







基于图像的视觉伺服的理论部分可以参考该部分
------基于图像的视觉伺服,其误差信号直接用图像特征来定义图象平面坐标(非任务空间坐标)的函数。其基本原理是由该误差信号计算出控制量,并将其变换到机器人运动空间中去,从而驱动机械手向目标运动,完成伺服任务。对于抓取静止目标的任务,该误差仅是机械手图像特征的函数;对于运动目标,误差还是运动目标图像特征的函数。该方法无需估计目标在笛卡儿坐标系中的位姿,减少了计算时延,并可克服摄像机标定误差及关节位置传感器误差对定位精度的影响。然而,为了将图像特征参数的变化同机器人位姿变化联系起来,该方法必须计算图像雅可比矩阵(Image Jacobian Matrix)及其逆矩阵。基于图像的视觉伺服本质上是把伺服任务放在图像特征参数空间中进行描述和控制。
------基于图像的视觉伺服系统的定位精度对摄像机标定误差不敏感。与基于位置的视觉伺服相比, 具有较少的计算量。 文献通过仿真与实验表明, 对于 eye in hand 构型的机器人视觉伺服系统,在存在图像量化误差、摄像机标定误差和图像噪声的情况下,基于图像的伺服方式比基于位置的伺服方式有更好的定位与跟踪效果。
------传统的基于图像的视觉飼服方式使用一系列特征点作为图像控制特征来定义
s
s
s。对图像的测量
m
(
t
)
m(t)
m(t)通常是对应特征点对在图像上的像素距离,而系统参数
a
a
a为摄像机的内参数。基于这祥的设定,可定义在摄像机坐标系下的空间点
X
=
{
X
,
Y
,
Z
}
\mathbf{X}=\left \{ X ,Y,Z\right \}
X={X,Y,Z},它在摄像机二维成像平面上所映射的点为
x
=
{
x
,
y
}
\mathbf{x}=\left \{ x,y\right \}
x={x,y}。则可以得到:

-----------------------------------------------------------------------------------------(6)
------其中
m
=
(
u
,
v
)
m=(u,v)
m=(u,v)表示在图像坐标系下以像素为单位的点,
a
=
{
c
u
,
c
v
,
f
,
α
}
a=\left \{ c_{u} ,c_{v} ,f,\alpha \right \}
a={cu,cv,f,α}为摄像机的内参数。
c
u
c_{u}
cu和
c
u
c_{u}
cu分别表示图像坐标系下光心点的
x
x
x轴方向与
y
y
y轴方向的坐标,
f
f
f表示摄像机的焦距,
α
\alpha
α是摄像机像素长宽比因子。令
s
=
x
=
(
x
,
y
)
s=\mathbf{x}=(x,y)
s=x=(x,y),即以图像坐标系下特征点的坐标作为图像控制特征。对式(6)进行求导有:

--------------------------------------------------------------------------------------------------(7)
-------将三维空间点的速度与摄像机的速度联系起来有:

----------------------------------------------------------------------------------------------------------(8)
将式(8)代入式(7)可整理得到:

-----------------------------------------------------------------------------------------------------------(9)
基于上式的控制方程可写为:
------------------------------------------
x
˙
=
L
x
v
c
\mathbf{\dot{x}}=\mathbf{L_{x}}\mathbf{v_{c}}
x˙=Lxvc----------------------------------------------------------(10)
其中关于图像特征
x
\mathbf{x}
x的图像雅克比矩阵为:

-----------------------------------------------------------------------------------(11)
------在图像雅克比矩阵中,Z的值是特征点在摄像机坐标系下的深度。因此,任何使用基于图像特征点的视觉伺服控制方法均需要对Z进行估计。另一方面,
x
x
x和
y
y
y的计算涉及到了摄像机的内参数,因此不能直接将式(11)代入式(4)形成控制方程,而需要对
x
˙
\mathbf{\dot{x}}
x˙进行估计获得
L
x
^
\hat{\mathbf{L_{x}}}
Lx^
------为了控制机械臂的六个自由度,至少需要三个特征点组成秩为6的图像雅克比矩阵。例如使用特征向量
x
=
(
x
1
,
x
2
,
x
3
)
\mathbf{x}=\left ( x_{1},x_{2}, x_{3}\right )
x=(x1,x2,x3),则可获得图像雅克比矩阵:

------------------------------------------------------------------------(12)
------但在这种情况下,当控制点特征运动到特定位置时图像雅克比矩阵会出现奇异性问题。另外,对于仅依靠3个图像特征点的控制,在这个运动空间中存在4个全局最小值,并且难以相互区分。因此在实际应用中常考虑采用特征点的数目大于3。
------选择好控制特征后,另一个核心问题是如何估计控制方程中的
L
^
e
+
\mathbf{\hat{L}}_{e}^{+}
L^e+,最理想的情况是令
L
^
e
+
=
L
e
+
\mathbf{\hat{L}}_{e}^{+}=\mathbf{L}_{e}^{+}
L^e+=Le+,根据式(11)所得结果,需要在迭代控制过程中的每一步估计当前特征点深度的值Z。但在每次迭代时估计Z的值是十分耗时的方式,因此在设计控制方程时可以选择近似的图像雅克比矩阵。
