









Reference:
1. XLNet: Generalized Autoregressive Pretraining for Language Understanding
2. XLNet原理解读
引言
AR模型以前向或后向的单向方式建模语言模型
p
(
x
)
=
∏
t
=
1
T
p
(
x
t
∣
x
<
t
)
o
r
p
(
x
)
=
∏
t
=
T
1
p
(
x
t
∣
x
>
t
)
p(\bm x)=\prod\nolimits_{t=1}^Tp(x_{t}|\bm x_{<t})\quad or\quad p(\bm x)=\prod\nolimits_{t=T}^1p(x_{t}|\bm x_{>t})
p(x)=∏t=1Tp(xt∣x<t)orp(x)=∏t=T1p(xt∣x>t)
AR模型仅以前向或后向建模语言模型,无法有效建模深层上下文。AE模型不进行显式密度估计,而是利用上下文信息,旨在从损坏输入中重建原始数据,如BERT,模型输入是部分token被替换为[mask]的序列,模型预训练是还原[mask]为真实的token。
BERT模型在微调阶段,真实输入中不存在[mask]标记,导致预训练和微调具有差异(pretrain-finetune discrepancy),而且,BERT也无法像AR模型那样以链式乘积形式建模LM,这是因为BERT模型假定序列中掩盖的tokens在给定所有未掩盖tokens时相互独立。
本文提出XLNet集AE模型和AR模型两者于大成:
- 传统AR模型以单向方式建模LM,而XLNet通过最大化序列的所有因式分解顺序排列的期望对数似然,由于排列操作,使得模型可利用上下文信息预测某一个token;
- XLNet不对数据进行掩盖,预训练与微调阶段一致,同时以AR方式建模,也能自然地使用联合概率分布通过因式分解预测token;
- 集成Transformer-XL中的分段循环机制和相对位置编码进行预训练,可处理长文本,并对标准Transformer-XL重参数化,解决因式分解排序顺序任意、预测目标位置模糊的问题;
- XLNet使用双流注意力将目标位置加入隐状态,而传统的基于排序的AR模型依赖于MLP网络中隐式的位置信息;
提出的方法
背景
给定文本序列
x
=
[
x
1
,
⋯
,
x
T
]
\bm x=[x_1,\cdots,x_T]
x=[x1,⋯,xT],AR语言模型通过最大化前向自回归因式分解的对数似然进行预训练:
max
θ
log
p
θ
(
x
)
=
∑
t
=
1
T
log
p
(
x
t
∣
x
<
t
)
=
∑
t
=
1
T
log
exp
(
h
θ
(
x
1
:
t
−
1
)
⊤
e
(
x
t
)
)
∑
x
′
exp
(
h
θ
(
x
1
:
t
−
1
)
⊤
e
(
x
′
)
)
(1)
\max_\theta\ \log p_\theta(\bm x)=\sum_{t=1}^T\log p(x_t|\bm x_{<t})=\sum_{t=1}^T\log\frac{\exp(h_\theta(\bm x_{1:t-1})^\top e(x_t))}{\sum_{x'}\exp(h_\theta(\bm x_{1:t-1})^\top e(x'))}\tag1
θmax logpθ(x)=t=1∑Tlogp(xt∣x<t)=t=1∑Tlog∑x′exp(hθ(x1:t−1)⊤e(x′))exp(hθ(x1:t−1)⊤e(xt))(1)
式中,
h
θ
(
x
1
:
t
−
1
)
h_\theta(\bm x_{1:t-1})
hθ(x1:t−1)表示
x
1
:
t
−
1
\bm x_{1:t-1}
