






1、简介
本文主要用于记录当前阶段对Bytetrack官方代码进行剖析进展,方面后面优化。
ByteTrack 发表于ECCV 2022,顶会的文章,主要用于目标跟踪。整体设计思路较为简单,并且作者在github上开源代码,python及cpp的都有,可以快速使用和部署。看git上介绍,PaddleDetection继承了这个方法。
优点:策略简单,效果好,性能优越,易于部署
关于具体介绍和测试效果,可以去看官方github,这里不涉及使用,仅涉及原理剖析。
还是贴一张效果图吧

2、设计原理
首先看paper上给的原生算法描述:


这里描述一下整体流程并结合CPP源码补充细节
# 同样编写伪代码
输入:视频序列V;目标检测函数Det;检测置信度阈值t
输出:视频轨迹T
初始化轨迹T为空
遍历视频V中的每一帧图像Fk:
Dk一张图像中全部目标检测框集合,初始化为空
D-high,存放置信度大于t的检测框,初始化为空
D-low,存放置信度小于t的检测框,初始化为空
Dk = Det(Fk),Dk为一帧图像中的目标检测框集合,包含位置信息和置信度
遍历检测框集合Dk中的每一个框d
如果d.score(置信度) > t,将d放入集合D-high
否则,将d放入集合D-low
遍历轨迹集合T中的每个轨迹track: // 激活状态的连续轨迹(上一帧追踪到了)和不连续轨迹(上一帧没追踪到)
对轨迹track进行卡尔曼滤波,得到预测状态下的track
// 第一次匹配
使用similarity算法关联轨迹集合T(卡尔曼更新后的)与集合D-high
