






1、问题描述
使用传统的目标分类算法在单张图像上,无法将目标有效的识别,这种问题在图像模糊和目标小的情况下更加明显。使用简单的策略是预测N张图像的结果,并进行统计,出现种类最多的为目标类别。但是简单的进行统计仅仅是一个线性整合,对于复杂场景这种方法不能达到满意的效果。
如下图,有一个三帧视频,分别将每帧输入模型,模型分别预测[ 狗、猫、猫 ],对于我们来说,我们得到66%是猫,33%是狗。但事实真的如此暴力判定吗,如果预测为狗的概率是0.9,两次预测为猫的概率为0.5,0.6,这又会如何影响我们的判定?
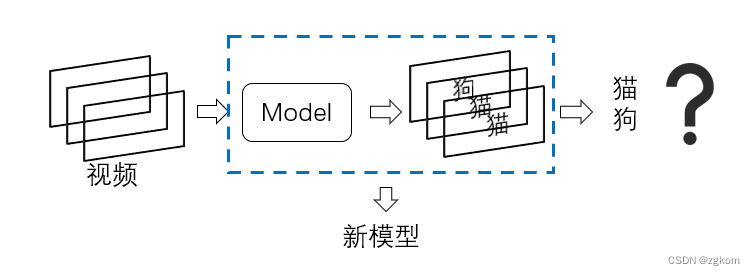
如果我们设计一个模型,接受连续帧,并判定这个连续帧是什么是否就不用考虑以上概率问题。以视频为输入,对视频进行分类,学术上已有领域研究,视频分类Video Classification。
目前预研的模型为TSM,2019年ICCV上的一篇文章,官方论文code,PaddleVideo也实现了该模型。
我这里使用的是官方提供的工程:
2、为什么选择TSM
如下图所示,PaddleVideo给出了解答,轻量高效,适合落地。具体原理看paper或者别人解码,这里不再叙述。

PaddleVideo中还有两种视频分类模型,SlowFast ICCV2019年,TimeSformer ICML2021,有兴趣的可以自行查看。
3、TSM使用
3.1、Kinetics-400数据集下载
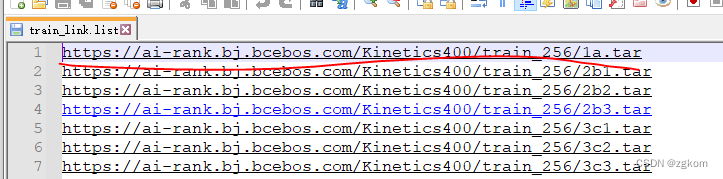
下载教程连接,使用教程中的wget方式下载,可以全部下载,也可以选择下载。
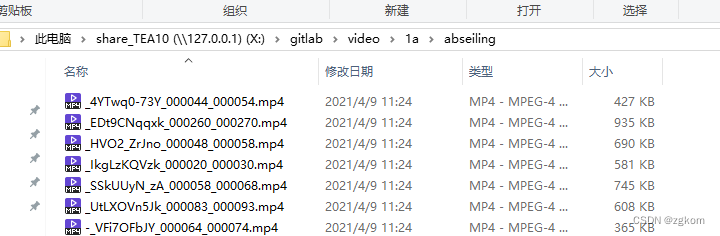
如下图,我训练集只想下载小部分,就可以只下载红线标记部分(1a.tar 3G多)。
1a.tar解压完毕如下,类别也不少
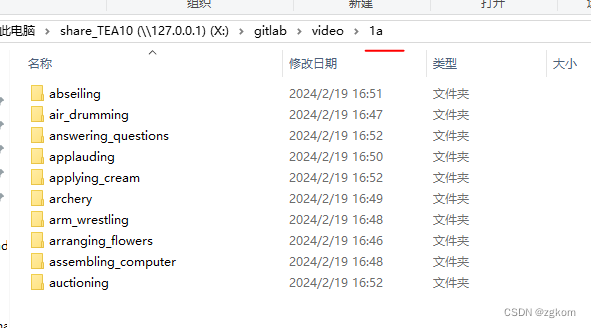
具体类别为12秒的视频
验证集下载相同的操作,较为简单
3.2、Kinetics-400数据预处理
下载完Kinetics-400数据,到输入到模型还需要经过如下步骤

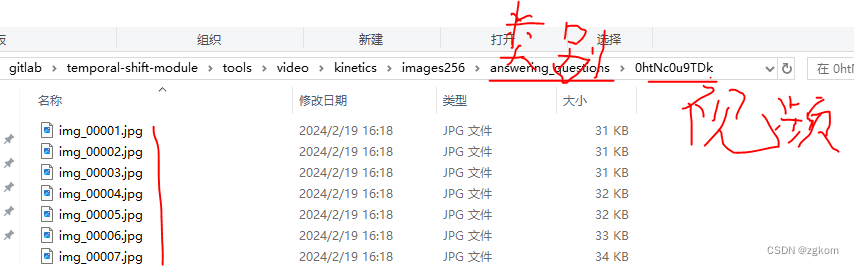
使用官方代码tool/vid2img_kinetics.py将视频转化为 <img_%05d.jpg> 格式的jpeg图像,命令如下
python vid2img_kinetics.py 视频路径 解码图像路径
使用官方代码tool/gen_label_kinetics.py将jpeg图像生成label文件,命令如下
python gen_label_kinetics.py
这个代码需要所谓的csv文件,可以从这里下载:csv文件下载
dataset_path = r'./video/kinetics/imgs_train/' # jpeg路径
label_path = r'./video/kinetics/labels' # csv路径
最后生成的label格式为:
图像相对路径 jepg数量 类别

注意:需要做如下修改:
# folders.append(items[1] + '_' + items[2]) 37行
folders.append(items[1]) # 对val进行label生成
# 对train进行label生成
s1 = '%06d' % int(items[2])
s2 = '%06d' % int(items[3])
folders.append(items[1] + '_' + s1 + '_' + s2)
可能我不是下的原始数据集,下载的csv与数据名称略有差异,但无论如何,只要生成<图像相对路径 jepg数量 类别> 格式,就可以进行模型训练和验证。
3.3、模型推理
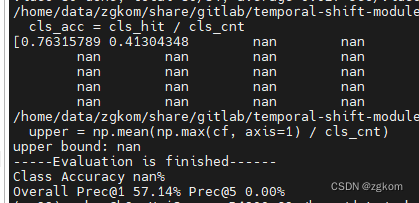