------常用的雅克比矩阵估计的选择有:(1)
L
^
e
+
=
L
e
∗
+
\mathbf{\hat{L}}_{e}^{+}=\mathbf{L}_{{e}^{*}}^{+}
L^e+=Le∗+其中
L
e
∗
+
\mathbf{L}_{{e}^{*}}^{+}
Le∗+是当机械臂运动到基准位置时
L
e
\mathbf{L}_{e}^{}
Le的值,即
e
=
e
∗
=
0
e=e^{*}=0
e=e∗=0;
L
^
e
+
=
1
/
2
(
L
e
+
L
e
∗
)
+
\mathbf{\hat{L}}_{e}^{+}=1/2{(\mathbf{L_{e}+L_{{e^{*}}}})}^{+}
L^e+=1/2(Le+Le∗)+,虽然这种方法提供了更好的运动轨迹,但由于方程中包含了
L
e
\mathbf{L_{e}}
Le因此需要在每步迭代过程中估计目标特征点的深度信息。.
基础视觉伺服
#include <visp/vpFeatureBuilder.h>
#include <visp/vpServo.h>
#include <visp/vpSimulatorCamera.h>
int main()
{
try {
vpHomogeneousMatrix cdMo(0, 0, 0.75, 0, 0, 0);
vpHomogeneousMatrix cMo(0.15, -0.1, 1.,
vpMath::rad(10), vpMath::rad(-10), vpMath::rad(50));
vpPoint point[4] ;
point[0].setWorldCoordinates(-0.1,-0.1, 0);
point[1].setWorldCoordinates( 0.1,-0.1, 0);
point[2].setWorldCoordinates( 0.1, 0.1, 0);
point[3].setWorldCoordinates(-0.1, 0.1, 0);
vpServo task ;
task.setServo(vpServo::EYEINHAND_CAMERA);
task.setInteractionMatrixType(vpServo::CURRENT);
task.setLambda(0.5);
vpFeaturePoint p[4], pd[4] ;
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cdMo);
vpFeatureBuilder::create(pd[i], point[i]);
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
task.addFeature(p[i], pd[i]);
}
vpHomogeneousMatrix wMc, wMo;
vpSimulatorCamera robot;
robot.setSamplingTime(0.040);
robot.getPosition(wMc);
wMo = wMc * cMo;
for (unsigned int iter=0; iter < 150; iter ++) {
robot.getPosition(wMc);
cMo = wMc.inverse() * wMo;
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
}
vpColVector v = task.computeControlLaw();
robot.setVelocity(vpRobot::CAMERA_FRAME, v);
}
task.kill();
}
catch(vpException e) {
std::cout << "Catch an exception: " << e << std::endl;
}
}
下面详细分析这段代码
#include <visp/vpFeatureBuilder.h>
为实现可视化功能的所有类包括一种公共头文件,特别是在我们的例子vpFeaturePoint中,它将允许我们处理简介中描述的 x = ( x , y ) {\bf x}=(x,y) x=(x,y)。
#include <visp/vpServo.h>
包括实现控制律的vpServo类的头文件
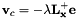
#include <visp/vpSimulatorCamera.h>
包括vpSimulatorCamera类的标题,该类允许模拟6自由度自由飞行摄影机。
然后在main()函数中,我们将摄像机的期望位置和初始位置定义为两个齐次矩阵;cdMo指的是 c ∗ M o {^c}^*{ M}o c∗Mo,cMo指的是 c M o {^c}{ M}o cMo。
vpHomogeneousMatrix cdMo(0, 0, 0.75, 0, 0, 0);
vpHomogeneousMatrix cMo(0.15, -0.1, 1., vpMath::rad(10), vpMath::rad(-10), vpMath::rad(50));
然后我们定义了四个3D点,它们代表一个20cm×20cm正方形的角。
vpPoint point[4] ;
point[0].setWorldCoordinates(-0.1,-0.1, 0);
point[1].setWorldCoordinates( 0.1,-0.1, 0);
point[2].setWorldCoordinates( 0.1, 0.1, 0);
point[3].setWorldCoordinates(-0.1, 0.1, 0);
视觉伺服任务的实例化在下一行中完成。我们将任务初始化为eye in hand 视觉伺服。控制器计算的结果速度是应应用于相机坐标系中的速度: v c { v}_{c} vc。交互矩阵将根据当前的视觉特征进行计算。因此,它们需要在控制循环的每次迭代中更新。最后,恒定增益 λ \lambda λ设置为0.5。