x1:t−1在RNNs或Transformers神经网络模型中输出的语义向量表示,
e
(
x
t
)
e(x_t)
e(xt)是
x
t
x_t
xt的词向量。
概率理解: 假定使用RNNs网络,且词向量维度和隐状态维度相同,索引序列 x 1 : t − 1 \bm x_{1:t-1} x1:t−1在词向量矩阵进行look up转化为词向量,经RNNs并将 x t − 1 x_{t-1} xt−1在最后一层的隐向量 h θ ( x 1 : t − 1 ) h_\theta(\bm x_{1:t-1}) hθ(x1:t−1)作为 x 1 : t − 1 \bm x_{1:t-1} x1:t−1的语义表示向量,将语义向量与词向量矩阵(与输入共享)相乘、指数化,所得向量中的各元素即为上述右式的分子项。
相比较,BERT是去噪自编码模型,BERT将序列
x
\bm x
x中tokens以一定概率([mask]+随机+不变=15%)进行掩盖,通过最大化掩盖token的概率进行预训练(损坏数据重建):
max
θ
log
p
θ
(
x
‾
∣
x
^
)
≈
∑
t
=
1
T
m
t
log
p
θ
(
x
t
∣
x
^
)
=
∑
t
=
1
T
m
t
log
exp
(
H
θ
(
x
^
)
t
⊤
e
(
x
t
)
)
∑
x
′
exp
(
H
θ
(
x
^
)
t
⊤
e
(
x
′
)
)
(2)
\max_\theta\ \log p_\theta(\overline\bm x|\hat\bm x)\approx\sum_{t=1}^Tm_t\log p_\theta(x_t|\hat\bm x) =\sum_{t=1}^Tm_t\log\frac{\exp(H_\theta(\hat\bm x)_t^\top e(x_t))}{\sum_{x'}\exp(H_\theta(\hat\bm x)_t^\top e(x'))} \tag2
θmax logpθ(x∣x^)≈t=1∑Tmtlogpθ(xt∣x^)=t=1∑Tmtlog∑x′exp(Hθ(x^)t⊤e(x′))exp(Hθ(x^)t⊤e(xt))(2)
式中,
x
‾
\overline\bm x
x表示
x
\bm x
x中所有掩盖tokens,
m
t
=
1
m_t=1
mt=1表示
x
t
x_t
xt被掩盖,
H
θ
(
x
^
)
t
H_\theta(\hat x)_t
Hθ(x^)t表示
x
t
x_t
xt的语义隐向量。
两种预训练模型的特点:
- 独立假设: BERT基于所有掩盖token相互独立的假设分解联合概率分布 p θ ( x ‾ ∣ x ^ ) p_\theta(\overline\bm x|\hat\bm x) pθ(x∣x^),而AR语言模型使用普适性的因子链式乘积分解联合概率分布 p θ ( x ) p_\theta(\bm x) pθ(x);
- 输入噪声: BERT原始tokens以一定概率进行mask,如替换为[mask],微调下游任务中不含此类token,造成预训练和微调不匹配,实际BERT进行掩盖时会以一定概率保留原始token,但比例太少,不能解决不匹配的问题;
- 上下文依赖: AR模型所得语义向量 h θ ( x 1 : t − 1 ) h_\theta(\bm x_{1:t-1}) hθ(x1:t−1)仅通过单向建模得到,而BERT语义向量 H θ ( x ) t H_\theta(\bm x)_t Hθ(x)t是通过双向建模得到,所得语义向量表示更丰富;
目标:排列语言模型
以
Z
T
\mathcal Z_T
ZT表示序列
x
=
(
x
1
,
⋯
,
x
T
)
\bm x=(x_1,\cdots,x_T)
x=(x1,⋯,xT)所有可能的
T
!
T!
