







最近课程要求实现手写识别任务,于是就学习了网络上和已有的相关程序,编写了一份Tensorfliow的手写识别程序,准确率超过98%。之前也写过一份Pytorch版本的代码,有需要的同学也可以自取~。希望可以和大家多多交流~
Pytorch 实现手写识别源码见:https://blog.csdn.net/qq_33302004/article/details/106339687
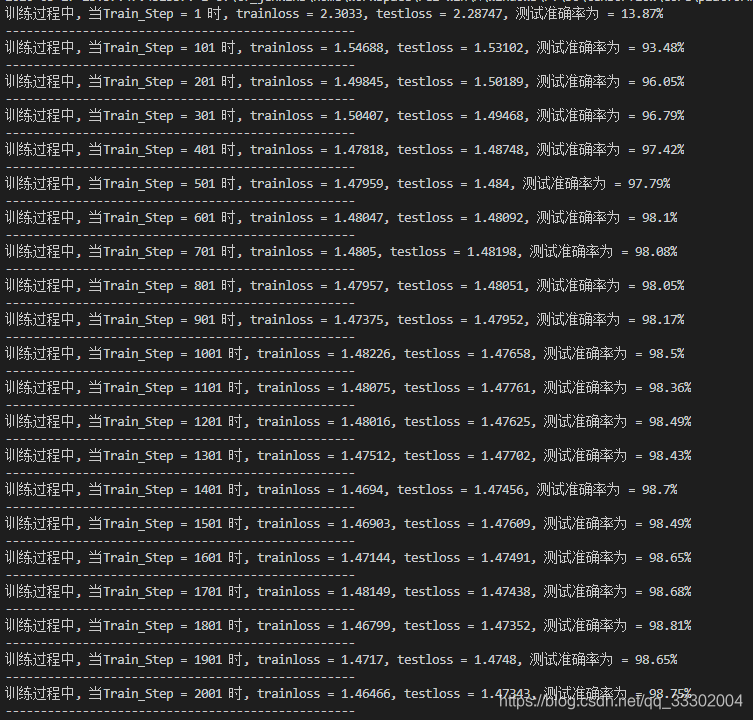
运行结果:
程序讲解:
程序主要使用了三个函数:
print_activations(用于展示每一特征图尺寸)
inference(搭建网络结构)
do_train(完成网络训练)
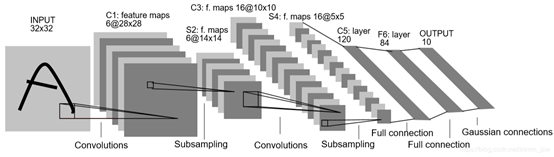
网络仿照LeNet5搭建,稍作改动:
(1)INPUT(输入层):输入图片:28∗28
(2) C1(卷积层):卷积核:5*5*32、输出特征图:24*24*32
(3)S2(池化层):输出:12*12*32
(4)C3(卷积层):卷积核:5*5*64、输出特征图:8*8*64
(5)S4(池化层):输出:4*4*64
(6)C5(卷积层):卷积核 4*4*256、输出特征图 1*1*256(256维的向量)
(7) F6(全连接层):256 —> 128
(8)Output(输出层):128 —> 10
LeNet5网络结构如下所示:
使用DropOut(见inference函数):

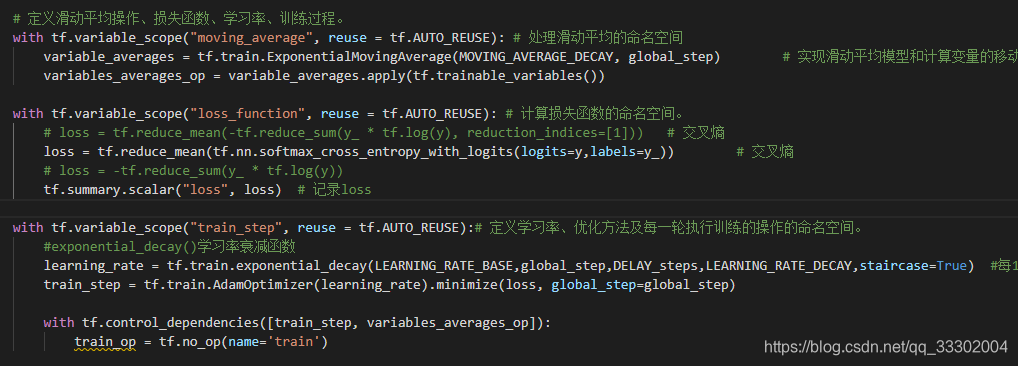
滑动平移、学习率衰减、损失函数(见do_train函数):
程序源码:
# from sklearn.datasets import fetch_mldata
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt
import numpy as np
from math import floor, ceil
# 超参数 这组参数也超过98%
MNIST_data_path = 'MNIST/' # 数据路劲
REGULARIZATION_RATE = 0.000001 # 正则化系数
MOVING_AVERAGE_DECAY = 0.999 # 滑动平均
DROPOUT_RATE= 0.50 # dropout系数
LEARNING_RATE_BASE = 0.0015 # 初始学习率
LEARNING_RATE_DECAY = 0.95 # 学习率衰减系数
DELAY_steps = 1000
BATCH_SIZE = 400 # 批T处理数量
TRAINING_STEPS = 2000 # 迭代次数
def print_activations(t):##展示每一层卷积层 或池化层输出tensor的尺寸
print(t.op.name,'',t.get_shape().as_list())##输出名字和尺寸
return
# 构建模型,train控制是否dropout
def inference(x, dropout_rate, regularizer):
print_activations(x)
# 第一层卷积:输入1通道,输出6通道,卷积核5*5
with tf.variable_scope('layer1-conv1', reuse = tf.AUTO_REUSE):
conv1_weights = tf.get_variable(
"weight", [5, 5, 1, 32],
initializer=tf.truncated_normal_initializer(stddev=0.1)) # 生成随机值,服从标准偏差为0.1 initializer=tf.truncated_normal_initializer(stddev=0.1)
conv1_biases = tf.get_variable("bias", [32], initializer=tf.constant_initializer(0.0)) # 偏差,初始化为常数0
conv1_wx = tf.nn.conv2d(x, conv1_weights, strides=[1, 1, 1, 1], padding='VALID') # 进行卷积操作,strides 卷积时在图像每一维的步长,不考虑边界
conv1 = tf.nn.relu(tf.nn.bias_add(conv1_wx, conv1_biases)) # 卷积的结果加上偏差(矩阵+向量的操作),再进行ReLu
print_activations(conv1)
conv1=tf.nn.max_pool(conv1, ksize=[1,2,2,1], strides=[1,2,2,1], padding='VALID', name='max_pooling') # 进行最大池化操作
print_activations(conv1)
# 第二层卷积:输入6通道,输出16通道,卷积核5*5
with tf.variable_scope("layer2-conv2", reuse = tf.AUTO_REUSE):
conv2_weights = tf.get_variable(
"weight", [5, 5, 32, 64],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable("bias", [64], initializer=tf.constant_initializer(0.0))
conv2_wx = tf.nn.conv2d(conv1, conv2_weights, strides=[1, 1, 1, 1], padding='VALID')