vpServo task ;
task.setServo(vpServo::EYEINHAND_CAMERA);
task.setInteractionMatrixType(vpServo::CURRENT);
task.setLambda(0.5);
现在是将四个视觉特征定义为图像平面中的点的时候了。为此,我们实例化vpFeaturePoint类。当前点特征 s {\bf s} s在p[i]中实现。期望的点特征 s ∗ {\bf s}^* s∗在pd[i]中实现。
vpFeaturePoint p[4], pd[4] ;
通过计算相应相机坐标系中3D点的位置,然后应用透视投影,可以获得每个特征。创建当前和期望的特征后,它们将添加到视觉伺服任务中。
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cdMo);
vpFeatureBuilder::create(pd[i], point[i]);
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
task.addFeature(p[i], pd[i]);
}
对于模拟,我们首先需要创建两个奇次变换wMc和wMo,分别定义摄影机的位置和对象在世界坐标系中的位置。
vpHomogeneousMatrix wMc, wMo;
其次我们创建了一个自由飞行相机的实例。这里我们还将采样时间指定为0.040秒。将速度应用于摄影机时,指数贴图将使用此时间确定摄影机的下一个位置。
vpSimulatorCamera robot;
robot.setSamplingTime(0.040);
最后,从相机的初始位置wMc和之前固定在相机帧cMo中的对象的位置,我们计算对象在世界坐标系wMo中的位置。由于在我们的模拟中,目标是静态的,wMo将保持不变。
robot.getPosition(wMc);
wMo = wMc * cMo;
现在我们可以进入视觉伺服回路。当一个速度应用于我们的自由飞行相机时,相机坐标系wMc的位置将随世界坐标系的变化而变化。根据这个位置,我们计算对象在新相机坐标系中的位置。
robot.getPosition(wMc);
cMo = wMc.inverse() * wMo;
然后,通过在与新相机位置cMo关联的图像平面中投影3D点来更新当前视觉特征。
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
}
最后,计算速度偏差 v c {v}_{c} vc。
vpColVector v = task.computeControlLaw();
然后将此6维速度矢量应用于摄影机。
robot.setVelocity(vpRobot::CAMERA_FRAME, v);
在退出程序之前,我们通过终止任务来释放所有内存。
task.kill();
接下来的教程:“实时曲线绘图仪工具”将演示如何修改上一个示例,以绘制一些曲线来说明视觉伺服行为。
IBVS simulation with basic viewers
可以轻松修改以前的IBVS模拟,以引入基本的内部和外部摄影机查看器。这在教程ibvs-4pts-display.cpp中实现,如下所示:
#include <visp/vpFeatureBuilder.h>
#include <visp/vpServo.h>
#include <visp/vpSimulatorCamera.h>
#include <visp/vpDisplayX.h>
#include <visp/vpDisplayGDI.h>
#include <visp/vpProjectionDisplay.h>
#include <visp/vpServoDisplay.h>
void display_trajectory(const vpImage<unsigned char> &I, std::vector<vpPoint> &point,
const vpHomogeneousMatrix &cMo, const vpCameraParameters &cam);
void display_trajectory(const vpImage<unsigned char> &I, std::vector<vpPoint> &point,
const vpHomogeneousMatrix &cMo, const vpCameraParameters &cam)
{
static std::vector<vpImagePoint> traj[4];
vpImagePoint cog;
for (unsigned int i=0; i<4; i++) {
// Project the point at the given camera position
point[i].project(cMo);
vpMeterPixelConversion::convertPoint(cam, point[i].get_x(), point[i].get_y(), cog);
traj[i].push_back(cog);
}
for (unsigned int i=0; i<4; i++) {
for (unsigned int j=1; j<traj[i].size(); j++) {
vpDisplay::displayLine(I, traj[i][j-1], traj[i][j], vpColor::green);
}
}
}
int main()
{
try {
vpHomogeneousMatrix cdMo(0, 0, 0.75, 0, 0, 0);
vpHomogeneousMatrix cMo(0.15, -0.1, 1.,
vpMath::rad(10), vpMath::rad(-10), vpMath::rad(50));
std::vector<vpPoint> point(4) ;
point[0].setWorldCoordinates(-0.1,-0.1, 0);
point[1].setWorldCoordinates( 0.1,-0.1, 0);
