







 本文介绍了Q Learning的基本概念,强调它是一个离线学习过程,涉及到的状态、动作和Q表更新策略。详细解释了Q表如何根据当前状态、动作、环境反馈和未来奖励的衰减进行更新,并给出了Q Learning的伪代码和一个简单的1维探索者例子的代码实现。
本文介绍了Q Learning的基本概念,强调它是一个离线学习过程,涉及到的状态、动作和Q表更新策略。详细解释了Q表如何根据当前状态、动作、环境反馈和未来奖励的衰减进行更新,并给出了Q Learning的伪代码和一个简单的1维探索者例子的代码实现。
学习过程来自莫烦大神的视频:
https://www.bilibili.com/video/BV13W411Y75P?p=5
Q Learning概念、更新、代码实现
1. 什么是Q Learning?
- Q Learning 是一种决策过程
- Q Learning 是一个offline学习过程
- 存在以下的概念:
- 当前智能体的状态:S(state)
- 动作行为:A(action)
- 行为价值表:Q表(Q表存储了每一个状态下,每一个动作A的价值),如下:
| a1 | a2 | |
|---|---|---|
| s1 | 0 | 1 |
| s2 | -1 | -2 |
| … | … | … |
| sn | 0.567 | 0.433 |
这样我们就可以通过训练,不断更新Q表中每个状态下每个动作的取值,在决策时按图索骥,根据当前状态选择价值最高的动作(maxQ)。
2. Q表是如何更新的?

- 先看图中左下角的Q表,假设我们当前在状态s1,动作a1和a2的价值可以用Q(s1, a1)和Q(s1, a2)表示,由图中可知Q(s1, a2)更大,所以选择动作a2,进入状态s2。
- 我们进入状态s2后,会得到环境的反馈R,我们可以根据R以及当前Q表的值,计算出状态s2的现实价值,也就是图中的 Q(s1, a2)现实=R + γ*maxQ(s2),其中gamma是一个系数(未来奖励的衰减值),maxQ(s2)是状态s2下最大的价值取值(图中可知为2)。我们这个式子叫做Q现实。
