






这里是《神经网络与机器学习》以及一些《统计学习方法》的笔记。(主要是《神机》坑爹没给SMO或者其他求解算法)
大概知道为啥《神机》这本讲神经网络的书会把SVM放进去了,从结构上看,SVM跟感知机,使用了核方法的SVM跟单隐藏层的神经网络确实非常相似,而当年Vapnic正式提出SVM的论文题目就叫“支持向量网络”。(虽然主要是因为当时神经网络正火而被要求整这名的)
支持向量机(Support Vector Machine,SVM)是一种类似感知机的二分类模型,其原理也是拿一个超平面 wTx+b=0 来将空间中的数据点集分成两类,即正例和负例。对于需要预测的点,落在超平面一侧的归为一类,落在另一侧的归为另一类。
而跟感知机不同的地方在于训练的时候,即使训练集完全是线性可分的,超平面也不是只要能把两堆点集分开就可以,两边正例和负例的离超平面最近的点跟超平面的距离也都必须是最大化的。或者说,超平面必须位于两堆点集之间的正中间才行。
点集是线性可分的情况下,这样的超平面一般是存在且唯一的,被称为最优超平面(Optimal hyperplane)。
这样做的目的是为了不让分离的超平面偏向正例或者负例,让被预测的点有尽可能正确的分类。
具体的样子如下图。
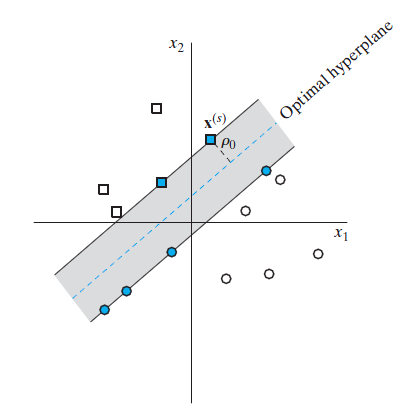
而图上的蓝点,也就是离最优超平面最近的那些点,称为支持向量(Support vector)。
这就是这玩意叫支持向量机的理由。
线性可分模式下的最优超平面
先从最理想的情况,也就是训练集是线性可分的情况说起。
首先有一系列已经分成两类的训练点
x1,x2,⋯,xN
,以及各自对应的期望响应
d1,d2,⋯,dN
,其中
di
分别取值
+1
和
−1
表示其属于不同的两类。
那么其分类方式就可以写成:
记判别函数为 g(x)=wTx+b 。
根据解析几何,点 x 到超平面 wTx+b=0 的距离为:
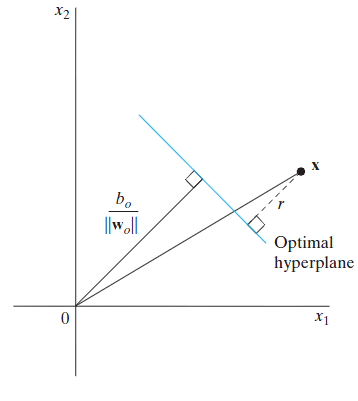
不过上式计算出的距离在点为正例的时候值是正的,而点为负例的时候值是负的。但是由于距离需要为绝对值,而正好正负例的期望响应取值分别为 +1 和 −1 ,所以上式就改写为:
这样计算出来的距离 ri 就横竖都是正的,只要点 xi 被正确分类了 。
当超平面为最优超平面的时候,设离超平面最近的点,也就是支持向量跟超平面的距离为 r∗ ,那么可知每个点 xi 跟超平面的距离都将不小于 r∗ ,也就是:
重新定义
w
和
b
,让
当点 xi 为支持向量的时候,该点即正好落在间隔边界上,上式等号成立,于是其跟超平面的距离 r∗ 就是:
接下来就是怎么定义支持向量机的最优化目标。
由于
∥w∥=wTw
,那么可以设定代价函数为
Φ(w)=12wTw
,这样最小化代价函数的时候
r∗
也就得到了最大化。
那么线性可分的支持向量机的最优化问题就可以定义为如下:
这是一个有约束最优化问题。
拉格朗日乘子方法
可知这个最优化问题的代价函数
Φ(w)
是
w
的凸函数,而且约束条件关于
w
是线性的。这样就可以用拉格朗日乘子方法来解决这个问题。
所谓的拉格朗日乘子方法基于拉格朗日对偶性的理论,就是建立一个加入了拉格朗日乘子的拉格朗日函数,对其取极大极小来构造一个对偶问题(dual problem),再解决对偶问题,从而解决原问题。在上边所说的情况下,对偶问题的最优解也就是原问题的最优解。