point[2].setWorldCoordinates( 0.1, 0.1, 0);
point[3].setWorldCoordinates(-0.1, 0.1, 0);
vpServo task ;
task.setServo(vpServo::EYEINHAND_CAMERA);
task.setInteractionMatrixType(vpServo::CURRENT);
task.setLambda(0.5);
vpFeaturePoint p[4], pd[4] ;
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cdMo);
vpFeatureBuilder::create(pd[i], point[i]);
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
task.addFeature(p[i], pd[i]);
}
vpHomogeneousMatrix wMc, wMo;
vpSimulatorCamera robot;
robot.setSamplingTime(0.040);
robot.getPosition(wMc);
wMo = wMc * cMo;
vpImage<unsigned char> Iint(480, 640, 255) ;
vpImage<unsigned char> Iext(480, 640, 255) ;
#if defined(VISP_HAVE_X11)
vpDisplayX displayInt(Iint, 0, 0, "Internal view");
vpDisplayX displayExt(Iext, 670, 0, "External view");
#elif defined(VISP_HAVE_GDI)
vpDisplayGDI displayInt(Iint, 0, 0, "Internal view");
vpDisplayGDI displayExt(Iext, 670, 0, "External view");
#else
std::cout << "No image viewer is available..." << std::endl;
#endif
#if defined(VISP_HAVE_DISPLAY)
vpProjectionDisplay externalview;
for (unsigned int i = 0 ; i < 4 ; i++)
externalview.insert(point[i]) ;
#endif
vpCameraParameters cam(840, 840, Iint.getWidth()/2, Iint.getHeight()/2);
vpHomogeneousMatrix cextMo(0,0,3, 0,0,0);
while(1) {
robot.getPosition(wMc);
cMo = wMc.inverse() * wMo;
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
}
vpColVector v = task.computeControlLaw();
robot.setVelocity(vpRobot::CAMERA_FRAME, v);
vpDisplay::display(Iint) ;
vpDisplay::display(Iext) ;
display_trajectory(Iint, point, cMo, cam);
vpServoDisplay::display(task, cam, Iint, vpColor::green, vpColor::red);
#if defined(VISP_HAVE_DISPLAY)
externalview.display(Iext, cextMo, cMo, cam, vpColor::red, true);
#endif
vpDisplay::flush(Iint);
vpDisplay::flush(Iext);
// A click to exit
if (vpDisplay::getClick(Iint, false) || vpDisplay::getClick(Iext, false))
break;
vpTime::wait( robot.getSamplingTime() * 1000);
}
task.kill();
}
catch(vpException e) {
std::cout << "Catch an exception: " << e << std::endl;
}
}
首先,我们添加用于介绍查看器和一些显示功能的类的标题。vpProjectionDisplay 是一个允许从给定相机位置处理外部视图的类,而vpServoDisplay允许在内部相机视图中重叠显示当前和所需特征的位置。
#include <visp/vpDisplayX.h>
#include <visp/vpDisplayGDI.h>
#include <visp/vpProjectionDisplay.h>
#include <visp/vpServoDisplay.h>
其次,我们引入函数display_traction(),该函数允许显示图像中当前特征的轨迹。根据对象坐标系中给定的点的三维坐标,我们计算它们在相机坐标系中的各自位置,然后我们应用透视投影,然后根据相机参数检索它们在图像中的子像素位置。连续的亚像素位置存储在名为traj的向量中,并显示为绿色轨迹。
void display_trajectory(const vpImage<unsigned char> &I, std::vector<vpPoint> &point,
const vpHomogeneousMatrix &cMo, const vpCameraParameters &cam)
{
int thickness = 1;
static std::vector<vpImagePoint> traj[4];