- 我们进入状态s2的原因是从当前状态估计,选择动作a2的价值最大,我们把Q(s1, a2)叫做Q估计。
- 我们选择了动作a2,得到了环境的反馈R,就要更新Q表,更新依据是现实和估计的差距,也就是图中的 新Q(s1, a2) = 老Q(s1, a2) + α*差距 ,其中alpha是系数(学习效率)。
- 关于γ(未来奖励的衰减值)的取值可以参考线面这幅图,图中是将状态s不断用后面的状态表示。

3. Q Learning伪代码
随机初始化Q(s, a)表格;
Repeat (for each episode):
初始化状态s;
Repeat (for each step of episode):
依据某种策略,从Q表中根据当前状态s,选择一个动作a;
执行动作a,进入状态s',获得环境反馈r;
// 【根据"Q现实"和"Q估计"更新Q(s, a)】
Q(s, a) = Q(s, a) + α * [r + γ * maxQ(s') - Q(s, a)];
// Q(s, a) = (1 - α) * Q(s, a) + α * [r + γ * maxQ(s')];
将当前状态更新为s';
until s is terminal
4. Q Learning简单实现:1维探索者例子
效果如下:
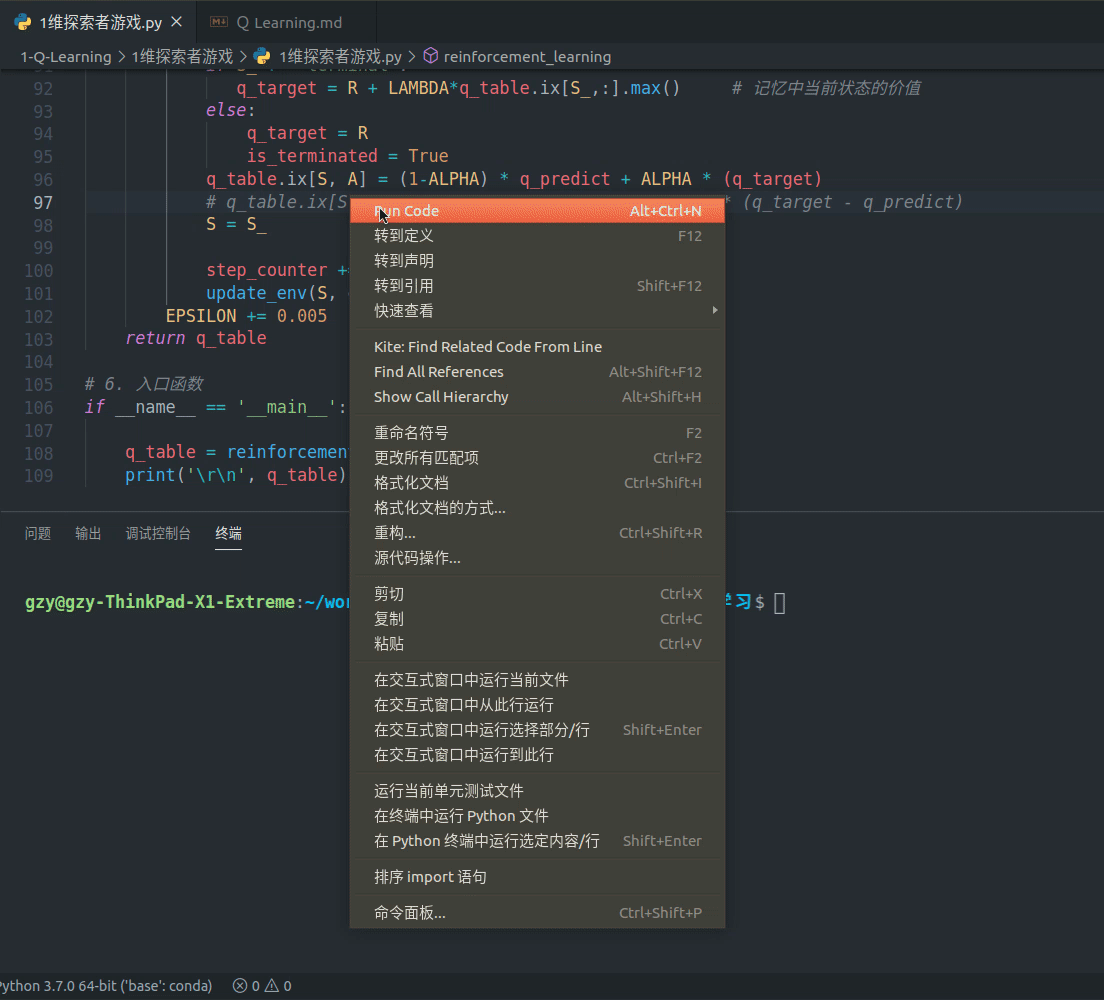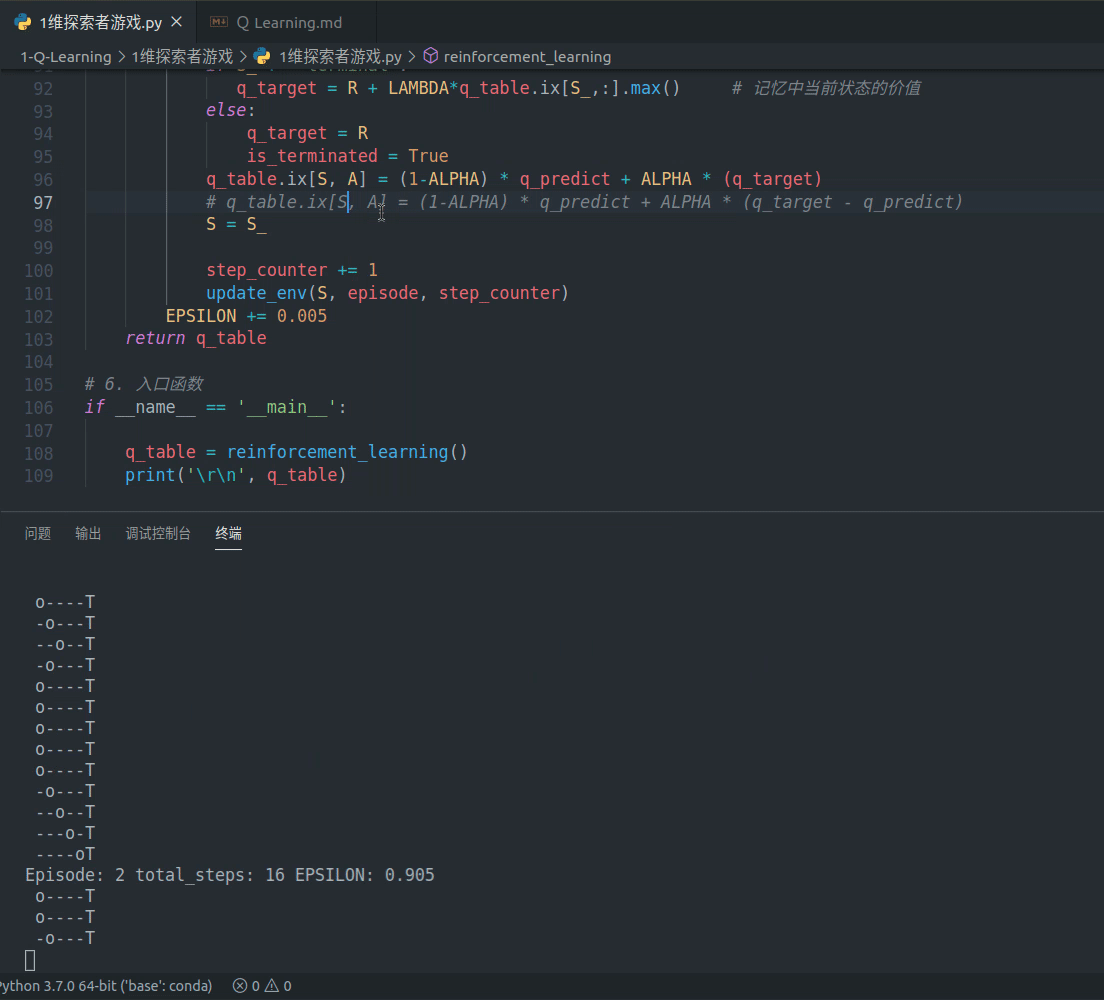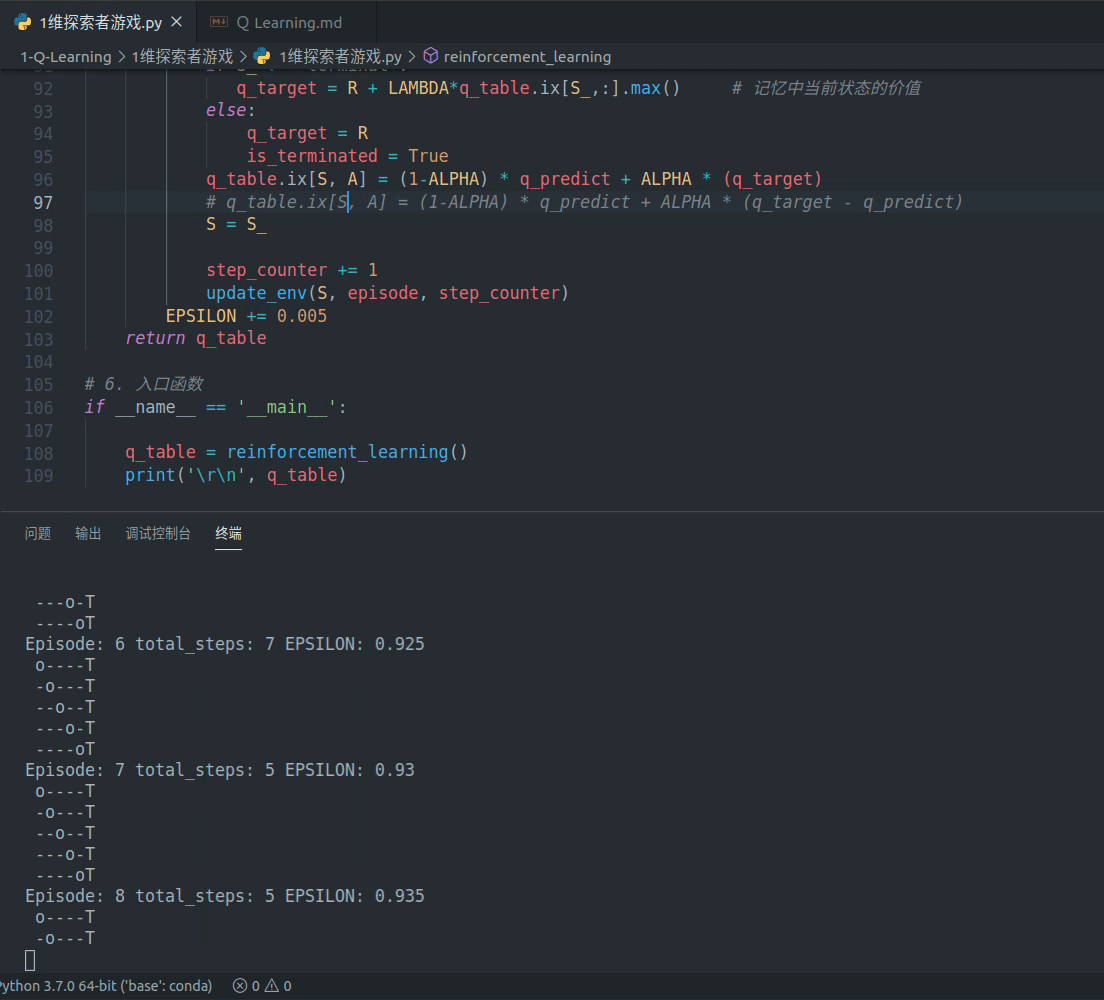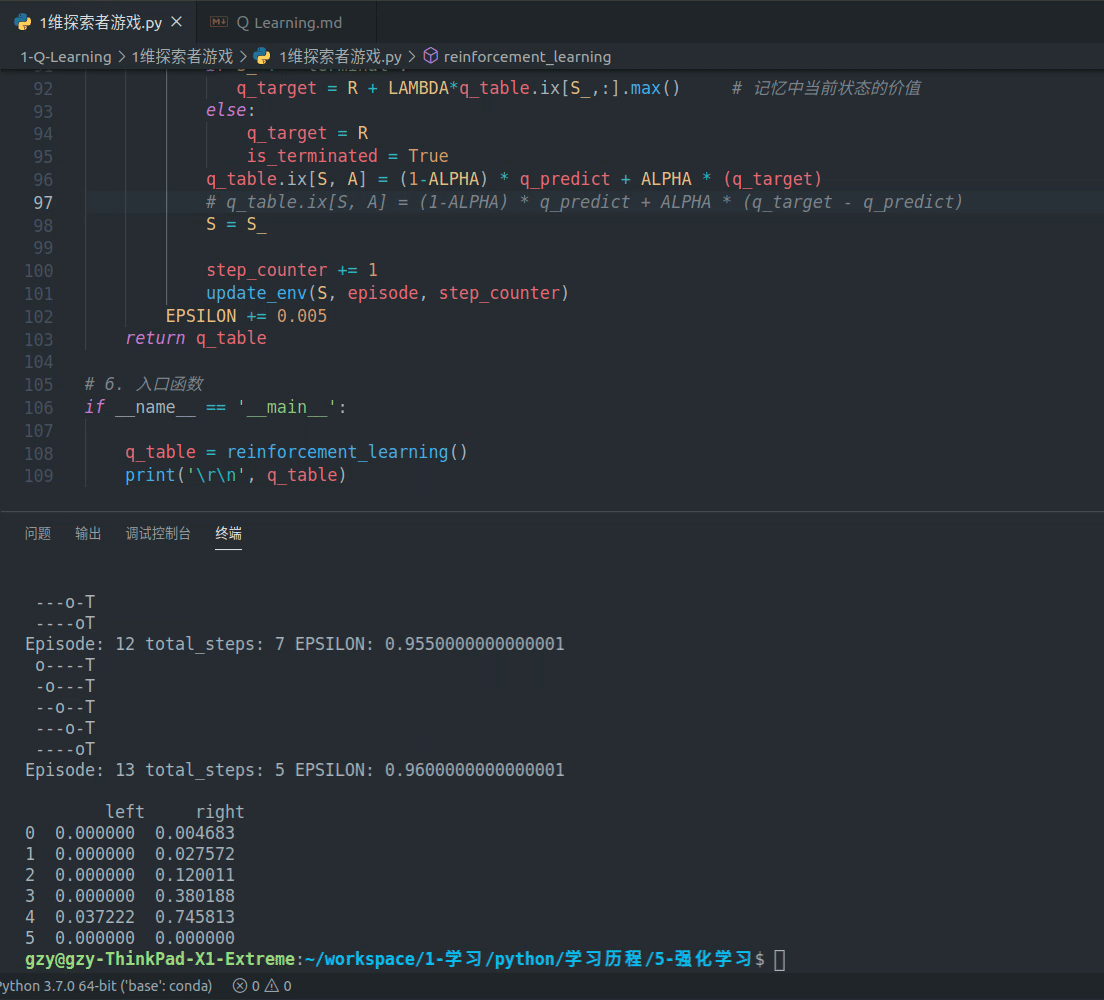
代码如下:
# Q-learning 寻找宝藏
import numpy as np
import pandas as pd
import time
