







一入ML深似海啊…
这里主要是《神经网络与机器学习》(Neural Networks and Learning Machines,以下简称《神机》)的笔记,以及一些周志华的《机器学习》的内容,可能夹杂有自己的吐槽,以及自己用R语言随便撸的实现。
话说这个《神经网络与机器学习》还真是奇书,不知是作者风格还是翻译问题,一眼望去看不到几句人话(也许是水利狗看不懂),感觉我就是纯买来自虐的。
作为开始当然是最古老的机器学习算法之一,神经网络的板砖感知机,对应《神机》的第一章。
因为是Rosenblatt提出的模型所以就加上了他名字作为前缀。这是一个有监督学习,也就是不仅给出自变量还要给出结果值让机器自个拟合的模型,而且是一个二分类模型。再说清楚一点,这玩意只能分线性可分的样本,也就是对于二维的数据,它只能搞一条直线把样本分开,对于三维的数据,只能搞个平面把样本分开。
所以像居然连异或运算都不能弄之类的对它的吐槽历来不少。
感知机概念
感知机由一个线性组合器(说白了就是把一系列输入值加权求和)以及一个硬限幅器(说白了就是拿前面的求和取符号)组成。具体样子参考下图(来自《神机》):
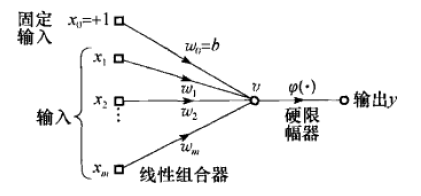
我们将一组输入值记为 x1,x2,...,xm ,相应的权值记为 w1,w2,w3...wm ,另外还要有个偏置值 b (相当于线性回归里边的截距)。把这些输入到感知机里边进行加权求和:
加权和 v 称为 诱导局部域。
然后对这个
y=sign(v)
y={
+1:−1:把x归为类C1把x归为类C2.
可以用逼格更高的矩阵形式简洁表示:
y=sign(wTx+b)
x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