未匹配到的检测框放入集合D-remain
没有匹配到track的放入集合T-remain,注意这里T-remain只包含激活状态下未匹配的连续轨迹,去除不连续轨迹
// 第二次匹配
使用similarity算法关联轨迹集合T-remain与集合D-low
没有匹配到轨迹track的放入集合T-re_remain,标记为移除状态
没有匹配到的检测框直接丢弃
将T-re_remain从T中移除
到这里翻译完毕,是不是看的一头雾水,因为给的算法隐藏了很多细节,不完整,我重新整理细节
- 输入一帧图像,经过模型输出若干检测框,将检测框分为两种,大于阈值T(用户设定)的为D_high,小于T的为D_low
- 如果是首次计算,因为轨迹为空,将阈值大于S(用户设定)的检测框设置为轨迹TP,并设置为激活状态,等待下一帧,重新执行1
- 对轨迹TP进行卡尔曼滤波,得到新的预测轨迹TP_N,将上一次匹配到(状态tracked)和没有匹配的(状态lost)轨迹分别用T和L表示,则TP=T+L
- 匹配高阈值:计算轨迹TP_N的预测框和检测框D_high的IOU指标,使用IOU进行匹配(这里作者用了lapjv算法,据说是匈牙利算法的10倍性能),匹配到的轨迹保留,这里记作A。则A由部分T和部分L组成;令TP_R=T-A∩T,则未匹配到的检测框记为Box_U
- 匹配低阈值:计算轨迹TP_R的预测框和检测框D_high的IOU,使用IOU进行匹配,匹配到的轨迹保留,这里记作B,未匹配的检测框丢弃。未匹配到的轨迹状态改为lost,记作L_N=TP_R-B