首先建立拉格朗日函数:
我们需要拿这个函数关于
w
和
b
取极小。这就是原始问题。
然后对其在关于
由此可以看出拉格朗日乘子方法其实就是将优化的目标函数跟约束条件简单粗暴得套在一起,成为拉格朗日函数,并为约束条件的每一项乘上一个称为拉格朗日乘子的系数。
其对于约束条件的想法就是,因为是关于拉格朗日乘子取极大,所以要是有其中一项约束条件没有满足,那么拉格朗日函数就会趋于正无穷,也就没法关于
w
和
b
取极小了。就是这样来保证约束条件的满足。
根据拉格朗日对偶性理论,原始问题和对偶问题都获得最优解的充要条件是满足KKT(Karush-Kuhn-Tucker)条件。
KKT条件之一要求拉格朗日函数对
解得:
可知 w 是可以用对偶问题的解 α1,α2,⋯ 来表示的。
再把上边俩式子带入到
J(w,b,α)
中并整理可得:
这样得到了如下的对偶问题:
根据拉格朗日对偶性理论,KKT条件中还有一个条件为:
从中可知,只有当 di(wTxi+b)−1=0 ,即 xi 为支持向量的时候,才有 αi>0 ,否则 αi=0 ,因而根据:
因而可以随便拿一个对应的 αj>0 的序号 j 来获得超平面的另一个系数
综上,只有解决了对偶问题,求出最优的拉格朗日乘子 α1,α2,⋯,αN ,才可以进一步解得最优超平面的系数 w 和 b 。
而对偶问题的解决就不能只靠公式推导了,目前基本上都是使用数值解法,其中最主流的就是SMO算法。
不可分模式的最优超平面
这里的对应的是点集大致上线性可分,但是严格来说线性不可分的情况,也就是正例负例的点大致上是可以用一个超平面分开的,但是由于噪声、误分类等原因总有那么一些点跑到了另一边导致了线性不可分。
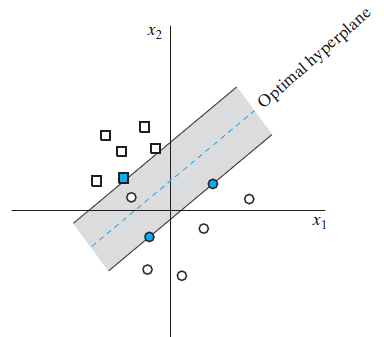
前文给出的方法是用于严格线性可分情况的,在这里就行不通了。所以对于这种情况,为了消除这些站错队的点的干扰,解决方式就是给每个点
理所当然的肯定不能让点集在总体上跑偏的太多。于是代价函数就要考虑上松弛变量:
这样就获得要获得线性不可分情况下的最优超平面,也称为软间隔最大化的最优化原始问题如下:
前文的线性可分的情况实际上是这里 ξi=0 时的特殊情况。
同样的套路,对其构造拉格朗日函数并对 w,b,ξ 求偏导数再让其为零,即可整出对偶问题如下:
再使用SMO等方法解出 α1,α2,⋯,αN ,就可以计算出 w :
然后随便找一个让 0<αj<C 的 j 来解得系数
训练完毕,进行未分类点的预测时,分类决策函数为:
或者写成用 α 表示的形式:
线性不可分情况下的支持向量
对于点
xi
是不是支持向量依然可以由对偶问题的解
α1,α2,⋯,αN
确定,
αi>0
的时候对应的
xi
就是支持向量,否则就不是。
而跟前文线性可分的情况有所不同的是,这里的支持向量不仅仅是刚好落在间隔边界上的点,落在俩间隔边界中间,包括正好在最优超平面上,甚至跑出了最优超平面跑到了对面的点都是支持向量。
如果满足 0<αi<C ,那么点 xi 就是“正统”的支持向量,刚好落在间隔边界上,点 xi 称为无界的支持向量,或者自由支持向量(《神机》语)。
如果
αi=C
,那么点
xi
就是不落在间隔边界上,而是位于间隔边界另一侧的某个位置的支持向量。(我怎么觉得这才应该叫自由支持向量)