python test_models.py kinetics --weights=pretrained/TSM_k400_RGB_resnet50_shift8_blockres_avg_segment8_e100_dense.pth --test_segments=8 --test_crops=1 --batch_size=1
这里我只使用了两个类别,消去了top5的计算,得到如下结果
3.4、模型训练
目前是测试为主,因此就将Kinetics训练集中的两个类别作为训练集,训练2分类模型
# 修改1, ops/dataset_config.py
def return_kinetics(modality):
filename_categories = 2 # 2类别
if modality == 'RGB':
root_data = ROOT_DATASET + 'kinetics/imgs_train' # 训练图片所在根目录
filename_imglist_train = 'kinetics/labels/train_videofolder.txt' # 存放训练集数据路径相关信息
filename_imglist_val = 'kinetics/labels/val_videofolder.txt' # 存放验证机数据路径相关信息
prefix = 'img_{:05d}.jpg'
else:
raise NotImplementedError('no such modality:' + modality)
return filename_categories, filename_imglist_train, filename_imglist_val, root_data, prefix
#注: 一个视频的img_dir = root_data + filename_imglist_train中相对路径
# 修改2, main.py
# measure accuracy and record loss
prec1 = accuracy(output.data, target)[0] # 去掉top统计
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
# top5.update(prec5.item(), input.size(0)) # 2分类不用top5
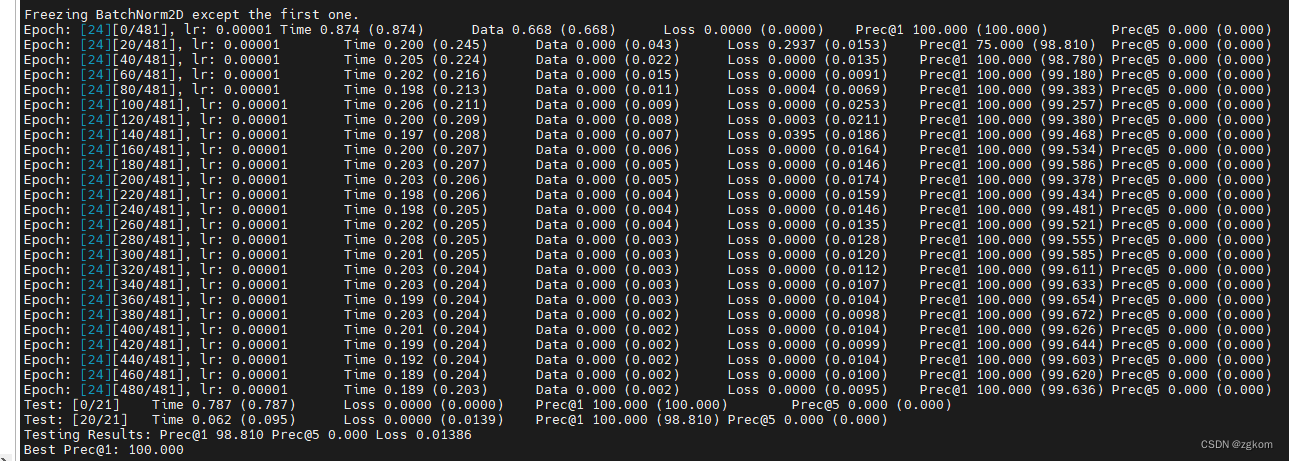
python main.py kinetics RGB --arch resnet50 --num_segments 8 --gd 20 --lr 0.001 --lr_steps 10 20 --epochs 25 --batch-size 4 -j 8 --dropout 0.8 --consensus_type=avg --eval-freq=1 --shift --shift_div=8 --shift_place=blockres --tune_from=pretrained/TSM_k400_RGB_resnet50_shift8_blockres_avg_segment8_e100_dense.pth
训练结果如下,最后2分类竟然能够搞到100%
**注意:**使用现有的模型进行微调,数据集的名称不能出现在模型名子中。比如我修改了kinetics ,400类别变为2类别,TSM_kinetics _RGB_resnet50_shift8_blockres_avg_segment8_e100_dense.pth为400类别的,此时就会出现类别维度不匹配问题,因为kinetics出现在了TSM_kinetics _RGB_resnet50_shift8_blockres_avg_segment8_e100_dense.pth中,因此我将模型修改为TSM_k400 _RGB_resnet50_shift8_blockres_avg_segment8_e100_dense.pth
# main.py 117行
print('#### Notice: keys that failed to load: {}'.format(set_diff))