vpImagePoint cog;
for (unsigned int i=0; i<4; i++) {
// Project the point at the given camera position
point[i].project(cMo);
vpMeterPixelConversion::convertPoint(cam, point[i].get_x(), point[i].get_y(), cog);
traj[i].push_back(cog);
}
for (unsigned int i=0; i<4; i++) {
for (unsigned int j=1; j<traj[i].size(); j++) {
vpDisplay::displayLine(I, traj[i][j-1], traj[i][j], vpColor::green, thickness);
}
}
}
然后我们在main()中输入,在这里我们创建两个图像,它们将显示在一个窗口中。第一个图像Iint专用于内部摄像机视图。它显示模拟摄像机看到的图像内容。第二个图像Iext对应于观察模拟摄像机的外部摄像机看到的图像。
vpImage<unsigned char> Iint(480, 640, 255) ;
vpImage<unsigned char> Iext(480, 640, 255) ;
#if defined(VISP_HAVE_X11)
vpDisplayX displayInt(Iint, 0, 0, "Internal view");
vpDisplayX displayExt(Iext, 670, 0, "External view");
#elif defined(VISP_HAVE_GDI)
vpDisplayGDI displayInt(Iint, 0, 0, "Internal view");
vpDisplayGDI displayExt(Iext, 670, 0, "External view");
#else
std::cout << "No image viewer is available..." << std::endl;
#endif
我们创建vpProjectionDisplay类的一个实例。仅当至少安装了一个显示器(X11、GDI、OpenCV、GTK、D3D9)时,此类才可用。这就是我们使用VISP_HAVE_DISPLAY宏的原因。然后插入用于定义目标的点。稍后,将使用在对象帧中定义的这些点的三维坐标,并将其投影到Iext中。
#if defined(VISP_HAVE_DISPLAY)
vpProjectionDisplay externalview;
for (unsigned int i = 0 ; i < 4 ; i++)
externalview.insert(point[i]) ;
#endif
我们初始化display_trajectory()中使用的内在相机参数,以确定视觉特征图像中的像素位置。
vpCameraParameters cam(840, 840, Iint.getWidth()/2, Iint.getHeight()/2);
我们还设置了外部摄像机的位置,以便在伺服过程中观察模拟摄像机的演变。
vpHomogeneousMatrix cextMo(0,0,3, 0,0,0);
最后,在伺服回路的每次迭代中,我们更新查看器:
vpDisplay::display(Iint) ;
vpDisplay::display(Iext) ;
display_trajectory(Iint, point, cMo, cam);
vpServoDisplay::display(task, cam, Iint, vpColor::green, vpColor::red);
#if defined(VISP_HAVE_DISPLAY)
externalview.display(Iext, cextMo, cMo, cam, vpColor::red, true);
#endif
vpDisplay::flush(Iint);
vpDisplay::flush(Iext);
IBVS simulation with wireframe viewers
基本IBVS模拟一节中介绍的IBVS模拟也可以修改,以引入线框内部和外部摄影机查看器。这在教程ibvs-4pts-wireframe-camera-cpp中实现,如下所示:
#include <visp/vpFeatureBuilder.h>
#include <visp/vpServo.h>
#include <visp/vpSimulatorCamera.h>
#include <visp/vpDisplayX.h>
#include <visp/vpDisplayGDI.h>
#include <visp/vpProjectionDisplay.h>
#include <visp/vpServoDisplay.h>
#include <visp/vpWireFrameSimulator.h>
void display_trajectory(const vpImage<unsigned char> &I, std::vector<vpPoint> &point,
const vpHomogeneousMatrix &cMo, const vpCameraParameters &cam);
void display_trajectory(const vpImage<unsigned char> &I, std::vector<vpPoint> &point,
const vpHomogeneousMatrix &cMo, const vpCameraParameters &cam)
{
static std::vector<vpImagePoint> traj[4];
vpImagePoint cog;
for (unsigned int i=0; i<4; i++) {
// Project the point at the given camera position