而对于这种支持向量具体在哪就得看对应的
ξi
取值。
0<ξi<1
的时候,点
xi
依然在最优超平面的分类正确的一侧;
ξi=1
时,点
xi
正好落在最优超平面上;
ξi>1
时,点
xi
就跑最优超平面的另一边去了。
所以用来求解
b
的
另外上边的方法只能单方向从 αi 的取值来确定点 xi 的情况,反过来只知道 xi 在间隔边界上是不能确定对应的 αi 的…
使用核方法的支持向量机
这里对应的是真正意义上的点集线性不可分的情况,比如负例的点分布呈一个环将正例包围起来。这时是完全不可能拿平面来将点集分开了。
在这里支持向量机用的就是跟前一章径向基函数网络用的一样的核方法,既然在原来的空间里点集线性不可分,那就索性用某种转换将点集映射到另一个维度更高的空间里去,使之变得线性可分,再拿前文的软间隔最大化的线性方法搞之。在使用核方法的模型里边,支持向量机是玩的最溜的。
这里把点集原本所在的空间称为输入空间,被映射到的高维空间称为特征空间。
而跟径向基函数网络不同的地方在于,径向基函数网络即使是将点集映射到高维空间之后的维数也通常是有限的,而支持向量机映射到的空间则是无限维的(希尔伯特空间)。
希尔伯特空间可认为是欧氏空间的无穷维的推广,但其中向量的距离、内积等都还是生效的。
定义转换
ϕ(x)={ϕj(x)}∞j=1
,将点
x
从
m0
维的输入空间映射到无限维的特征空间,变成无穷维的向量。
那么在特征空间里的超平面参数便如此表示:
于是分类决策函数就变成这样:
那么问题来了,既然被映射到的特征空间理论上可以是无穷维的,那么在实际中怎么把这个无穷维的特征空间的数据实现呢?
其实往前翻你可以发现在实际计算的公式里边,包括对偶问题以及分类决策函数,样本点都是表示成俩向量内积( xTixj )的形式的。所以把 xi 替换成 ϕ(xi) 之后就基本上都是形如 ϕ(xi)Tϕ(x) 的内积形式。
内积的结果是标量,所以这里就定义了一个函数
k(xi,xj)=ϕ(xi)Tϕ(xj)
来取代之,这样以后就都只研究
k(xi,xj)
就好了,不用去纠结这个变换
ϕ(xi)
具体啥样了,无穷维的向量的表示问题就这样绕过了。
这个方法就是传说中的核技巧(kernel trick)。
定义 ϕ(xi) 是一个从输入空间(欧氏空间)到特征空间(希尔伯特空间)的映射,对于任意的两个输入空间中的向量 xi 、 xj ,都有下式成立:
那么 k(xi,xj) 就称为 内积核或者 核函数或者简称 核。
于是分类决策函数就可以改写为:
把 k(xi,xj) 简写成 ki,j ,对偶问题的目标函数就可以表示为:
内积核
接下来的问题就是满足条件的核函数该怎么找。
当然了,并不是所有的形如
k(xi,xj)
的函数都可以作为核函数。这里先介绍几个公认的常用的核函数:
- 多项式核函数(
p
为自定义参数):
k(xi,xj)=(xTixj+1)p - 高斯径向基核函数(
σ
为自定义参数):
k(xi,xj)=exp(−∥xTixj∥2σ2) - 两层感知器核函数(
β0、β1
为自定义参数,但并不是所有的值都满足核函数的要求):
k(xi,xj)=tanh(β0xTixj+β1)
至于要什么样的函数
k(xi,xj)
才能成为核函数的问题,牵扯上了泛函分析的各种高端理论,这里就只给出充要条件好了:
若对于任意
x1,x2,⋯,xm
,关于
