







我觉得这么做的目的和人的认知有关系,人们不是看到一张图片才开始认识这里面的所有事物的,而是认识这张图片里的所有局部图像,用下面的胖迪举个栗子:

为什么我们能认识这张没见过的图片是胖迪,因为我记得她的局部图片大致张什么样,就算换了衣服,换了头型,拼在一起还是认识,可以理解为“拼图”。






cnn就是利用了这个想法,称之为局部感知的感受野,只不过分解的每一个“拼图”更小,更小,小到只有3×3或者5×5个像素点,cnn把这个每一个3×3或者5×5的“拼图”理解为过滤器(Fiter),这个“拼图”并不是一个真正的拼图,它是一个把原图像的3×3或5×5的数据映射到一个局部特征map。
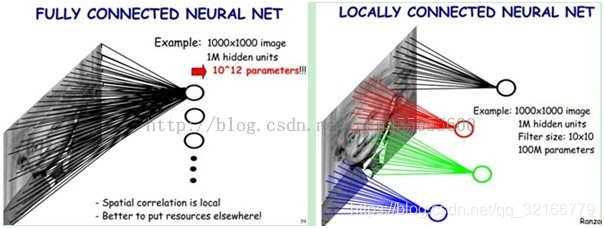 如上图,全连接就是把所有点的信息生成一个特征,1000x1000x1000000=10 ^ 12个连接,也就是10 ^ 12个权值参数。感受野是10x10,则隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。到这步为止是感受野的利用。
如上图,全连接就是把所有点的信息生成一个特征,1000x1000x1000000=10 ^ 12个连接,也就是10 ^ 12个权值参数。感受野是10x10,则隐层每个感受野只需要和这10x10的局部图像相连接,所以1百万个隐层神经元就只有一亿个连接,即10^8个参数。到这步为止是感受野的利用。
但是10^8个参数还是很多,所以干脆就把感受野设置为同一个,这就叫权值共享。
其实cnn很好理解,相比于普普通通的全连接就是以局部图像乘过滤器的方式生成特征,在编写Tensorflow的时候主要是把过滤器给搞出来,这个过滤器就是权值。
生成过滤器的api如下:
conv1 = tf.nn.conv2d(
input_tensor,conv1_weights,strides=[1,1,1,1],padding='SAME'
)
其中第一个参数就是训练时候的x,等到训练时把x放入即可。
第二个参数是个随机矩阵,就是每一步与x其中一块矩阵相乘的矩阵。代码如下:
conv1_weights = tf.get_variable(
"weight",[CONV1_SIZE,CONV1_SIZE,NUM_CHANNELS,CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1)
)
以前全连接的时候w是y=wx+b中的一个变量,但是这次cnn的w是一个CONV1_SIZECONV1_SIZE矩阵,如果CONV1_SIZE=5,那么就是个55的矩阵,官方说一般都是3×3或者5×5.
而之前的y=wx+b和现在的功能是一样的,只不过是每个矩阵的元素加b而已。














 714
714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









