









Ten Advanced Optimizations of Cache Performance
前面的平均内存访问时间公式为我们提供了缓存优化的三个指标:命中时间、未命中率和未命中惩罚。 鉴于最近的趋势,我们将缓存带宽和功耗添加到此列表中。 我们可以根据这些指标将我们检查的 10 项高级缓存优化分为五类:
- 减少命中时间——小而简单的一级缓存和路预测。 这两种技术通常还可以降低功耗。
- 增加缓存带宽——流水线缓存、多组缓存和非阻塞缓存。 这些技术对功耗有不同的影响
- 减少未命中惩罚——关键字优先并合并写入缓冲区。 这些优化对功耗影响不大。
- 降低未命中率——编译器优化。 显然,编译时的任何改进都会提高功耗。
- 通过并行性——硬件预取和编译器预取来减少未命中惩罚或未命中率。 这些优化通常会增加功耗,主要是因为未使用的预取数据。
一般来说,随着我们进行这些优化,硬件复杂性会增加。 此外,一些优化需要复杂的编译器技术,最后一个依赖于 HBM。 我们将总结第 113 页的图 2.18 中展示的 10 种技术的实现复杂性和性能优势。因为其中一些很简单,所以我们简要介绍; 其他需要更多描述。
First Optimization: Small and Simple First-Level Caches
to Reduce Hit Time and Power
快速时钟周期和功率限制的压力鼓励一级缓存的大小有限。 同样,使用较低级别的关联性可以减少命中时间和功率,尽管这种权衡比涉及大小的权衡更复杂。
高速缓存命中中的关键时序路径是三个步骤的过程:使用地址的索引部分对标签存储器进行寻址,将读取的标签值与地址进行比较,以及设置多路复用器以选择正确的数据项(如果高速缓存是 设置关联。 直接映射缓存可以将标签检查与数据传输重叠,有效减少命中时间。 此外,较低级别的关联性通常会降低功耗,因为必须访问的缓存行较少。
尽管新一代微处理器的片上缓存总量大幅增加,但由于更大的 L1 缓存对时钟速率的影响,L1 缓存的大小最近略有增加或根本没有增加。 在最近的许多处理器中,设计人员选择了更多的关联性
而不是更大的缓存。 选择关联性的另一个考虑因素是消除地址别名的可能性; 我们很快就会讨论这个话题。

在构建芯片之前确定对命中时间和功耗的影响的一种方法是使用 CAD 工具。 CACTI 是一个程序,用于在更详细的 CAD 工具的 10% 内估算 CMOS 微处理器上替代缓存结构的访问时间和能耗。对于给定的最小特征大小,CACTI 估计缓存的命中时间是缓存大小、关联性、读/写端口数和更复杂参数的函数。图 2.8 显示了缓存大小和关联性不同时对命中时间的估计影响。根据缓存大小,对于这些参数,模型建议直接映射的命中时间比二路集关联略快,二路集关联速度是四路的 1.2 倍,四路是 八路速度的1.4倍。当然,这些估计取决于技术以及缓存的大小,CACTI 必须谨慎地与技术保持一致;图 2.8 显示了一种技术的相对权衡。