- 匹配未激活轨迹:计算为激活轨迹TP_U与检测框Box_U的IOU,使用IOU进行匹配,匹配到的轨迹保留,这里记作C,未匹配到的轨迹状态标记为移除。未匹配到的检测框记为K=Box_U-C,作为新的未标记轨迹
- 则新的轨迹为TP’ = A + B + C,新的未标记轨迹K,然后重复步骤1
3、流程剖析
使用图形方法展示处理流程
1、轨迹初始化,因为轨迹初始为空,所以第一次进入的检测框,如果置信度大于形成轨迹阈值,就可以作为激活状态的轨迹。
初始化轨迹
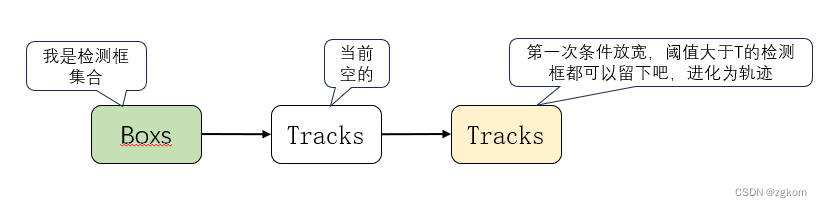
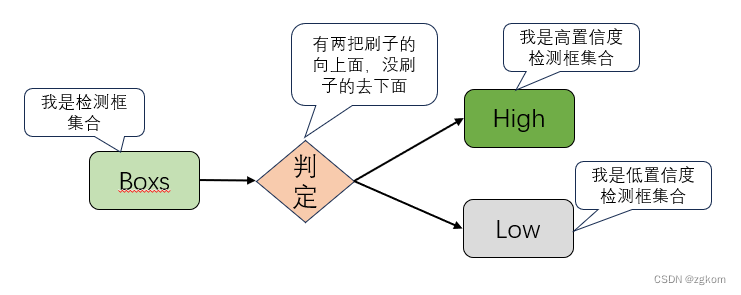
2、根据设置的阈值,将新的检测框划分为高阈值和低阈值,轨迹经过卡尔曼滤波更新自己的位置状态,生成预测框。将预测框和高阈值检测框进行IOU计算,并使用lapjv算法进行匹配。对于没有匹配到的高阈值检测框,后面和未激活状态的轨迹进行再次匹配。
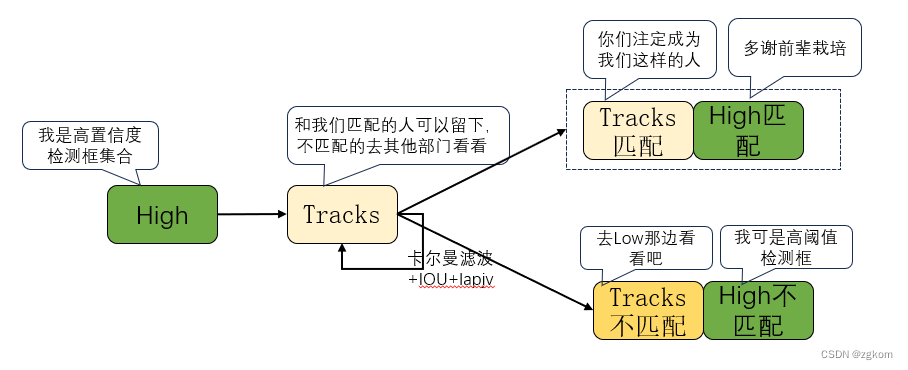
对于没有匹配到的轨迹,再次和低阈值检测框进行匹配。低阈值没有匹配到的检测框直接舍弃,没有匹配到的轨迹状态设置为lost,即当前未匹配的非连续轨迹。
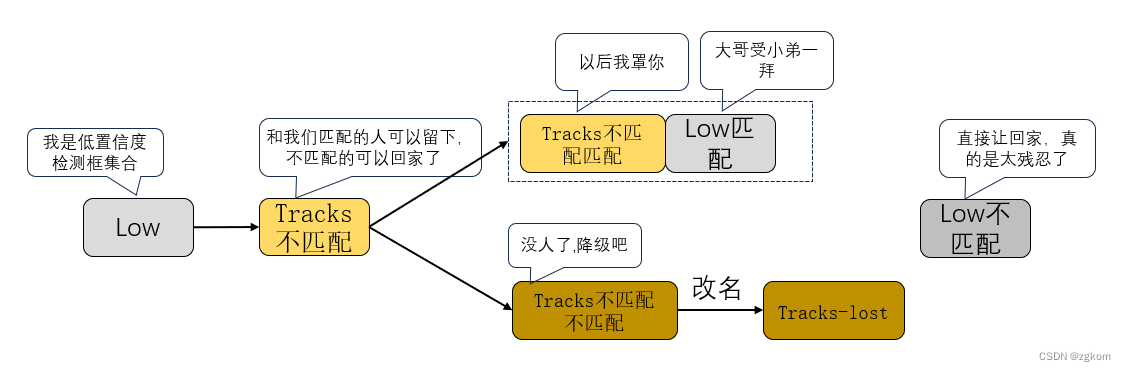
3、对于没有匹配到轨迹的高阈值检测框,如果是首次出现,则将其设置为状态为未激活状态的轨迹,这里设置为Tracks-tmp。
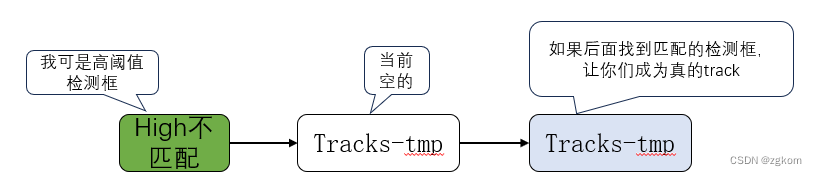