T!种因子排列,以
z
t
z_t
zt和
z
<
t
\bm z_{<t}
z<t分别表示排列
z
∈
Z
T
\bm z\in\mathcal Z_T
z∈ZT的第
t
t
t个元素和前
t
−
1
t-1
t−1个元素,排列语言模型可表示为
max
θ
E
z
∼
Z
T
[
∑
t
=
1
T
log
p
θ
(
x
z
t
∣
x
z
<
t
)
]
(3)
\max_\theta\ \Bbb E_{\bm z\sim\mathcal Z_T}\left[\sum_{t=1}^T\log p_\theta(x_{z_t}|\bm x_{\bm z_{<t}})\right] \tag3
θmax Ez∼ZT[t=1∑Tlogpθ(xzt∣xz<t)](3)
例如
x
=
(
x
1
,
x
2
,
x
3
)
\bm x=(x_1,x_2,x_3)
x=(x1,x2,x3),则
p
(
x
)
p(\bm x)
p(x)共有6种因式分解顺序:
p
(
x
)
=
p
(
x
1
)
p
(
x
2
∣
x
1
)
p
(
x
3
∣
x
1
,
x
2
)
⟹
1
→
2
→
3
p
(
x
)
=
p
(
x
1
)
p
(
x
3
∣
x
1
)
p
(
x
2
∣
x
1
,
x
3
)
⟹
1
→
3
→
2
p
(
x
)
=
p
(
x
2
)
p
(
x
1
∣
x
2
)
p
(
x
3
∣
x
1
,
x
2
)
⟹
2
→
1
→
3
p
(
x
)
=
p
(
x
2
)
p
(
x
3
∣
x
2
)
p
(
x
1
∣
x
2
,
x
3
)
⟹
2
→
3
→
1
p
(
x
)
=
p
(
x
3
)
p
(
x
1
∣
x
3
)
p
(
x
2
∣
x
1
,
x
3
)
⟹
3
→
1
→
2
p
(
x
)
=
p
(
x
3
)
p
(
x
2
∣
x
3
)
p
(
x
1
∣
x
1
,
x
3
)
⟹
3
→
2
→
1
p(\pmb x)=p(x_1)p(x_2|x_1)p(x_3|x_1,x_2) \implies 1 \to 2 \to 3\\[.5ex] p(\pmb x)=p(x_1)p(x_3|x_1)p(x_2|x_1,x_3) \implies 1 \to 3 \to 2\\[.5ex] p(\pmb x)=p(x_2)p(x_1|x_2)p(x_3|x_1,x_2) \implies 2 \to 1 \to 3\\[.5ex] p(\pmb x)=p(x_2)p(x_3|x_2)p(x_1|x_2,x_3) \implies 2 \to 3 \to 1\\[.5ex] p(\pmb x)=p(x_3)p(x_1|x_3)p(x_2|x_1,x_3) \implies 3 \to 1 \to 2\\[.5ex] p(\pmb x)=p(x_3)p(x_2|x_3)p(x_1|x_1,x_3) \implies 3 \to 2 \to 1
p(xxx)=p(x1)p(x2∣x1)p(x3∣x1,x2)⟹1→2→3p(xxx)=p(x1)p(x3∣x1)p(x2∣x1,x3)⟹1→3→2p(xxx)=p(x2)p(x1∣x2)p(x3∣x1,x2)⟹2→1→3p(xxx)=p(x2)p(x3∣x2)p(x1∣x2,x3)⟹2→3→1p(xxx)=p(x3)p(x1∣x3)p(x2∣x1,x3)⟹3→1→2p(xxx)=p(x3)p(x2∣x3)p(x1∣x1,x3)⟹3→2→1