在选择缓存大小和关联性时,能耗也是一个考虑因素,如图 2.9 所示。 当从直接映射到双向集关联时,更高关联性的能量成本从 2 倍以上到在 128 或 256 KiB 的缓存中可以忽略不计。
随着能源消耗变得至关重要,设计人员专注于降低缓存访问所需能源的方法。 除了关联性之外,决定缓存访问所用能量的另一个关键因素是缓存中的块数,因为它决定了访问的“行”数。 设计人员可以通过增加块大小(保持总缓存大小不变)来减少行数,但这可能会增加未命中率,尤其是在较小的 L1 缓存中。
另一种方法是将高速缓存组织成组,以便访问仅激活高速缓存的一部分,即所需块所在的组。 多组缓存的主要用途是增加缓存的带宽,我们很快就会考虑这种优化。 Multibanking 还降低了能耗,因为访问的缓存较少。 许多多核中的 L3 缓存在逻辑上是统一的,但在物理上是分布式的,并且有效地充当多组缓存。 根据请求的地址,实际上只访问一个物理 L3 缓存(一个bank)。 我们将在第 5 章进一步讨论这个组织。
在最近的设计中,尽管存在能源和访问时间成本,但还有其他三个因素导致在一级缓存中使用更高的关联性。 首先,许多处理器至少需要 2 个时钟周期来访问缓存,因此更长的命中时间的影响可能并不重要。 其次,为了使 TLB 远离关键路径(延迟将大于与增加关联性相关的延迟),几乎所有的 L1 缓存都应该被虚拟索引。 这将缓存的大小限制为页面大小乘以关联性,因为只有页面内的位用于索引。 在地址转换完成之前索引缓存的问题还有其他解决方案,但增加关联性,这也有其他好处,是最有吸引力的。 第三,随着多线程的引入(参见第 3 章),冲突未命中会增加,从而使更高的关联性更具吸引力。
Second Optimization: Way Prediction to Reduce Hit Time
另一种方法减少冲突未命中,同时保持直接映射缓存的命中速度。 在路径预测中,额外的位保存在缓存中以预测下一个缓存访问的路径(或集合中的块)。 这种预测意味着多路复用器被提前设置以选择所需的块,并且在该时钟周期内,只有一个标签比较与读取缓存数据并行执行。 未命中会导致在下一个时钟周期检查其他块是否匹配。
添加到缓存的每个块的是块预测器位。这些位选择在下一次缓存访问中尝试使用哪些块。如果预测器正确,则缓存访问延迟是快速命中时间。如果没有,它会尝试另一个块,改变预测器的方式,并有一个额外的时钟周期的延迟。模拟表明两路集合关联缓存的集合预测准确度超过 90%,四路集合关联缓存的集合预测准确度超过 80%,I-cache 的准确度比 D-cache 更好。如果双向设置关联缓存的速度至少快 10%,那么路径预测会产生更低的平均内存访问时间,这很有可能。路预测在 1990 年代中期首次用于 MIPS R10000。它在使用二路集关联性的处理器中很流行,并在几个具有四路集关联缓存的 ARM 处理器中使用。对于非常快的处理器,实现单周期停顿可能具有挑战性,这对于保持路预测惩罚较小至关重要。
路预测的扩展形式也可以用于通过使用路预测位来决定实际访问哪个缓存块来降低功耗(路预测位本质上是额外的地址位);这种方法可以称为路径选择,当路径预测正确时可以节省功率,但会在路径错误预测上增加大量时间,因为必须重复访问,而不仅仅是标签匹配和选择。这种优化可能只在低功耗处理器中有意义。井上等人。 (1999) 估计,在 SPEC95 基准测试中,使用带有四路组关联缓存的路选择方法将 I-cache 的平均访问时间增加了 1.04,D-cache 的平均访问时间增加了 1.13,但它产生了平均缓存能力相对于普通四路组关联缓存的消耗,I-cache 为 0.28,D-cache 为 0.35。方式选择的一个显着缺点是难以通过管道进行缓存访问;然而,随着能源问题的增加,不需要为整个高速缓存供电的方案变得越来越有意义。

