multi modal 的方式。另外还有视频级别的FID和人脸数据库的特征点检测、对齐
vid2vid



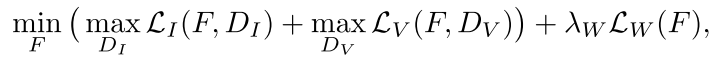
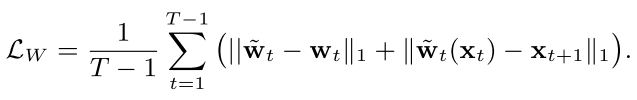
 链接:https://tcwang0509.github.io/vid2vid/paper_gifs/face.mp4
链接:https://tcwang0509.github.io/vid2vid/paper_gifs/face.mp4 -
2020-4-9
Representation Learning by Rotating Your Faces (DR-GAN的期刊版本 )
Disentangled Representation Learning GAN for Pose-Invariant Face Recognition
CAPR17, PAMI19
把GAN用于人脸转正,辅助判别。G包括Encoder和Decoder,从人脸解码出身份id,再拼上噪声和姿态项,生成人脸。判别器D判断r/f,姿态分类,身份分类。id直接当作embedding用于识别。用余弦角度度量相似度。很好的结合GAN的knowledge和判别任务的。另:几个改进(1)输入多张同id人脸图,Encoder除了生成编码还生成权重,最后id进行加权平均。这里权重也可以评估图片质量。(2)D和Encoder共同share参数。(3)D的身份分类和Encoder的id作用差不多,可以交替用于约束GAN。(4)实验非常全,评估指标和数据集都可以注意一下。
GAN和判别





-
2020-3-19
DRIT++: Diverse Image-to-Image Translation via Disentangled Representations
IJCV2020 multi-domain multi-modal instance-level
DRIT的期刊版,非常强。这里全部总结下。对于两个域,共用content,style服从先验分布。(1)content用一个D对抗使其混淆;交换两次,对偶重构;自重构;style要来一次info回归;两个判别器保持真实;KL散度作用于style E。(2)对于多域;统一用一个G,D,style E和content E,用onehot编码,类似stargan。生成器和判别器ACGAN;content对抗、一次和二次重构,info回归、style KL散度仍用。多属性style E的输入还包含domain;(3)一个启发性的亮点,让不同style的图片距离尽量大,类似StarGAN v2.(公式截图)。
https://github.com/lzhbrian/image-to-image-papers IJCV






-
2020-3-19
Multimodal Unsupervised Image-to-Image Translation
ECCV2018 MUNIT 两个域,multi-modal, instance-level
以前读过,很经典的文章了。这里回顾总结下。(1)两个域,每个域解开style和content,style都服从先验分布,content共享。两个E,两个G,两个D。(2)loss很简洁,L1自重构;交换content后,content和style都生成再打开,回归一边,类似infogan;再gan保持真实。文章理论分析了达到最优后,两个域c和s都在同一个分布。(3)用了AdaIN
经典文章







-
2020-3-18
Multi-mapping Image-to-Image Translation via Learning Disentanglement
Nips2019 DMIT disentangle,多域,multi-modal
很强的工作,Mark。(1)多域共享一个风格编码空间,和内容编码空间。这两个内容分别用两个编码器解出来。注意所有域share同样的编码器。(2)训练过程分为两个部分,D-Path部分,将一张图先解开,再合上。风格编码服从正态分布,VAE来一套。InfoGAN的回归也引入。为了让多域Content混淆在一起,引入了一种很神奇的CGAN,把一个域的label和其他域的content编码判真,该label和本域content判假。(好像是这样,可能不太对)这样会让不同域的content不断不断接近。(3)T-Path部分,给content,采样label和style,生成后解开。Infogan的回归约束content和style。CGAN让生成图加上类别并保持真实。
https://github.com/lzhbrian/image-to-image-papers 未分类(应该算是disentanglement)






-
2020-3-18
Image-to-Image Translation with Multi-Path Consistency Regularization
IJCAI2019 多域互转. 人脸、艺术图、去雨三个数据集
提出了multi-path consistency,也即从A->B和从A->C->B,要保持一致。把这个约束加在stargan和cyclegan上两种架构上。认为这个约束能减小noise,生成更一致的图片。为了做两个域,需要引入一个辅助域,例如去雨,可以把噪声图片当作中间域;去噪,可以把雨当作中间域。(这么搞真的靠谱嘛。。。因为引入了6个域)
https://github.com/lzhbrian/image-to-image-papers unsupervised multi-domain


-
2020-3-17
Augmented CycleGAN: Learning Many-to-Many Mappings from Unpaired Data
ICML2018 两个域互转,multi-modal AugCGAN
在cyclegan基础上,引入标准高斯分布的noise,两个g都有。(1)为了让noise发挥作用,引入两个Encoder,输入一张A域和一张B域图,预测把A域转B域需要什么样的noise。这样可以合理地做图片cycle loss。(2)为了让E的预测符合先验,和高斯先验对抗。(3)另外,给一个B域noise,先从A域生成到B域图,然后用E预测B域noise,约束一致。原理同infogan。(4)如果有paired数据,可以从一个pair中预测noise,然后translation。是一个可选的有监督约束。(5)noise的注入方式为CIN(conditional IN),没有直接concatenate
https://github.com/lzhbrian/image-to-image-papers Unsupervised multi-domain







-
2020-3-17
Attribute-Guided Face Generation Using Conditional CycleGAN
ECCV2018 早期,人脸编辑或身份编辑。模糊、清楚两个域 ConditionalCycleGAN
大致上cyclegan。两个D和G,一个模糊域,一个清晰域。(1)为了属性编辑,从模糊到清晰,用了cgan的结构。反之没有,我觉得这里其实有问题。从模糊到清晰再到模糊的后半段cycle怎么保证生成属性和模糊一样?(2)为了身份编辑,用LightCNN提取256维身份编码,从模糊到清晰的编辑输入该信号。输出也用LightCNN过一遍,拿到身份编码的L1 identity loss. 一个亮点是该方法的人脸编辑看上去很instance,而且能做很多任务,包括人脸交换、人脸转正等。
https://github.com/lzhbrian/image-to-image-papers Unsupervised multi-domain



-
2020-3-16
Semantic Image Synthesis with Spatially-Adaptive Normalization
CVPR2019 semantic map 2 image SPADE
提出Spatially-Adaptive,在semantic mask上通过网络层得到均值和方差map(不是一个标量,也即和Contitional BN的区别),然后把它用于偏移noise上。另一个点是可以训一个encoder解出一张图片的noise充当style,实现instancle-level style reference。其他几乎同pix2pix-HD
https://github.com/lzhbrian/image-to-image-papers Supervised
(下图 i i i表示第 i i i层)




















12-05
 434
434
434
01-22
2665
2665
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