重要的一点是,通过采样序列
x
\bm x
x的因子分解位置的顺序,分解似然概率
p
θ
(
x
)
p_\theta(\bm x)
pθ(x),采样序列第
t
t
t个元素可能对应原序列任意位置,因此模型可以捕获双向上下文信息,而且目标函数使用AR架构,没有独立假设,预训练和微调一致。
排列说明
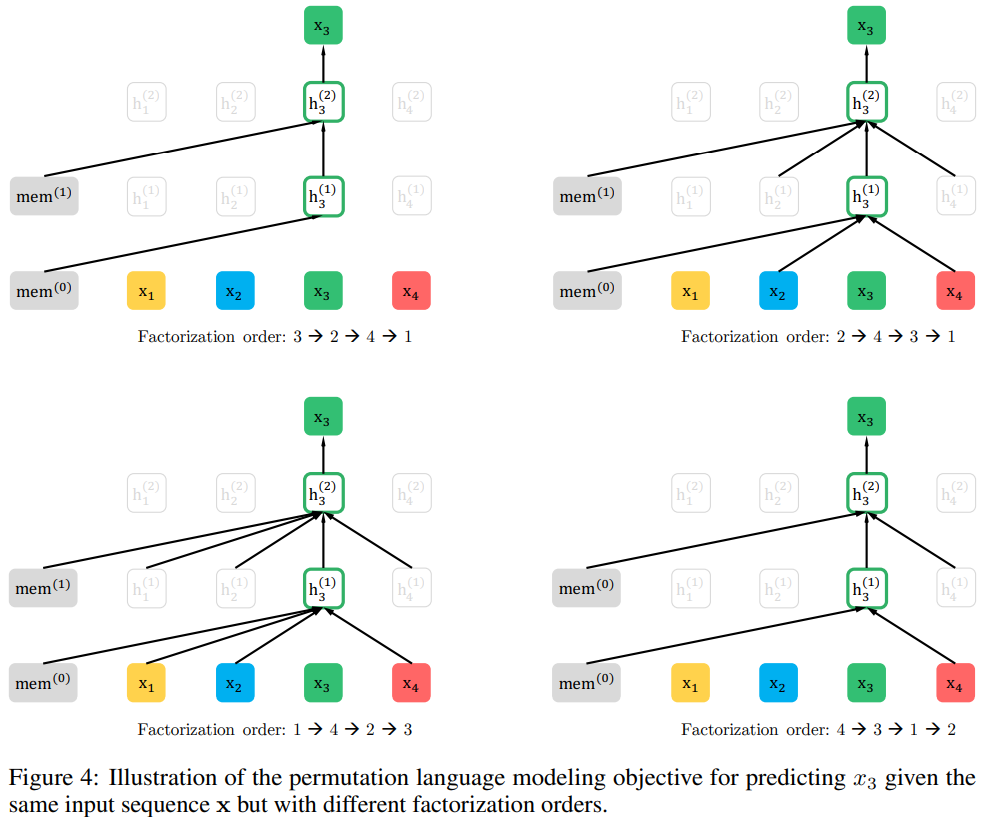
为保持模型输入总是自然序列,适配下游任务,排列操作不在原始输入上进行,而在因子位置上进行,不同因式分解排列的模型输入均是自然序列输入,结合 相对位置编码、注意力掩码,间接排列输入序列。图4为同一序列的不同排列对同一位置token的预测:
结构:基于目标感知的双流注意力
使用标准Transformers预测下一个token的条件概率为 p θ ( X z t ∣ x z < t ) p_\theta(X_{z_t}|\bm x_{\bm z_{<t}}) pθ(Xzt∣xz<t),对于不同的 z t z_t zt,模型对于相同上下文序列 x z < t \bm x_{\bm z_{<t}} xz<t总是输出相同的语义向量,即使用相同语义向量预测不同位置token,显然以此方式训练模型,无法学习有用的表示。
对于同一输入序列 x ∈ R 5 \bm x\in \R^5 x∈R5,有两个不同的因子分解顺序序列(3,1,2,4,5)和(3,1,2,5,4),在预测第4个token时,两个顺序序列对应的语义向量均为 x 1 − 3 \bm x_{1-3} x1−3对应的语义向量,而预测token分别为 x 4 x_4 x4和 x 5 x_5 x5,显然不合理。
为避免使用相同语义向量预测不同位置token,本文 重参数化下一个token概率分布以感知目标位置:
p
θ
(
X
z
t
=
x
∣
x
z
<
t
)
=
exp
(
e
(
x
)
⊤
g
θ
(
x
z
<
t
,
z
t
)
)
∑
x
′
exp
(
e
(
x
′
)
⊤
g
θ
(
x
z
<
t
,
z
t
)
)
(4)
p_\theta(X_{z_t}=x|\bm x_{\bm z_{<t}})=\frac{\exp(e(x)^\top g_\theta(\bm x_{\bm z_{<t}},z_t))}{\sum_{x'}\exp(e(x')^\top g_\theta(\bm x_{\bm z_{<t}},z_t))} \tag 4
pθ(Xzt=x∣xz<t)=∑x′exp(e(x′)⊤gθ(xz<t,zt))exp(e(x)⊤gθ(xz<t,zt))(4)
式中,
g
θ
(
x
z
<
t
,
z
t
)
g_\theta(\bm x_{\bm z_{<t}},z_t)
gθ(xz<t,zt)表示考虑目标位置
z
t
z_t
zt作为输入得到的
x
z
<
t
\bm x_{\bm z<t}
xz<t的上下文信息表示。
通俗理解双流注意力的作用
考虑序列采样因子序列“语言4,喜欢2,处理5,我1,自然3”的预测,如对于预测单词“处理5”,即在给定
g
θ
(
x
z
<
3
,
z
3
)
g_\theta(\bm x_{\bm z<3},z_3)
gθ(xz<3,z3):上下文“语言”、“喜欢”和位置“4”、“2”和“5”,预测位置“5”为单词“处理”的概率,如下图所示。