Third Optimization: Pipelined Access and Multibanked
Caches to Increase Bandwidth
这些优化通过流水线化缓存访问或通过使用多个存储体扩展缓存以允许每个时钟进行多次访问来增加缓存带宽; 这些优化是超流水线和超标量方法的双重提高指令吞吐量。 这些优化主要针对 L1,其中访问带宽限制了指令吞吐量。 L2 和 L3 高速缓存中也使用多个存储体,但主要用作电源管理技术。
流水线 L1 允许更高的时钟周期,但会增加延迟。 例如,1990 年代中期 Intel Pentium 处理器指令缓存访问的流水线需要 1 个时钟周期; 对于 1990 年代中期到 2000 年的 Pentium Pro 到 Pentium III,需要 2 个时钟周期; 对于 2000 年推出的 Pentium 4 和当前的 Intel Core i7,它需要 4 个时钟周期。 流水线指令缓存有效地增加了流水线阶段的数量,导致对错误预测分支的更大惩罚。 相应地,流水线数据缓存会导致在发出加载和使用数据之间有更多的时钟周期(参见第 3 章)。 今天,所有的处理器都使用一些 L1 的流水线,只是为了分离访问和命中检测的简单情况,而且许多高速处理器都有三级或更多级的缓存流水线。
指令缓存比数据缓存更容易流水线化,因为处理器可以依靠高性能分支预测来限制延迟影响。 许多超标量处理器每个时钟可以发出和执行多个内存引用(允许加载或存储很常见,有些处理器允许多次加载)。 为了处理每个时钟的多个数据缓存访问,我们可以将缓存划分为独立的组,每个组支持独立的访问。 Bank 最初用于提高主内存的性能,现在用于现代 DRAM 芯片以及缓存。 英特尔酷睿 i7 在 L1 中有四个 bank(支持每个时钟最多 2 次内存访问)。
很明显,当访问自然地分布在各个 bank 中时,banking 效果最好,因此地址到 bank 的映射会影响内存系统的行为。 一种效果很好的简单映射是将块的地址按顺序分布在存储体之间,这称为顺序交织。 例如,如果有四个 bank,bank 0 包含地址模 4 为 0 的所有块,bank 1 包含地址模 4 为 1 的所有块,依此类推。 图 2.10 显示了这种交织。 多个存储体也是降低高速缓存和 DRAM 功耗的一种方式。
多个 bank 在 L2 或 L3 缓存中也很有用,但原因不同。 如果 L2 中有多个bank,如果bank不冲突,我们可以处理多个未完成的 L1 未命中。 这是支持非阻塞缓存的关键功能,我们的下一个优化。 Intel Core i7 中的 L2 有 8 个 bank,而 Arm Cortex 处理器使用了 1-4 个 bank 的 L2 缓存。 如前所述,多bank还可以降低能源消耗。
Fourth Optimization: Nonblocking Caches
to Increase Cache Bandwidth
对于允许乱序执行的流水线计算机(在第 3 章中讨论),处理器不需要因数据缓存未命中而停顿。例如,处理器可以在等待数据缓存返回丢失的数据的同时继续从指令缓存中获取指令。非阻塞高速缓存或无锁定高速缓存通过允许数据高速缓存在未命中期间继续提供高速缓存命中来提升这种方案的潜在优势。这种“未命中”优化通过在未命中期间提供帮助而不是忽略处理器的请求来减少有效的未命中惩罚。一个微妙而复杂的选择是,如果缓存可以重叠多次未命中,则缓存可能会进一步降低有效未命中惩罚:“多次未命中”或“未命中未命中”优化。只有当内存系统可以为多次未命中提供服务时,第二种选择才是有益的;大多数高性能处理器(例如 Intel Core 处理器)通常都支持两者,而许多低端处理器仅在 L2 中提供有限的非阻塞支持。
为了检验非阻塞缓存在减少缓存未命中惩罚方面的有效性,Farkas 和 Jouppi (1994) 做了一项研究,假设 8 KiB 缓存具有 14 周期未命中惩罚(适用于 1990 年代初期)。 他们观察到,当允许一次未命中时,SPECINT92 基准的有效未命中惩罚减少了 20%,而 SPECFP92 基准的有效未命中惩罚减少了 30%。
李等人。 (2011) 更新了这项研究,以使用多级缓存、关于未命中惩罚的更现代假设以及更大和更苛刻的 SPECCPU2006 基准测试。 该研究是在假设一个模型的基础上完成的运行 SPECCPU2006 基准测试的 Intel i7 单核(参见第 2.6 节)。图 2.11 显示了在未命中情况下允许 1、2 和 64 次命中时数据缓存访问延迟的减少; 标题描述了记忆系统的更多细节。 自早期研究以来,更大的缓存和增加的 L3 缓存降低了优势,SPECINT2006 基准显示缓存延迟平均减少约 9%,SPECFP2006 基准显示平均减少约 12.5%。