if args.dataset not in args.tune_from: # new dataset,只有不出现在微调模型中,才会更改fc维度信息
print('=> New dataset, do not load fc weights')
sd = {k: v for k, v in sd.items() if 'fc' not in k}
if args.modality == 'Flow' and 'Flow' not in args.tune_from:
sd = {k: v for k, v in sd.items() if 'conv1.weight' not in k}
model_dict.update(sd)
model.load_state_dict(model_dict)
3.5、模型转换onnx
直接导出会报错
# 修改ops/temporal_shift.py,精度和之前一样
def shift(x, n_segment, fold_div=3, inplace=False):
nt, c, h, w = x.size()
n_batch = nt // n_segment
x = x.view(n_batch, n_segment, c, h, w)
fold = c // fold_div
left_side = torch.cat((x[:, 1:, :fold], torch.zeros(n_batch, 1, fold, h, w, device="cuda")), dim=1)
middle_side = torch.cat((torch.zeros(n_batch, 1, fold, h, w, device="cuda"), x[:, :n_segment - 1, fold: 2 * fold]), dim=1)
out = torch.cat((left_side, middle_side, x[:, :, 2 * fold:]), dim=2)
return out.view(nt, c, h, w)
# 导出函数
def export_onnx(model, batch_size=1, input_shape=(24, 224, 224)):
# #set the model to inference mode
x = torch.randn(batch_size, *input_shape) # 生成张量
model.eval()
with torch.no_grad():
for i in range(10):
t1 = time.time()
pytorch_output = model(x).numpy()
print("i is {0}, time is {1}".format(i, time.time() - t1) )
export_onnx_file = "./output.onnx" # 目的ONNX文件名
torch.onnx.export(model,
x,
export_onnx_file,
opset_version=10,
do_constant_folding=True, # 是否执行常量折叠优化
input_names=["input"], # 输入名
output_names=["output"], # 输出名
dynamic_axes= None
)
# 加载 ONNX 模型,并使用测试数据进行验证
onnx_session = onnxruntime.InferenceSession(export_onnx_file, providers=['CPUExecutionProvider'])
inputs = {onnx_session.get_inputs()[0].name: x.numpy()}
onnx_output = onnx_session.run(None, inputs)[0]
# 比较 PyTorch 和 ONNX 输出的结果
print("convert error:", np.allclose(pytorch_output, onnx_output, rtol=1e-3, atol=1e-5))