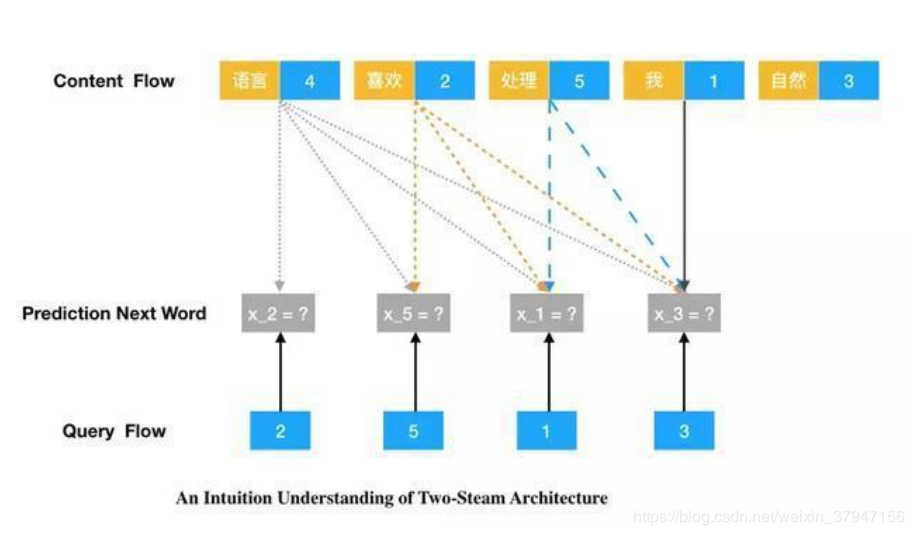
对于位置 z i z_i zi,预测自身token时,仅需提供位置信息、不需提供内容信息,而预测 z j z_j zj, j > i j>i j>i时,需提供位置和内容信息,因此需要Transformer为每个位置提供两个向量表示,一个用于预测自身token的位置表示,另一个用于预测其它位置token的内容表示!
双流自注意力
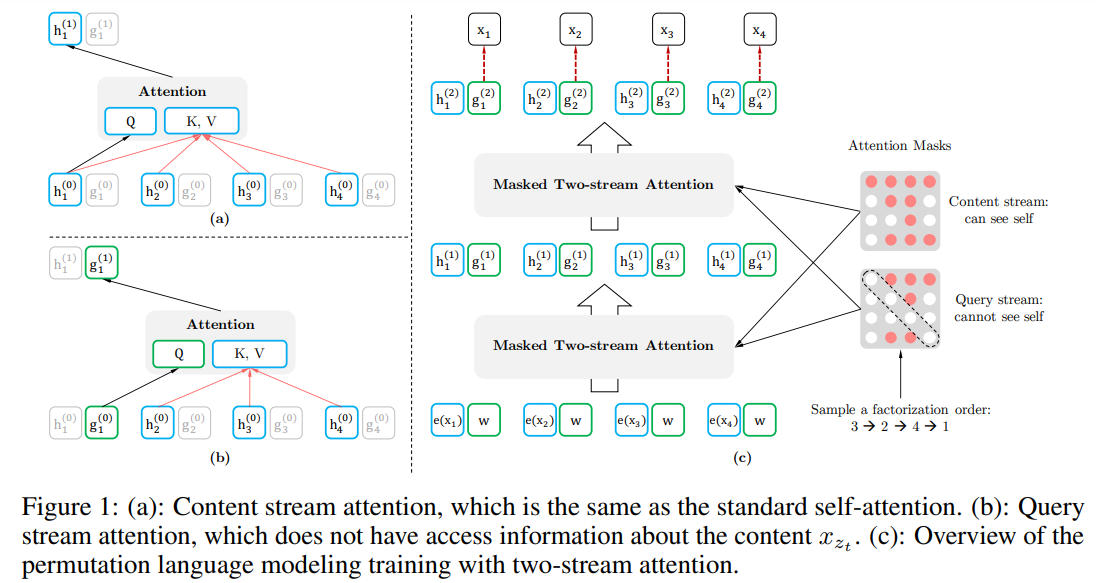
目标感知的表示法解决了目标位置歧义性问题,但如何表达 g θ ( x z < t , z t ) g_\theta(\bm x_{\bm z_{<t}},z_t) gθ(xz<t,zt)仍是一个难题!本文提出的思想是:站在目标位置 z t z_t zt,通过注意力收集 z t z_t zt处的上下文 x z < t \bm x_{\bm z_{<t}} xz<t信息 ,这比传统Transformers多两种需求:
- 如果预测目标是 x z t x_{z_t} xzt,则 g θ ( x z < t , z t ) g_\theta(\bm x_{\bm z_{<t}},z_t) gθ(xz<t,zt)应包含位置信息 z t z_t zt,不能包含内容信息 x z t x_{z_t} xzt;
- 如果预测目标是 x z j x_{z_j} xzj,且 j > t j>t j>t, g θ ( x z < t , z t ) g_\theta(\bm x_{\bm z_{<t}},z_t) gθ(xz<t,zt)应包含内容信息 x z t x_{z_t} xzt ,以提供充足的上下文信息;
为此,我们使用两组隐状态表达,代替一组隐状态:
- 内容表示: h θ ( x z ≤ t ) h_\theta(\bm x_{\bm z_{\leq t}}) hθ(xz≤t), h z t h_{z_t} hzt,与标准Transformer的隐状态相同,包含 x z t x_{z_t} xzt的上下文及其自身内容信息;
- 查询表示: g θ ( x z < t , z t ) g_\theta(\bm x_{\bm z_{<t}},z_t) gθ(xz<t,zt), g z t g_{z_t} gzt,包含 x z t x_{z_t} xzt的上下文内容信息和位置信息 z t z_t zt,不包含内容信息 x z t x_{z_t} xzt;
在计算上,查询流第一层每个位置使用相同的参数向量
w
w
w,内容流第一层每个位置使用对应的词向量,查询流和内容流共享参数,第
m
m
m层查询和内容的更新公式为
g
z
t
m
=
Attention
(
Q
=
g
z
t
(
m
−
1
,
)
,
K
V
=
h
z
<
t
(
m
−
1
)
;
θ
)
h
z
t
m
=
Attention
(
Q
=
h
z
t
(
m
−
1
,
)
,
K
V
=
h
z
≤
t
(
m
−
1
)
;
θ
)
g_{z_t}^m=\text{Attention}(Q=g_{z_t}^{(m-1,)}, KV=h_{\bm z_{<t}}^{(m-1)};\theta)\\[1ex] h_{z_t}^m=\text{Attention}(Q=h_{z_t}^{(m-1,)}, KV=h_{\bm z_{\leq t}}^{(m-1)};\theta)