如果Tracks-tmp非空,高阈值检测框和Tracks-tmp进行匹配,匹配到高阈值检测框的轨迹状态设置为激活状态,未匹配到轨迹的高阈值检测框成为新的未激活状态的轨迹。
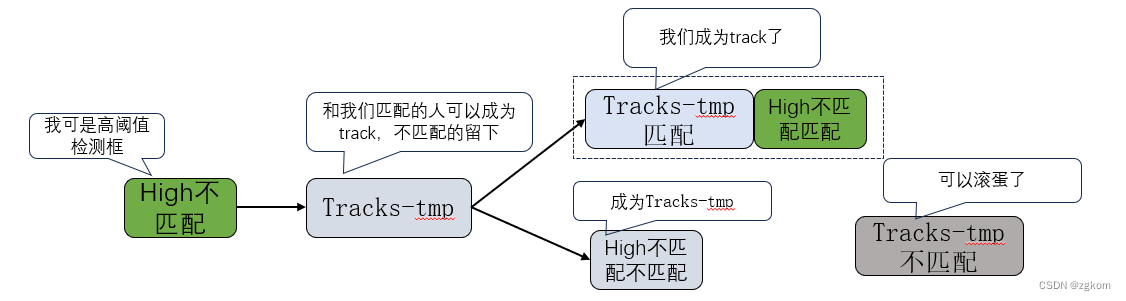
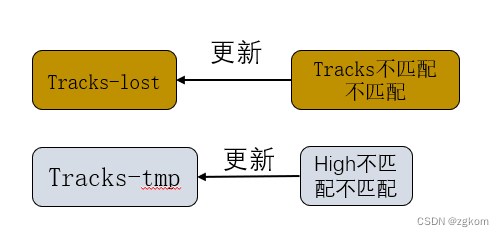
4、进行新的轨迹分类
未激活状态的轨迹Tracks-tmp更新,由未匹配到轨迹的高阈值检测框转化
状态为lost的不连续轨迹Tracks-lost更新,由未匹配到检测框的连续轨迹转化
激活状态,新的连续轨迹,由匹配到检测框的连续轨迹+匹配到检测框的非连续轨迹+匹配到检测框的未激活轨迹组成。
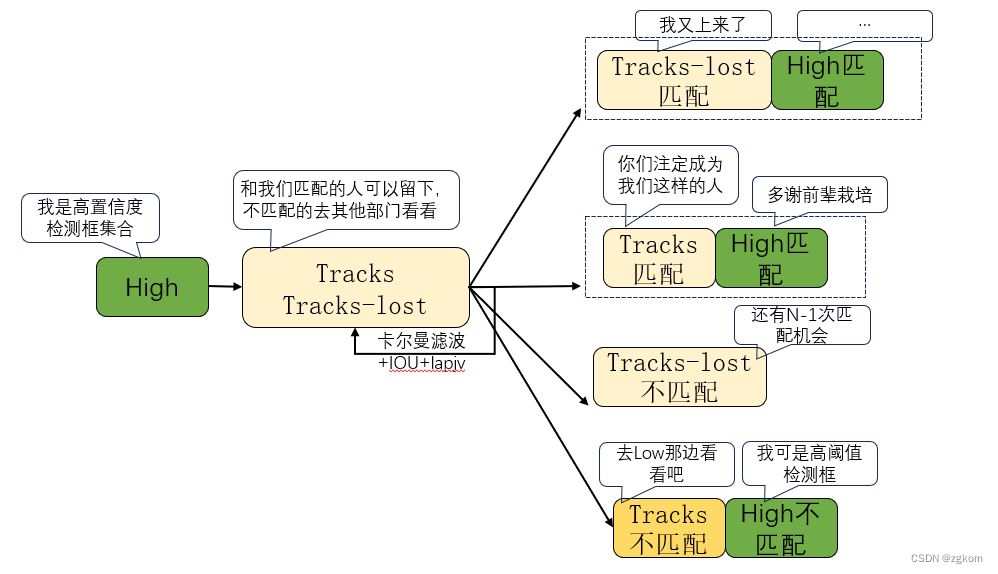
5、新一轮匹配,非连续轨迹也会参加高阈值检测框匹配,但是在低阈值检测框中,不再参与。如果非连续轨迹N次匹配都失败的话,状态设置为移除状态。
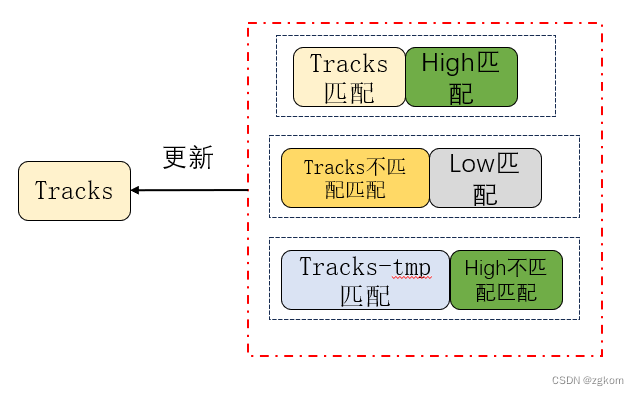
6、剩余的步骤和上面一样,只有状态更新存在差异
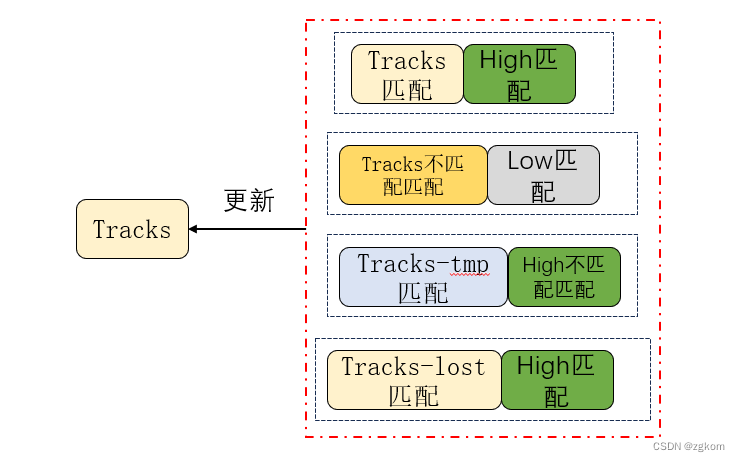
至此,byteTrack整个处理流程完毕!!!
官方源码还是比较啰嗦的,后面准备优化简化流程

















 2712
2712

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