point[i].project(cMo);
vpMeterPixelConversion::convertPoint(cam, point[i].get_x(), point[i].get_y(), cog);
traj[i].push_back(cog);
}
for (unsigned int i=0; i<4; i++) {
for (unsigned int j=1; j<traj[i].size(); j++) {
vpDisplay::displayLine(I, traj[i][j-1], traj[i][j], vpColor::green);
}
}
}
int main()
{
try {
vpHomogeneousMatrix cdMo(0, 0, 0.75, 0, 0, 0);
vpHomogeneousMatrix cMo(0.15, -0.1, 1., vpMath::rad(10), vpMath::rad(-10), vpMath::rad(50));
std::vector<vpPoint> point(4) ;
point[0].setWorldCoordinates(-0.1,-0.1, 0);
point[1].setWorldCoordinates( 0.1,-0.1, 0);
point[2].setWorldCoordinates( 0.1, 0.1, 0);
point[3].setWorldCoordinates(-0.1, 0.1, 0);
vpServo task ;
task.setServo(vpServo::EYEINHAND_CAMERA);
task.setInteractionMatrixType(vpServo::CURRENT);
task.setLambda(0.5);
vpFeaturePoint p[4], pd[4] ;
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cdMo);
vpFeatureBuilder::create(pd[i], point[i]);
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
task.addFeature(p[i], pd[i]);
}
vpHomogeneousMatrix wMc, wMo;
vpSimulatorCamera robot;
robot.setSamplingTime(0.040);
robot.getPosition(wMc);
wMo = wMc * cMo;
vpImage<unsigned char> Iint(480, 640, 0) ;
vpImage<unsigned char> Iext(480, 640, 0) ;
#if defined VISP_HAVE_X11
vpDisplayX displayInt(Iint, 0, 0, "Internal view");
vpDisplayX displayExt(Iext, 670, 0, "External view");
#elif defined VISP_HAVE_GDI
vpDisplayGDI displayInt(Iint, 0, 0, "Internal view");
vpDisplayGDI displayExt(Iext, 670, 0, "External view");
#else
std::cout << "No image viewer is available..." << std::endl;
#endif
vpCameraParameters cam(840, 840, Iint.getWidth()/2, Iint.getHeight()/2);
vpHomogeneousMatrix cextMo(0,0,3, 0,0,0);
vpWireFrameSimulator sim;
sim.initScene(vpWireFrameSimulator::PLATE, vpWireFrameSimulator::D_STANDARD);
sim.setCameraPositionRelObj(cMo);
sim.setDesiredCameraPosition(cdMo);
sim.setExternalCameraPosition(cextMo);
sim.setInternalCameraParameters(cam);
sim.setExternalCameraParameters(cam);
while(1) {
robot.getPosition(wMc);
cMo = wMc.inverse() * wMo;
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cMo);
vpFeatureBuilder::create(p[i], point[i]);
}
vpColVector v = task.computeControlLaw();
robot.setVelocity(vpRobot::CAMERA_FRAME, v);
sim.setCameraPositionRelObj(cMo);
vpDisplay::display(Iint) ;
vpDisplay::display(Iext) ;
sim.getInternalImage(Iint);
sim.getExternalImage(Iext);
display_trajectory(Iint, point, cMo, cam);
vpDisplay::flush(Iint);
vpDisplay::flush(Iext);
// A click in the internal view to exit
if (vpDisplay::getClick(Iint, false))
break;
vpTime::wait(1000*robot.getSamplingTime());
}
task.kill();
}
catch(vpException e) {
std::cout << "Catch an exception: " << e << std::endl;