非阻塞缓存性能评估的真正困难在于缓存未命中不一定会使处理器停顿。 在这种情况下,很难判断任何单个未命中的影响并因此计算平均内存访问时间。 有效的未命中惩罚不是未命中的总和,而是处理器停顿的非重叠时间。 非阻塞高速缓存的好处是复杂的,因为它取决于多次未命中时的未命中惩罚、内存引用模式以及处理器在未完成未命中时可以执行的指令数。
通常,无序处理器能够隐藏 L1 数据缓存未命中的大部分未命中惩罚,但无法隐藏较低级别缓存未命中的很大一部分。 决定支持多少未完成的未命中取决于多种因素:
■ 未命中流中的时间和空间局部性,确定未命中是否可以启动对较低级别缓存或内存的新访问。
■ 响应内存或缓存的带宽。
■ 要在缓存的最低级别(其中未命中时间最长)允许更多未完成的未命中,需要在更高级别支持至少那么多未命中,因为未命中必须在最高级别的缓存中启动。
■ 内存系统的延迟。
以下简化示例说明了关键思想。

在 Li、Chen、Brockman 和 Jouppi 的研究中,他们发现 一次hit under miss 整数程序的 CPI 降低了约 7%,64 次约 12.7%。对于浮点程序, 一次hit under miss 降低了 12.7% ,64 次 一次hit under miss 为 17.8%。这些减少与图 2.11 中显示的数据缓存访问延迟的减少非常接近。
Implementing a Nonblocking Cache
尽管非阻塞缓存有提高性能的潜力,但它们的实现并不容易。 出现了两种初始类型的挑战:仲裁命中和未命中之间的争用,以及跟踪未命中的未命中,以便我们知道何时可以进行加载或存储。 考虑第一个问题。 在阻塞高速缓存中,未命中会导致处理器停顿,并且在处理未命中之前不会发生对高速缓存的进一步访问。 然而,在非阻塞缓存中,命中可能会与从内存层次结构的下一级返回的未命中相冲突。 如果我们允许多个未完成的未命中(几乎所有最近的处理器都这样做),则未命中甚至有可能发生冲突。 必须解决这些冲突,通常首先将命中优先于未命中,其次是对冲突未命中进行排序(如果它们可能发生)。
第二个问题出现是因为我们需要跟踪多个未完成的未命中。 在阻塞缓存中,我们总是知道返回的是哪个未命中,因为只有一个未命中。 在非阻塞缓存中,这很少是真的。 乍一看,您可能认为未命中总是按顺序返回,因此可以保留一个简单的队列,将返回的未命中与最长的未完成请求相匹配。 但是,请考虑发生在 L1 中的未命中。 它可能会在 L2 中产生命中或未命中; 如果 L2 也是非阻塞的,则未命中返回到 L1 的顺序不一定与它们最初发生的顺序相同。 具有非均匀缓存访问时间的多核和其他多处理器系统也引入了这种复杂性。
当一个未命中返回时,处理器必须知道是哪个加载或存储导致了未命中,以便指令现在可以继续执行;并且它必须知道数据应该放在缓存中的哪个位置(以及该块的标签设置)。在最近的处理器中,此信息保存在一组寄存器中,通常称为未命中状态处理寄存器 (MSHR)。如果我们允许 n 个未完成的未命中,则将有 n 个 MSHR,每个 MSHR 保存有关未命中在缓存中的位置和该未命中的任何标记位的值的信息,以及指示导致未命中的加载或存储的信息(在下一章中,您将看到这是如何跟踪的)。因此,当发生未命中时,我们分配一个 MSHR 来处理该未命中,输入有关未命中的适当信息,并用 MSHR 的索引标记内存请求。内存系统在返回数据时使用该标签,允许缓存系统将数据和标签信息传输到适当的缓存块,并“通知”产生未命中的加载或存储数据现在可用并且它可以恢复操作。非阻塞缓存显然需要额外的逻辑,因此有一定的能源成本。然而很难评估它们的能源成本正是因为它们可以减少停顿时间,从而减少执行时间和由此产生的能源消耗。
除了上述问题,多处理器内存系统,无论是在单个芯片内或在多个芯片上,还必须处理与内存一致性和一致性相关的复杂实现问题。 此外,由于缓存未命中不再是原子性的(因为请求和响应被拆分并且可能在多个请求之间交错),因此存在死锁的可能性。 对于感兴趣的读者,在线附录 I 中的第 I.7 节详细讨论了这些问题。
Fifth Optimization: Critical Word First and
Early Restart to Reduce Miss Penalty
该技术基于处理器通常一次只需要块的一个字的观察结果。 这种策略是不耐烦的:在发送请求的字并重新启动处理器之前,不要等待加载完整的块。 下面是两个具体的策略:
■ 关键词优先——首先从内存中请求遗漏的词,一到就发送给处理器; 让处理器继续执行,同时填充块中的其余字。
■ 提前重启——按正常顺序获取字,但是一旦块的请求字到达,就将其发送到处理器并让处理器继续执行。
通常,这些技术仅有益于具有大缓存块的设计,因为除非块很大,否则收益很低。 请注意,当块的其余部分正在被填充时,缓存通常会继续满足对其他块的访问。
然而,考虑到空间局部性,下一个引用很有可能是块的其余部分。 与非阻塞缓存一样,未命中惩罚并不容易计算。 当第一个关键词中有第二个请求时,有效的未命中惩罚是从引用到第二个片段到达的非重叠时间。 关键字优先和提前重启的好处取决于块的大小以及对尚未提取的块部分进行另一次访问的可能性。 例如,对于在 i7 6700 上运行的 SPECint2006,它首先使用早期重启和关键字,对具有未完成未命中的块进行了不止一个引用(平均 1.23 个引用,范围从 0.5 到 3.0)。 我们在第 2.6 节中更详细地探讨了 i7 内存层次结构的性能。
Sixth Optimization: Merging Write Buffer
to Reduce Miss Penalty
直写缓存依赖于写缓冲区,因为所有存储都必须发送到层次结构的下一个较低级别。 当一个块被替换时,即使是回写缓存也使用一个简单的缓冲区。 如果写缓冲区为空,则数据和完整地址写入缓冲区,从处理器的角度来看写入完成; 当写缓冲区准备将字写入内存时,处理器继续工作。 如果缓冲区包含其他修改的块,则可以检查地址以查看新数据的地址是否与有效写入缓冲区条目的地址匹配。 如果是,新数据将与该条目合并。 写入合并是此优化的名称。 英特尔酷睿 i7 等使用写入合并。
如果缓冲区已满并且没有地址匹配,则缓存(和处理器)必须等到缓冲区有一个空条目。 这种优化可以更有效地使用内存,因为多字写入通常比一次执行一个字写入更快。 Skadron 和 Clark (1997) 发现,即使合并的四项写入缓冲区也会产生停顿,从而导致 5%–10% 的性能损失。

