







 本文介绍了在大规模数据集上进行机器学习的方法,重点讨论了随机梯度下降(SGD)及其变种小堆梯度下降(Mini-Batch GD)。SGD通过每次仅用一个样本进行参数更新,提高了学习效率。此外,文章还探讨了在线学习的重要性,以及如何在实际应用中利用Map Reduce和数据并行化加速训练过程。
本文介绍了在大规模数据集上进行机器学习的方法,重点讨论了随机梯度下降(SGD)及其变种小堆梯度下降(Mini-Batch GD)。SGD通过每次仅用一个样本进行参数更新,提高了学习效率。此外,文章还探讨了在线学习的重要性,以及如何在实际应用中利用Map Reduce和数据并行化加速训练过程。
本博客是针对Andrew Ng在Coursera上的machine learning课程的学习笔记。
在大数据集上进行学习(Learning with Large Data Sets)
由于机器学习系统的性能表现往往要求其算法是low biased(在训练集上的训练误差小),并且在尽可能大的数据集上做训练。
It's not who has the best algorithm that wins. It's who has the most data.
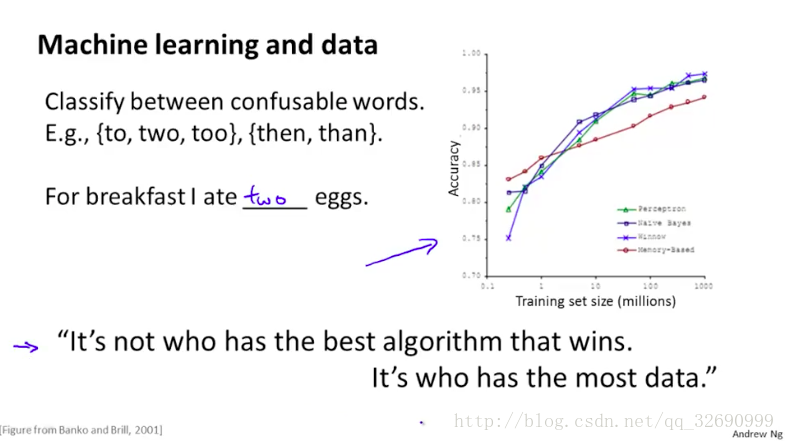
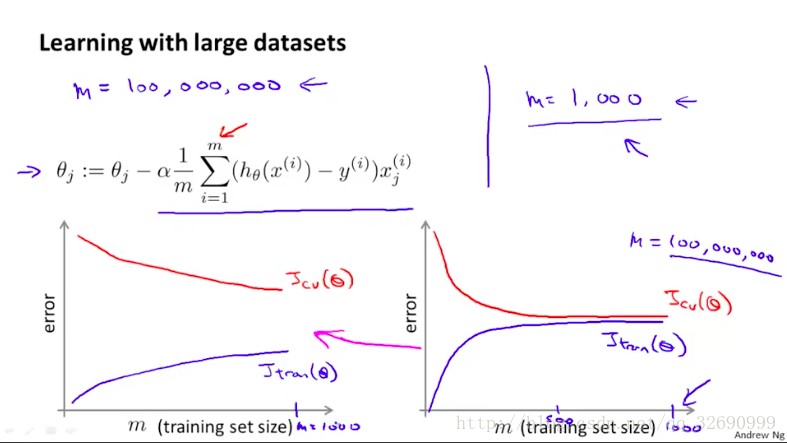
比如对于一般线性回归或者logistic回归,有如图的参数迭代更新的公式,假设我们如果有一百万个训练样本(m=100,000,000),则每一次更新参数都需要做一百万次的加和,那么计算量就很大。另外,对于high bias的算法学习曲线(如下图的靠右图),此时增加样本数量也不太可能减少误差,可能合适地增加输入特征才是更有效的。而如左边的情况high variance,用更大的数据集是更有效的。
随机梯度下降(Stochastic Gradient Descent)
由于之前讲的梯度下降(又称Batch Gradient Descent)在样本量大时计算量非常大,更新速度会很慢,为了避免这个问题,我们可以采用随机梯度下降。
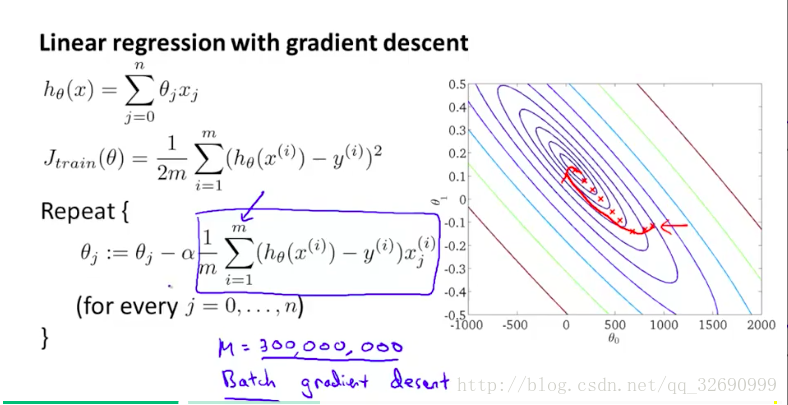
具体做法是:我们不再在对参数进行更新时遍历加总所有样本的误差值,而是每次迭代更新从中只随机选取一个样本进行误差计算,(本质是先将数据集打乱,再逐一进行参数学习,但还是要对所有的样本进行一次遍历),因此保证了参数是在快速地向全局最优解靠近的(但可能由于样本选取的随机性,导致梯度下降的方向并不是那么稳定地向全函数最小值处行进,相当于是牺牲稳度换取速度)。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 90
90

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