conv2 = tf.nn.relu(tf.nn.bias_add(conv2_wx, conv2_biases))
print_activations(conv2)
conv2=tf.nn.max_pool(conv2, ksize=[1,2,2,1], strides=[1,2,2,1], padding='VALID',name='max_pooling')
print_activations(conv2)
reshaped = tf.reshape(conv2, [-1, 64*4*4]) # 转化成为向量
# 全连接层1:16*4*4 ——> 120
with tf.variable_scope('layer-fc1', reuse = tf.AUTO_REUSE):
fc1_weights = tf.get_variable("weight", [64*4*4, 256],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc1_weights)) # 正则化
fc1_biases = tf.get_variable("bias", [256], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
fc1 = tf.nn.dropout(fc1, dropout_rate) # dropout
print_activations(fc1)
# 全连接层2:120 ——> 84
with tf.variable_scope('layer-fc2', reuse=tf.AUTO_REUSE):
fc2_weights = tf.get_variable("weight", [256, 128],
initializer=tf.truncated_normal_initializer(stddev=0.1))
if regularizer != None: tf.add_to_collection('losses', regularizer(fc2_weights))
fc2_biases = tf.get_variable("bias", [128], initializer=tf.constant_initializer(0.1))
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_weights) + fc2_biases)
fc2 = tf.nn.dropout(fc2, dropout_rate)
print_activations(fc2)
# 全连接层3:84 ——> 10
with tf.variable_scope('layer-fc3', reuse=tf.AUTO_REUSE):
fc3_weights = tf.get_variable("weight", [128, 10],
initializer=tf.truncated_normal_initializer(stddev=0.1))
# if regularizer != None: tf.add_to_collection('losses', regularizer(fc3_weights))
fc3_biases = tf.get_variable("bias", [10], initializer=tf.constant_initializer(0.1))
# fc3 = tf.nn.relu(tf.matmul(fc2, fc3_weights) + fc3_biases)
fc3 = tf.nn.softmax(tf.matmul(fc2, fc3_weights) + fc3_biases)
print_activations(fc3)
return fc3
# 训练网络模型
def do_train(train_x, train_y, test_x, test_y):
tf.reset_default_graph() # 清除默认图形堆栈并重置全局默认图形
test_y_labelNumber = np.argmax(test_y, axis=1) # 获取label的数值
NUM_TEST = len(test_y)
NUM_TRAIN = len(train_y)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 28, 28, 1], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')
# tf.placeholder()函数是在神经网络构建graph的时候在模型中的占位,此时并没有把要输入的数据传入模型,
# 它只会分配必要的内存。等建立session后,运行模型时通过feed_dict()函数向占位符喂入数据。
# regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = inference(x, dropout_rate=DROPOUT_RATE, regularizer = None) # dropout策略及正则化策略防止过拟合, y_是经过网络前向传播后的预测输出值
global_step = tf.Variable(0, trainable=False)
# 定义滑动平均操作、损失函数、学习率、训练过程。
with tf.variable_scope("moving_average", reuse = tf.AUTO_REUSE): # 处理滑动平均的命名空间
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step) # 实现滑动平均模型和计算变量的移动平均值。