由于写缓冲区已满,优化还减少了停顿。 图 2.12 显示了带有和不带有写合并的写缓冲区。 假设我们在写缓冲区中有四个条目,每个条目可以容纳四个 64 位字。 如果没有这种优化,连续地址的四个存储将在每个条目一个字的情况下填充缓冲区,即使合并时这四个字恰好适合写入缓冲区的单个条目。
请注意,输入/输出设备寄存器通常映射到物理地址空间。 这些 I/O 地址不能允许写入合并,因为单独的 I/O 寄存器可能不像内存中的字数组那样起作用。 例如,它们可能需要每个 I/O 寄存器一个地址和一个数据字,而不是使用单个地址进行多字写入。 这些副作用通常是通过将页面标记为需要缓存的非合并直写来实现的。
Seventh Optimization: Compiler Optimizations
to Reduce Miss Rate
到目前为止,我们的技术需要改变硬件。 下一项技术可在不更改任何硬件的情况下降低未命中率。
这种神奇的减少来自优化的软件——硬件设计师最喜欢的解决方案! 处理器和主内存之间日益增大的性能差距激发了编译器编写者仔细检查内存层次结构,以查看编译时优化是否可以提高性能。 再一次,研究分为指令未命中的改进和数据未命中的改进。 下面介绍的优化可以在许多现代编译器中找到。
Loop Interchange
一些程序具有嵌套循环,以非顺序访问内存中的数据。 简单地交换循环的嵌套可以使代码按照数据存储的顺序访问数据。 假设数组不适合缓存,该技术通过提高空间局部性来减少未命中; 重新排序可在缓存块中的数据被丢弃之前最大限度地利用它们。 例如,如果 x 是一个大小为 [5000,100] 的二维数组,因此 x[i,j] 和 x[i,j+1] 是相邻的(称为行主要的顺序,因为该数组的布局是 按行),那么下面的两段代码展示了如何优化访问:

