







大部分的计算机问题是确定性问题,还记得在洛克《人类理解论》里讨论英汉互译的不确定性问题,提到了计算机语言的通用可能性,在于确定性。但对于机器学习的若干问题,我们常常要使用概率,比如蚁群,遗传等全局优化,再比如用随机梯度下降来提高效率。
总结一下,机器学习对概率的依赖来源于三点原因:
1. 系统固有的随机性。在量子力学的世界里,一切的粒子都是波,粒子一切的运动都是不确定的,类似这样的模型。
2. 系统的一些变量不完全可观测,参考montyHall问题。
3. 信息丢失导致的不确定性。ok,这是我们常遇到的。
很多问题不是靠复杂而精确地模型解决的。比如说,语言学家总结了几千年来语言的结构、语法变迁及口语使用习惯来试图解决NLP的一些问题,但是仍然没有最最简单的词袋(Bag of words)模型可靠。
All models are wrong, but some are useful, 想想看还真是
熵
最基本的
I(x)=−logP(x)
自信息 self-information将一件事的可能性量化,由此想到用概率分布表示熵,表示为
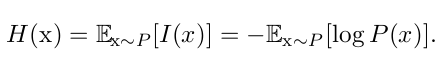
假设我们有两个独立的概率分布P(x)和Q(x),现在要想办法计算两个分布的差异。这个差异叫做KL divergence,相对熵。其物理意义是:符合概率分布P的事件用概率分布Q来编码,平均每个单位得编码长度增加了多少。
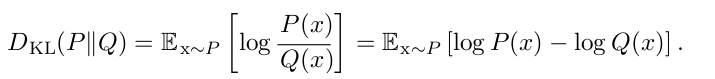
对吧,当P,Q相同时,二者的信息熵相同,所以相对熵为零,编码长度不变。这里补充一下,在信息论里常用2为对数的底,在机器学习里习惯用nats-e做底。
- 这里回想起逻辑回归的cost function常用cross entropy表示,事实上KL距离和cross entropy十分相似,我们在优化时实际上是在最小化假设分布和标签分布的KL距离
crossentropy:H(P,Q)=H(P)+D(P||Q)















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