# 主函数中执行
# ...
net.load_state_dict(base_dict)
export_onnx(net)
导出模型结果如下
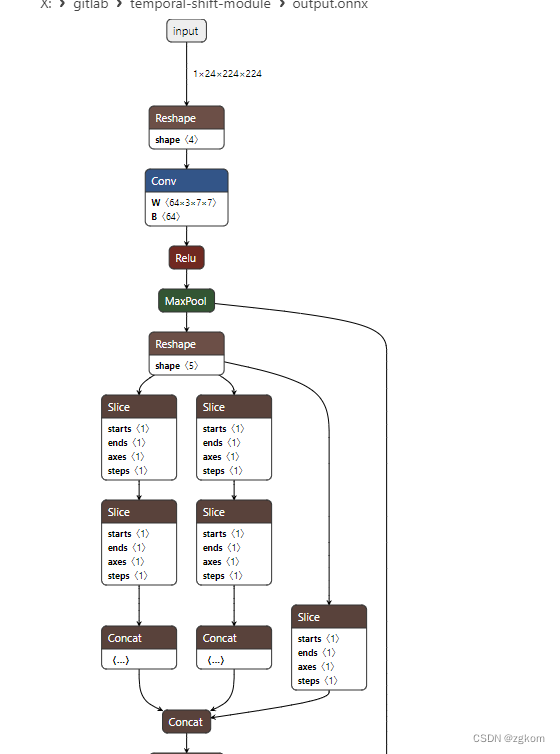
3.6、其他
模型训练,输入Nx24x224x224,8Frame的,如果16frame估计是Nx48x224x224,会对图像按照一定规则进行裁剪,具体看代码吧
模型测试,输入Nx24x224x224,不会对图像进行裁剪,具体看代码吧
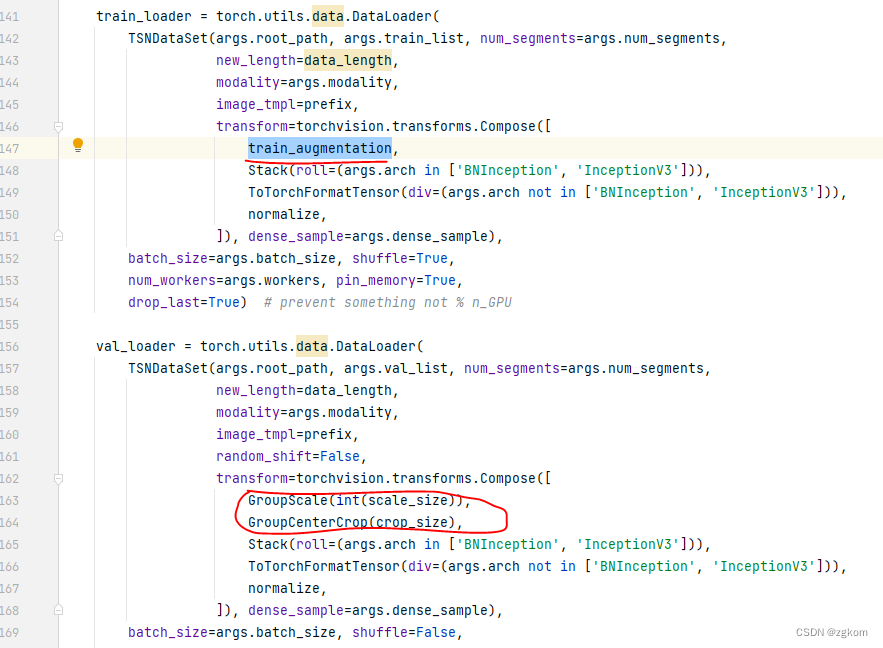
可惜没有自己的视频,否则可以训练测试,目前只在已有的数据集上玩玩。
至此,记录完毕!!!















 1380
1380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