原始代码会以 100 个字的步长跳过内存,而修订版在进入下一个块之前访问一个缓存块中的所有字。 这种优化提高了缓存性能,而不会影响执行的指令数量。
Blocking
这种优化改进了时间局部性以减少遗漏。 我们再次处理多个数组,一些数组按行访问,一些按列访问。 逐行(行主序)或逐列(列主序)存储数组不能解决问题,因为在每次循环迭代中都使用行和列。 这种正交访问意味着诸如循环交换之类的转换仍有很大的改进空间。

块算法不是对数组的整个行或列进行操作,而是对子矩阵或块进行操作。 目标是在替换数据之前最大限度地访问加载到缓存中的数据。 以下代码示例执行矩阵乘法,有助于激发优化:
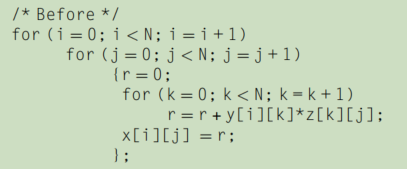
两个内部循环读取 z 的所有 N×N 个元素,重复读取 y 行中相同的 N 个元素,并写入 x 的一行 N 个元素。 图 2.13 给出了对三个数组的访问的快照。 深色表示最近访问,浅色表示较旧访问,白色表示尚未访问。
容量未命中的数量显然取决于 N 和缓存的大小。 如果它可以保存所有三个 N×N 矩阵,那么一切都很好,前提是没有缓存冲突。 如果缓存可以保存一个 N×N 矩阵和一行 N,那么至少第 i 行 y 和数组 z 可以保留在缓存中。 小于该值并且 x 和 z 都可能发生未命中。 在最坏的情况下,N3 个操作将访问 2N3+N2 个内存字。
为了确保被访问的元素可以放入缓存中,原始代码更改为在大小为 B 乘 B 的子矩阵上进行计算。两个内部循环现在以大小为 B 的步长计算,而不是 x 和 z 的全长。 B 称为阻塞因子。 (假设 x 初始化为零。)

图 2.14 说明了使用阻塞对三个数组的访问。 仅查看容量未命中,访问的内存字总数为 2N3/B+N2。 这个总数是 B 的近似因子的改进。因此,阻塞利用空间和时间局部性的组合,因为 y 受益于空间局部性,而 z 受益于时间局部性。 尽管我们的示例使用了正方形块 (BxB),但我们也可以使用矩形块,如果矩阵不是正方形,这将是必要的。
尽管我们的目标是减少缓存未命中,但也可以使用阻塞来帮助寄存器分配。 通过采用较小的块大小以便块可以保存在寄存器中,我们可以最大限度地减少程序中的加载和存储次数。
正如我们将在第 4 章的 4.8 节中看到的,缓存阻塞对于从运行使用矩阵作为主要数据结构的应用程序的基于缓存的处理器获得良好性能是绝对必要的。
Eighth Optimization: Hardware Prefetching of Instructions and Data to Reduce Miss Penalty or Miss Rate
非阻塞缓存通过与内存访问重叠执行来有效地减少未命中惩罚。 另一种方法是在处理器请求项目之前预取项目。 指令和数据都可以预取,可以直接预取到缓存中,也可以预取到比主存储器访问速度更快的外部缓冲区中。
指令预取经常在高速缓存之外的硬件中完成。 通常,处理器在未命中时获取两个块:请求的块和下一个连续的块。 请求的块在返回时放入指令缓存,预取的块放入指令流缓冲区。 如果请求的块存在于指令流缓冲区中,则取消原始缓存请求,从流缓冲区中读取该块,并发出下一个预取请求。
类似的方法可以应用于数据访问(Jouppi,1990)。 Palacharla 和 Kessler (1994) 研究了一组科学程序,并考虑了可以处理指令或数据的多个流缓冲区。 他们发现,8 个流缓冲区可以捕获来自具有两个 64 KiB 四路组关联缓存(一个用于指令,另一个用于数据)的处理器的所有未命中的 50%–70%。
英特尔酷睿 i7 支持硬件预取到 L1 和 L2,最常见的预取情况是访问下一行。 一些早期的英特尔处理器使用了更激进的硬件预取,但这导致某些应用程序的性能降低,导致一些老练的用户关闭该功能。

