






最近因学习任务,对语音识别需要了解,所以现在就把一些学习过程遇到的问题解决方法分享给大家。首先pyhon提供了许多语音识别库,大致包含:
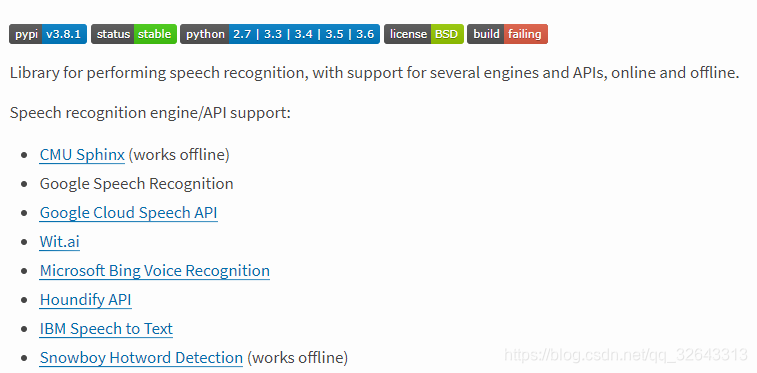
上述语音识别软件库各个之间的侧重点不同,如:谷歌云语音侧重语音向文本转换,又如wit与apiai还提供超出基本语音识别的内置功能(识别讲话者意图的自然语言处理功能)。由于我仅仅是做简单的中文语音识别,所以使用的是SpeechRcognition这个语音识别库。
SpeechRcognition的特点优势
- 满足几种主流语音 API ,灵活性高;
- Google Web Speech API 支持硬编码到 SpeechRecognition 库中的默认 API 密钥,无需注册就可用;
- SpeechRecognition无需构建访问麦克风和从头开始处理音频文件的脚本, 只需几分钟即可自动完成音频输入、检索并运行。因此易用性很高。
怎么使用SpeechRcognition?
1. 安装SpeechRcognition
下载地址:https://pypi.org/project/SpeechRecognition/
安装命令: pip install SpeechRcognition
不过仅仅安装这个是不够的,还需要安装对应需要的资源库,如下图:

2. SpeechRcognition的识别类(器)

以上七个中只有 recognition_sphinx()可与CMU Sphinx 引擎脱机工作, 其他六个都需要连接互联网。另外,SpeechRecognition 附带 Google Web Speech API 的默认 API 密钥,可直接使用它。其他六个 API 都需要使用 API 密钥或用户名/密码组合进行身份验证。
3. 下面进行中文语音识别
我在这里使用的是recognize_sphinx()语音识别器,它可以脱机工作,但是必须安装pocketsphinx库(详细安装过程见https://blog.csdn.net/zouxy09/article/details/7942784),若要进行中文识别,还需要两样东西。一、语音文件(SpeechRecognition对文件格式有要求);二、中文声学模型、语言模型和字典文件,下面进行详细描述:
SpeechRecognition支持语音文件类型
WAV: 必须是 PCM/LPCM 格式
AIFF
AIFF-C
FLAC: 必须是初始 FLAC 格式;OGG-FLAC 格式不可用
pocketsphinx需要安装的中文语言、声学模型
下载地址:http://sourceforge.net/projects/cmusphinx/files/Acoustic%20and%20Language%20Models/
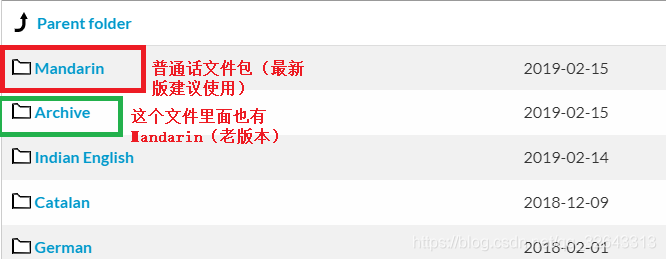
安装步骤
- 下载cmusphinx-zh-cn-5.2.tar.gz并解压
- 在python安装目录下找到Lib\site-packages\speech_recognition
点击进入pocketsphinx-data文件夹,并新建文件夹zh-CN

在这个文件夹中添加进入刚刚解压的文件,需要注意:把解压出来的zh_cn.cd_cont_5000文件夹重命名为acoustic-model、zh_cn.lm.bin命名为language-model.lm.bin、zh_cn.dic中dic改为dict格式。

中文识别实际例子
1. 实际的代码程序
# -*- coding: utf-8 -*-
# /usr/bin/python
# 作者:kimicr
# 实验日期:20190820
# Python版本:3.6.3
import speech_recognition as sr
r = sr.Recognizer() #调用识别器
test = sr.AudioFile("C:\\Users\cc\Desktop\\test1.flac") #导入语音文件
with test as source:
audio = r.record(source)
type(audio)
c=r.recognize_sphinx(audio, language='zh-cn') #识别输出
print(c)
输出的结果:由于语音自己录的不好,所以识别的不是很高。可以找例子多试试

2. 程序中可能出现的问题
一般出现问题在于这一行代码:test = sr.AudioFile(“C:\Users\file\Desktop\test1.flac”) #导入语音文件。出现的问题为:

这是由于该文件地址是直接通过打开文件属性方式,摘到文件路径,复制过来的,问题出现是可能里面包含有了非法字符,解决办法就是重新手动输入这一行代码(特别是文件路径)

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