}
}
IBVS simulation with image processing
IBVS simulation一节介绍的IBVS simulation可以修改为引入图像处理,允许使用blob跟踪器跟踪点特征。这在tutorial-ibvs-4pts-image-tracking.cpp中实现。代码如下:
#include <visp/vpDisplayX.h>
#include <visp/vpDisplayGDI.h>
#include <visp/vpFeatureBuilder.h>
#include <visp/vpImageIo.h>
#include <visp/vpImageSimulator.h>
#include <visp/vpServo.h>
#include <visp/vpServoDisplay.h>
#include <visp/vpSimulatorCamera.h>
void display_trajectory(const vpImage<unsigned char> &I, const std::vector<vpDot2> &dot);
class vpVirtualGrabber
{
public:
vpVirtualGrabber(const std::string &filename, const vpCameraParameters &cam)
{
// The target is a square 20cm by 2cm square
// Initialise the 3D coordinates of the target corners
for (int i = 0; i < 4; i++) X_[i].resize(3);
// Top left Top right Bottom right Bottom left
X_[0][0] = -0.1; X_[1][0] = 0.1; X_[2][0] = 0.1; X_[3][0] = -0.1;
X_[0][1] = -0.1; X_[1][1] = -0.1; X_[2][1] = 0.1; X_[3][1] = 0.1;
X_[0][2] = 0; X_[1][2] = 0; X_[2][2] = 0; X_[3][2] = 0;
vpImageIo::read(target_, filename);
// Initialize the image simulator
cam_ = cam;
sim_.setInterpolationType(vpImageSimulator::BILINEAR_INTERPOLATION);
sim_.init(target_, X_);
}
void acquire(vpImage<unsigned char> &I, const vpHomogeneousMatrix &cMo)
{
sim_.setCleanPreviousImage(true);
sim_.setCameraPosition(cMo);
sim_.getImage(I, cam_);
}
private:
vpColVector X_[4]; // 3D coordinates of the target corners
vpImageSimulator sim_;
vpImage<unsigned char> target_; // image of the target
vpCameraParameters cam_;
};
void display_trajectory(const vpImage<unsigned char> &I, const std::vector<vpDot2> &dot)
{
static std::vector<vpImagePoint> traj[4];
for (unsigned int i=0; i<4; i++) {
traj[i].push_back(dot[i].getCog());
}
for (unsigned int i=0; i<4; i++) {
for (unsigned int j=1; j<traj[i].size(); j++) {
vpDisplay::displayLine(I, traj[i][j-1], traj[i][j], vpColor::green);
}
}
}
int main()
{
#if defined(VISP_HAVE_X11) || defined(VISP_HAVE_GDI)
try {
vpHomogeneousMatrix cdMo(0, 0, 0.75, 0, 0, 0);
vpHomogeneousMatrix cMo(0.15, -0.1, 1., vpMath::rad(10), vpMath::rad(-10), vpMath::rad(50));
vpImage<unsigned char> I(480, 640, 255);
vpCameraParameters cam(840, 840, I.getWidth()/2, I.getHeight()/2);
std::vector<vpPoint> point(4) ;
point[0].setWorldCoordinates(-0.1,-0.1, 0);
point[1].setWorldCoordinates( 0.1,-0.1, 0);
point[2].setWorldCoordinates( 0.1, 0.1, 0);
point[3].setWorldCoordinates(-0.1, 0.1, 0);
vpServo task ;
task.setServo(vpServo::EYEINHAND_CAMERA);
task.setInteractionMatrixType(vpServo::CURRENT);
task.setLambda(0.5);
vpVirtualGrabber g("./target_square.pgm", cam);
g.acquire(I, cMo);
#if defined(VISP_HAVE_X11)