gztm=Attention(Q=gzt(m−1,),KV=hz<t(m−1);θ)hztm=Attention(Q=hzt(m−1,),KV=hz≤t(m−1);θ)
查询流使用位置信息 z t z_t zt、不使用内容信息 x z t x_{z_t} xzt,内容流使用位置信息 z t z_t zt和内容信息 x z t x_{z_t} xzt。微调阶段,不需要使用查询流,仅使用内容流,此时XLNet与标准Transformer-XL基本一致。最终,将使用最后一层的查询表示带入结合得到 z t z_t zt对应token的概率。
部分预测
排列语言模型收敛慢,难以优化。为降低优化难度,我们仅预测因子顺序序列
z
\bm z
z的后几个token,将
z
\bm z
z在位置
c
c
c处分成前后两个子序列
z
≤
c
\bm z_{\leq c}
z≤c和
z
>
c
\bm z_{>c}
z>c,通过最大化给定
z
≤
c
\bm z_{\leq c}
z≤c下
z
>
c
\bm z_{>c}
z>c的对数似然:
max
θ
E
z
∼
Z
T
[
log
p
θ
(
x
z
>
c
∣
x
z
≤
c
)
]
=
E
z
∼
Z
T
[
∑
t
=
c
+
1
∣
z
∣
log
p
θ
(
x
z
t
∣
x
z
<
t
)
]
(5)
\max_\theta\ \Bbb E_{\bm z\sim\mathcal Z_T}\Big[\log p_\theta(\bm x_{\bm z>c}|\bm x_{\bm z\leq c})\Big]=\Bbb E_{\bm z\sim\mathcal Z_T}\left[\sum_{t=c+1}^{|\bm z|}\log p_\theta(x_{z_t}|\bm x_{\bm z<t})\right] \tag 5
θmax Ez∼ZT[logpθ(xz>c∣xz≤c)]=Ez∼ZT⎣⎡t=c+1∑∣z∣logpθ(xzt∣xz<t)⎦⎤(5)
融合Transformer-XL
XLNet使用先进的AR语言模型Transformer-XL,使用其中两种重要的技术:相对位置编码和循环分段机制。
- 相对位置编码: 对原始序列各位置使用不同的相对位置编码,达到对原始序列排列的效果;
- 循环分段机制: 缓存之前分段各层输出隐状态
h
~
\tilde\bm h
h~,在连续的下个分段中作为扩展上下文长度使用,使得模型可以学习长期依赖,如第
m
m
m层位置
z
t
z_t
zt的隐状态为
h z t ( m ) ← Attention ( Q = h z t ( m − 1 ) , K V = [ h ~ ( m − 1 ) , h z ≤ t ( m − 1 ) ] ; θ ) h_{z_t}^{(m)}\leftarrow \text{Attention}(Q=h_{z_t}^{(m-1)},KV=\left[\tilde\bm h^{(m-1)},\bm h_{\bm z_{\leq t}}^{(m-1)}\right];\theta) hzt(m)←Attention(Q=hzt(m−1),KV=[h~(m−1),hz≤t(m−1)];θ)
多句建模
许多下游任务可能会有多句同时输入,为适配这些下游任务,从相同和不同上下文中分别随机采样两个分句 A A A和 B B B,将其拼接作为模型输入,XLNet输入结构与BERT一致:【CLS,A,SEP,B,SEP】,仅使用相同上下文的缓存。