# 随机数种子,使得每次生成的随机数相同
# 设置随机数种子可以使每一次生成随机数据的时候结果相同,不设置随机数种子结果造成每一次生成数据都不相同。
# np.random.seed(2) # reproducible(可重复的)
# global variables 全局变量
N_STATES = 6 # 状态的数量,线性世界的长度
ACTIONS = ['left', 'right'] # available actions
EPSILON = 0.9 # greedy policy,90%的时候选择最优动作,10%的时候选择随机动作
ALPHA = 0.1 # learning rate
LAMBDA = 0.9 # discount factor,(记忆中利益的衰减值),未来奖励的衰减值
MAX_EPISODES = 13 # maximum episodes, 只训练13个回合
FRESH_TIME = 0.1 # fresh time for one move
# 1. 初始化建立 Q-table
def build_q_table(n_states, actions):
table = pd.DataFrame(
np.zeros((n_states, len(actions))), # q_table initial values
columns=actions, # action's name
)
# print(table)
return table
# 2. 选择动作
def choose_action(state, q_table):
# this is how to choose an action
state_actions = q_table.iloc[state, :]
# np.random.uniform 从一个均匀分布中随机采样,默认是0~1,可以指定np.random.uniform(low, high)
if(np.random.uniform() > EPSILON or state_actions[0] == state_actions[1]):
action_name = np.random.choice(ACTIONS)