图 2.15 显示了打开硬件预取时 SPEC2000 程序子集的整体性能改进。 请注意,该图仅包括 12 个整数程序中的 2 个,而它包括大多数 SPECCPU 浮点程序。 我们将在 2.6 节中返回对 i7 上预取的评估。
预取依赖于利用原本不会被使用的内存带宽,但如果它干扰了需求未命中,它实际上会降低性能。 编译器的帮助可以减少无用的预取。 当预取运行良好时,它对功耗的影响可以忽略不计。 当不使用预取数据或替换有用数据时,预取将对功耗产生非常负面的影响。
Ninth Optimization: Compiler-Controlled Prefetching to Reduce Miss Penalty or Miss Rate
硬件预取的替代方法是编译器插入预取指令以在处理器需要数据之前请求数据。 预取有两种风格:
■ 寄存器预取将值加载到寄存器中。
■ 缓存预取仅将数据加载到缓存而不是寄存器。
这些中的任何一个都可以是有故障的或无故障的; 也就是说,该地址是否会导致虚拟地址故障和保护违规的异常。 使用这个术语,正常的加载指令可以被认为是“有故障的寄存器预取指令”。 如果无故障预取通常会导致异常,则它们只会变成无操作,这就是我们想要的。
最有效的预取对程序来说是“语义上不可见的”:它不会改变寄存器和内存的内容,也不会导致虚拟内存故障。 今天的大多数处理器都提供无故障的缓存预取。 本节假设无故障缓存预取,也称为非绑定预取。
只有当处理器可以在预取数据时继续进行时,预取才有意义; 也就是说,在等待预取数据返回的同时,高速缓存不会停顿而是继续提供指令和数据。 如您所料,此类计算机的数据缓存通常是非阻塞的。
与硬件控制的预取一样,目标是将执行与数据的预取重叠。 循环是重要的目标,因为它们有助于预取优化。 如果未命中惩罚很小,编译器只会展开循环一两次,并在执行时安排预取。 如果惩罚很大,它使用软件流水线(见附录 H)或多次展开以预取数据以备将来迭代。
然而,发出预取指令会产生指令开销,因此编译器必须注意确保此类开销不会超过收益。 通过专注于可能是缓存未命中的引用,程序可以避免不必要的预取,同时显着提高平均内存访问时间。