k(xi,xj)
的m阶的Gram矩阵
K=[k(xi,xj)]m×m
也就是元素为对
x1,x2,⋯,xm
中的各个向量两两之间求得的
k(xi,xj)
的值的矩阵为半正定矩阵,那么
k(xi,xj)
就是符合要求的核函数,也称正定核。
其实线性支持向量机可视为是特殊情况下的非线性支持向量机,此时核函数 k(xi,xj)=xTixj 。
综上,支持向量机的对偶问题为如下:
其中 kij=k(xi,xj) 。
SMO算法
前边说过,支持向量机的对偶问题的解基本上没法用公式套出来,只能使用近似的数值解法,其中最应用最广的一种就是序列最小优化算法(Sequence-Minimal Optimization),也即是SMO算法。
SMO算法的基本想法就是两个两个地优化
α
值,在每次优化的时候都选取两个
α
来优化,其他的
α
当作是常量,这样将多个变量的有约束最优化问题转化为了两个变量的最优化问题,并且经过若干轮优化之后,对偶问题将趋于整体的最优化。这里有点类似于随机梯度下降的思想。
至于为啥是同时选取俩 α 而不是一个进行优化,是因为只选一个 α 优化的话就破坏约束条件(I)了。
过程如下:
首先假设在某一步已经通过某种方法选中了一对
αi
跟
αj
并欲优化之,同时固定其他
α
为常量,那么对偶问题的最优化目标函数就可以整理成下面的二元二次函数:
约束条件(I)就成了这样:
不过通常情况等号右边的部分也挺费计算量的,所以一般不会算等号右边,而是保留优化前的 α 值 αi0 跟 αj0 :
反正要求序列总和保持为0,而且其他 α 也没变动嘛。
而约束条件(I)就成了一二元一次方程,将其代入上面的整理后的目标函数再消去个 αi ,就完全成了一元二次函数 Q(αj) 了。除了麻烦系数有点高,难度系数上看估计初中水平都可以解出来。
再看看约束条件(II),成了酱紫:
把约束条件(I)带入(II)消去 αi 就简化成了下边的只有单个变量的形式:
其中:
对于目标函数的优化策略可以按高中数学函数题的解法来想,先不管约束条件,令导数为0解出让 Q(αj) 最小时的 αuncj ,然后将其跟约束条件区间的边界L和H比较,要是 αj 介于L和H之间 αj 就取这个 αuncj ,要是跑出了区间就取靠近的那个边界值。
经推导获得的不考虑约束的
Q(αj)
最小时的
αuncj
为:
其中
然后
解出了 αj 之后就可以拿约束条件(I)把 αi 也解出来:
这样一轮优化完毕。
#
接下来的问题就是如何科学有效得选择 αi 跟 αj 了。
SMO的想法是先找违反约束条件最严重的点对应的 α 作为 αi ,这个过程叫外循环;然后是依据已经找好了的 αi 找配套的 αj 。由前面可以知道,优化前后 αj 的该变量主要是由 Ei 跟 Ej 的差值决定的,所以一般是按照让 Ei 跟 Ej 差距最大的策略决定 αj ,这个过程叫内循环。
这里约束条件可以表示成酱紫:
更新完
αi
跟
αj
之后还要接着更新
b
:
如果满足更新后
如果满足更新后 0<αj<C ,那么 b 也可以这样更新:
如果都上边俩条件都一起满足了那么应该有 b1=b2 ,这时可以随便选择一个作为新的 b 。
但如果有一个















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