相对分段编码
BERT对每一个词向量加入绝对句向量,以区分输入中两个句子是否属于同一上下文,由于 绝对句向量仅表示当前输入的两个句子的上下文关系,而XLNet使用缓存不能在词向量添加绝对句向量。如前一分段的两句
A
1
,
B
1
A_1,B_1
A1,B1属于同一上下文,而当前分段的两句
A
2
,
B
2
A_2,B_2
A2,B2不属于同一上下文,但
B
1
B_1
B1和
A
2
A_2
A2属于同一上下文,可见对词向量中添加绝对句向量无法区分不同分段间句子的上下文关系。
本文使用相对分段编码,区分扩展输入序列不同位置token的上下文关系,给定扩展输入序列的两个位置
i
i
i和
j
j
j来自于相同上下文,则
s
i
j
=
s
+
\bm s_{ij}=\bm s_+
sij=s+,否则
s
i
j
=
s
_
\bm s_{ij}=\bm s_\_
sij=s_,
s
+
\bm s_+
s+和
s
_
\bm s_\_
s_是两个在每个注意力头可以学习的向量。计算分句注意力:
a
i
j
=
(
q
i
+
b
)
⊤
s
i
j
a_{ij}=(\bm q_i+\bm b)^\top\bm s_{ij}
aij=(qi+b)⊤sij
式中,
q
i
q_i
qi为查询向量,
b
\bm b
b偏置参数向量,最终将
a
i
j
a_{ij}
aij累计到标准注意力。
讨论
为更好理解BERT和XLNet区别,考虑输入序列[New, York, is, a, city],假设两个模型均以两个单词[New, York]作为预测目标,即最大化概率
log
p
(
New York
∣
is a city
)
\log p(\text{New York }|\text{ is a city})
logp(New York ∣ is a city),同时假设XLNet的因式分解顺序为[is, a, city, New, York],则两者的损失函数为
J
BERT
=
log
p
(
New
∣
is a city
)
+
log
p
(
York
∣
is a city
)
J
XLNet
=
log
p
(
New
∣
is a city
)
+
log
p
(
York
∣
New,
is a city
)
\mathcal J_{\text{BERT}}=\log p(\text{New }|\text{ is a city}) + \log p(\text{York }|\text{ is a city}) \\[.5ex] \mathcal J_{\text{XLNet}}=\log p(\text{New }|\text{ is a city}) + \log p(\text{York }|\text{ {\color{deeppink}New, }is a city})
JBERT=logp(New ∣ is a city)+logp(York ∣ is a city)JXLNet=logp(New ∣ is a city)+logp(York ∣ New, is a city)
XLNet能够捕获待预测tokens以及给定tokens间的依赖关系,而BERT无法捕获待预测tokens间的依赖关系。















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