尽管数组优化很容易理解,但现代程序更可能使用指针。 Luk 和 Mowry (1999) 已经证明基于编译器的预取有时也可以扩展到指针。 在具有递归数据结构的 10 个程序中,在访问节点时预取所有指针将一半程序的性能提高了 4%–31%。 另一方面,其余程序的性能仍处于原始性能的 2% 以内。 问题在于预取是否针对缓存中已有的数据,以及它们是否发生得足够早以便数据在需要时到达。
许多处理器支持缓存预取指令,以及高端处理器(例如 Intel Core i7) 也经常在硬件中做某种类型的自动预取。
Tenth Optimization: Using HBM to Extend the Memory Hierarchy
由于服务器中的大多数通用处理器可能需要比 HBM 封装更多的内存,因此有人提议使用封装内 DRAM 来构建大规模的 L4 缓存,即将推出的技术范围从 128 MiB 到 1 GiB 甚至更多, 远远超过当前的片上 L3 缓存。 使用如此大的基于 DRAM 的缓存会引发一个问题:标签位于何处? 这取决于标签的数量。 假设我们要使用 64B 的块大小; 那么 1 GiB 的 L4 缓存需要 96 MiB 的标签——比 CPU 上的缓存中存在的静态内存多得多。 将块大小增加到 4 KiB,会显着减少 256 K 条目的标签存储或少于 1 MiB 的总存储,这可能是可以接受的,因为下一代多核处理器中的 L3 缓存为 4-16 MiB 或更多。 然而,如此大的块大小有两个主要问题。
第一,当不需要很多块的内容时,缓存的使用效率可能会很低; 这就是所谓的碎片问题,它也发生在虚拟内存系统中。 此外,如果大量数据未使用,则传输如此大的块效率低下。 其次,由于块大小很大,DRAM 缓存中保存的不同块的数量要少得多,这会导致更多的未命中,尤其是冲突和一致性未命中。
第一个问题的一个部分解决方案是添加子锁定。 子块化允许块的部分无效,要求它们在未命中时被提取。 然而,子阻塞对解决第二个问题没有任何作用。
标签存储是使用较小块大小的主要缺点。该困难的一种可能解决方案是将 L4 的标签存储在 HBM 中。乍一看,这似乎行不通,因为每次 L4 访问都需要对 DRAM 进行两次访问:一次用于标签,另一次用于数据本身。由于随机 DRAM 访问的访问时间很长,通常为 100 个或更多处理器时钟周期,因此这种方法已被废弃。 Loh 和 Hill (2011) 针对这个问题提出了一个巧妙的解决方案:将标签和数据放在 HBM SDRAM 的同一行中。尽管打开行(并最终关闭它)需要大量时间,但访问行不同部分的 CAS 延迟大约是新行的三分之一访问时间。因此,我们可以先访问块的标签部分,如果是命中,则使用列访问来选择正确的单词。 Loh 和 Hill (L-H) 提议组织 L4 HBM 缓存,以便每个 SDRAM 行由一组标签(在块的头部)和 29 个数据段组成,形成一个 29 路组关联缓存。当访问 L4 时,打开相应的行并读取标签;命中需要多列访问权限才能获取匹配数据。

Qureshi 和 Loh (2012) 提出了一种称为合金缓存的改进,可以减少命中时间。 合金缓存将标签和数据组合在一起,并使用直接映射缓存结构。 这允许通过直接索引 HBM 缓存并对标签和数据进行突发传输,将 L4 访问时间减少到单个 HBM 周期。 图 2.16 显示了合金缓存、L-H 方案和基于 SRAM 的标签的命中延迟。 与 L-H 方案相比,合金缓存将命中时间减少了 2 倍以上,作为回报,未命中率增加了 1.1-1.2 倍。 标题中解释了基准的选择。
不幸的是,在这两种方案中,未命中都需要两次完整的 DRAM 访问:一次获取初始标签,另一次访问主存储器(甚至更慢)。 如果我们可以加快漏检,就可以减少漏检时间。 已经提出了两种不同的解决方案来解决这个问题:一种使用映射来跟踪缓存中的块(不是块的位置,只是它是否存在); 另一个使用内存访问预测器,该预测器使用历史预测技术来预测可能的未命中,类似于用于全局分支预测的技术(参见下一章)。 看起来,一个小的预测器可以高精度地预测可能的失误,从而导致总体上较低的失误惩罚。

图 2.17 显示了图 2.16 中使用的内存密集型基准测试在 SPECrate 上获得的加速比。 合金缓存方法优于 LH 方案甚至不切实际的 SRAM 标签,因为未命中预测器的快速访问时间和良好的预测结果相结合,可以缩短预测未命中的时间,从而降低未命中惩罚。 合金缓存的性能接近于理想情况,具有完美的未命中预测和最短命中时间的 L4。
HBM 可能广泛用于各种不同的配置,从包含用于某些高性能、专用系统的整个内存系统到用作大型服务器配置的 L4 缓存。
Cache Optimization Summary

改善命中时间、带宽、未命中惩罚和未命中率的技术通常会影响平均存储器访问方程的其他组件以及存储器层次结构的复杂性。 图 2.18 总结了这些技术并估计了对复杂性的影响,+ 表示该技术改进了该因素,- 表示它损害了该因素,空白表示它没有影响。 一般来说,没有一种技术可以帮助超过一个类别。















 650
650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