variables_averages_op = variable_averages.apply(tf.trainable_variables())
with tf.variable_scope("loss_function", reuse = tf.AUTO_REUSE): # 计算损失函数的命名空间。
# loss = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1])) # 交叉熵
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y,labels=y_)) # 交叉熵
# loss = -tf.reduce_sum(y_ * tf.log(y))
tf.summary.scalar("loss", loss) # 记录loss
with tf.variable_scope("train_step", reuse = tf.AUTO_REUSE):# 定义学习率、优化方法及每一轮执行训练的操作的命名空间。
#exponential_decay()学习率衰减函数
learning_rate = tf.train.exponential_decay(LEARNING_RATE_BASE,global_step,DELAY_steps,LEARNING_RATE_DECAY,staircase=True) #每1000(DELAY_steps)轮训练后要乘以学习率的衰减值 #train.num_examples / BATCH_SIZE,
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
config = tf.ConfigProto()
config.gpu_options.allow_growth = True #允许显存增长
config.gpu_options.per_process_gpu_memory_fraction = 0.9 #不完全分配所有的GPU内存,设为90%
log_device_placement=True
with tf.Session(config = config) as sess:
tf.global_variables_initializer().run() #sess.run(tf.global_variables_initializer()) 初始化变量
for i in range(TRAINING_STEPS + 1):
# 随机取100训练数据
index_batch = np.random.randint(NUM_TRAIN, size=BATCH_SIZE)
xs,ys = train_x[index_batch], train_y[index_batch]##训练集
re_xs = np.reshape(xs, [-1, 28, 28, 1])
re_ys = np.reshape(ys, [-1, 10])
# 训练集 喂数据
train_feed={x: re_xs, y_: re_ys}
# 执行训练
_, loss_value, step = sess.run([train_step, loss, global_step], feed_dict=train_feed)
if i % (100) == 0:
# 测试集测试
# index_batch = np.random.randint(NUM_TEST, size=BATCH_SIZE)
# xs_, ys_ = test_x[index_batch], test_y[index_batch]
xs_, ys_ = test_x, test_y
re_xs_ = np.reshape(xs_, [-1, 28, 28, 1])
re_ys_ = np.reshape(ys_, [-1, 10])
# 测试集 喂数据
test_feed = {x: re_xs_, y_: re_ys_}
loss_value_, y_pre = sess.run([loss, y], feed_dict=test_feed)
y_pre_labelNumber = np.argmax(y_pre, axis=1)
correct = 0
for j in range(0, NUM_TEST):
if y_pre_labelNumber[j] == test_y_labelNumber[j]:
correct += 1
print("训练过程中, 当Train_Step = %d 时, trainloss = %g, testloss = %g, 测试准确率为 = %g%%" % (step, loss_value, loss_value_, float(correct)*100/NUM_TEST))
print("-" * 50)
return
if __name__ == '__main__':
mnist = input_data.read_data_sets(MNIST_data_path,one_hot=True) # 导入数据集
train_x, train_y, test_x, test_y = mnist.train.images, mnist.train.labels, mnist.test.images, mnist.test.labels # 读取数据
do_train(train_x, train_y, test_x, test_y)














 1136
1136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