vpDisplayX d(I, 0, 0, "Current camera view");
#elif defined(VISP_HAVE_GDI)
vpDisplayGDI d(I, 0, 0, "Current camera view");
#else
std::cout << "No image viewer is available..." << std::endl;
#endif
vpDisplay::display(I);
vpDisplay::displayCharString(I, 10, 10,
"Click in the 4 dots to initialise the tracking and start the servo",
vpColor::red);
vpDisplay::flush(I);
vpFeaturePoint p[4], pd[4];
std::vector<vpDot2> dot(4);
for (unsigned int i = 0 ; i < 4 ; i++) {
point[i].track(cdMo);
vpFeatureBuilder::create(pd[i], point[i]);
dot[i].setGraphics(true);
dot[i].initTracking(I);
vpDisplay::flush(I);
vpFeatureBuilder::create(p[i], cam, dot[i].getCog());
task.addFeature(p[i], pd[i]);
}
vpHomogeneousMatrix wMc, wMo;
vpSimulatorCamera robot;
robot.setSamplingTime(0.040);
robot.getPosition(wMc);
wMo = wMc * cMo;
for (; ; ) {
robot.getPosition(wMc);
cMo = wMc.inverse() * wMo;
g.acquire(I, cMo);
vpDisplay::display(I);
for (unsigned int i = 0 ; i < 4 ; i++) {
dot[i].track(I);
vpFeatureBuilder::create(p[i], cam, dot[i].getCog());
vpColVector cP;
point[i].changeFrame(cMo, cP) ;
p[i].set_Z(cP[2]);
}
vpColVector v = task.computeControlLaw();
display_trajectory(I, dot);
vpServoDisplay::display(task, cam, I, vpColor::green, vpColor::red) ;
robot.setVelocity(vpRobot::CAMERA_FRAME, v);
vpDisplay::flush(I);
if (vpDisplay::getClick(I, false))
break;
vpTime::wait( robot.getSamplingTime() * 1000);
}
task.kill();
}
catch(vpException e) {
std::cout << "Catch an exception: " << e << std::endl;
}
#endif
}
首先,我们创建一个白色图像,其中目标将在图像处理之前投影。
vpImage<unsigned char> I(480, 640, 255);
因为我们必须将像素坐标转换为以米为单位表示的视觉特征,所以我们需要初始化相机的内部参数。
vpCameraParameters cam(840, 840, I.getWidth()/2, I.getHeight()/2);
为了检索依赖于模拟摄像机位置的模拟图像,我们创建了一个虚拟抓取器的实例。它的目的是将目标(./target_square.pgm)的图像投影到给定的摄像机位置cMo,然后检索相应的图像I。请注意,.pgm文件中的斑点中心距定义了一个20cm×20cm的正方形。
vpVirtualGrabber g("./target_square.pgm", cam);
g.acquire(I, cMo);
使用vpDot2 blob跟踪器计算当前视觉特征。一旦实例化了四个跟踪器,我们将等待在每个blob中单击鼠标来初始化跟踪器。然后,我们根据相机参数和每个blob的中心距位置计算当前视觉特征 ( x , y ) (x,y) (x,y)。
for (unsigned int i = 0 ; i < 4 ; i++) {
...
dot[i].setGraphics(true);
dot[i].initTracking(I);
vpDisplay::flush(I);
vpFeatureBuilder::create(p[i], cam, dot[i].getCog());
...
}
在视觉伺服回路中,每次迭代我们都会得到目标的新图像。
g.acquire(I, cMo);
我们跟踪每个blob,并像以前一样更新当前视觉特征的值。
for (unsigned int i = 0 ; i < 4 ; i++) {
dot[i].track(I);
vpFeatureBuilder::create(p[i], cam, dot[i].getCog());
如引言中所述,由于交互矩阵 L x \bf L_x Lx取决于 ( x , y ) (x,y) (x,y),但也取决于 Z Z Z特征的深度,因此我们需要更新 Z Z Z。这是通过使用以下工具在相机坐标系中投影目标的每个3D点来实现的:
vpColVector cP;
point[i].changeFrame(cMo, cP) ;
p[i].set_Z(cP[2]);
}

















 949
949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