else:
action_name = state_actions.idxmax() # idxmax 替换 argmax (idx可以理解为index)
# FutureWarning: 'argmax' is deprecated, use 'idxmax' instead. The behavior of 'argmax'
# will be corrected to return the positional maximum in the future.
return action_name
# 3. 状态转换和回报函数
def get_env_feedback(S, A):
# This is how agent will interact with the environment
if A == 'right':
if S == N_STATES - 2:
S = 'terminal'
R = 1
else:
S = S + 1
R = 0
else:
R = 0
if S == 0:
S = S
else:
S = S - 1
return S, R
# 4. 环境可视化
def update_env(S, episode, step_counter):
# This is how environment be updated
env_list = ['-']*(N_STATES - 1) + ['T']
if S == 'terminal':
interaction = '\rEpisode: ' + str(episode+1) + ' total_steps: ' + str(step_counter) + ' EPSILON: ' + str(EPSILON)
print(interaction)
else:
env_list[int(S)] = 'o'
interaction = ''.join(env_list)
print('\r',interaction)
time.sleep(FRESH_TIME)
# 5. 创建主循环
def reinforcement_learning():
# The main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS)
# 为了能在函数内部修改全局变量 所以要先用global关键词声明
global EPSILON
for episode in range(MAX_EPISODES):
step_counter = 0
S = 0 # now state 初始位置
is_terminated = False
update_env(S, episode, step_counter) # init environment
while not is_terminated:
A = choose_action(S, q_table)
S_, R = get_env_feedback(S, A)
q_predict = q_table.ix[S, A] # Q估计
if S_ != 'terminal':
q_target = R + LAMBDA*q_table.ix[S_,:].max() # Q现实
else:
q_target = R
is_terminated = True
q_table.ix[S, A] = (1-ALPHA) * q_predict + ALPHA * (q_target)
S = S_
step_counter += 1
update_env(S, episode, step_counter) # 更新环境
EPSILON += 0.005
return q_table
# 6. 入口函数
if __name__ == '__main__':
q_table = reinforcement_learning()
print('\r\n', q_table)

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









