







1. 前情提要
虽然这个算法号称的是Deep Dyna-Q网络。但是其实其核心思想用的是DQN网络。特别是在更新策略函数 Q ( s , a ; θ Q ) Q(s,a;θ_Q) Q(s,a;θQ)时,使用的就是DQN的训练思想。每C步更新一次策略函数 Q ( s , a ; θ Q ) Q(s,a;θ_Q) Q(s,a;θQ)的参数 θ Q θ_Q θQ。如第2行和第42行, θ Q ’ = θ Q θ_{Q’ }= θ_Q θQ’=θQ。其中θ_Q是DQN种的预测网络, θ Q ’ θ_{Q’ } θQ’是DQN中的target 网络。 Q ( s , a ; θ Q ) Q(s,a;θ_Q) Q(s,a;θQ)是一个神经网络
与DQN不同的是,DDQ有一个直接学习阶段和一个世界模型,以及两个Reply Buffer,一个是 D u D^u Du,用于存储人与agent交互的transition,一个是 D s D_s Ds,用于存储世界模型 M ( s , a ; θ M ) M(s,a;θ_M) M(s,a;θM)与agent交互的transition。世界模型是一个多任务的神经网络。
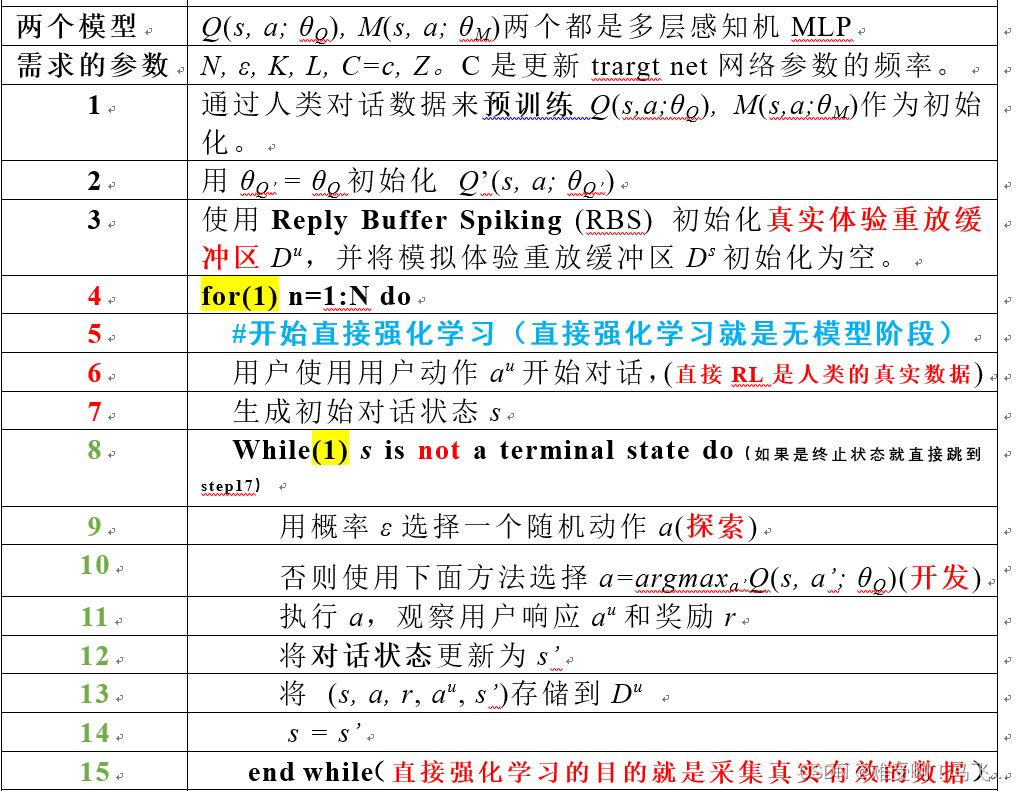
DDQ的创新之处是在Direct RL使用随机初始化的 Q ’ Q’ Q’和 Q Q Q与人类进行对话,从而得到接近真实的交互数据。
agent每与人类完成一次对话,便将对话生成的transition保存在 D u D^u Du中。直到出现终止状态便结束对话,并使用Q-learning方法更新一次 θ Q θ_Q θQ。至此,完成第一步的Direct RL,然后进行世界模型的学习。
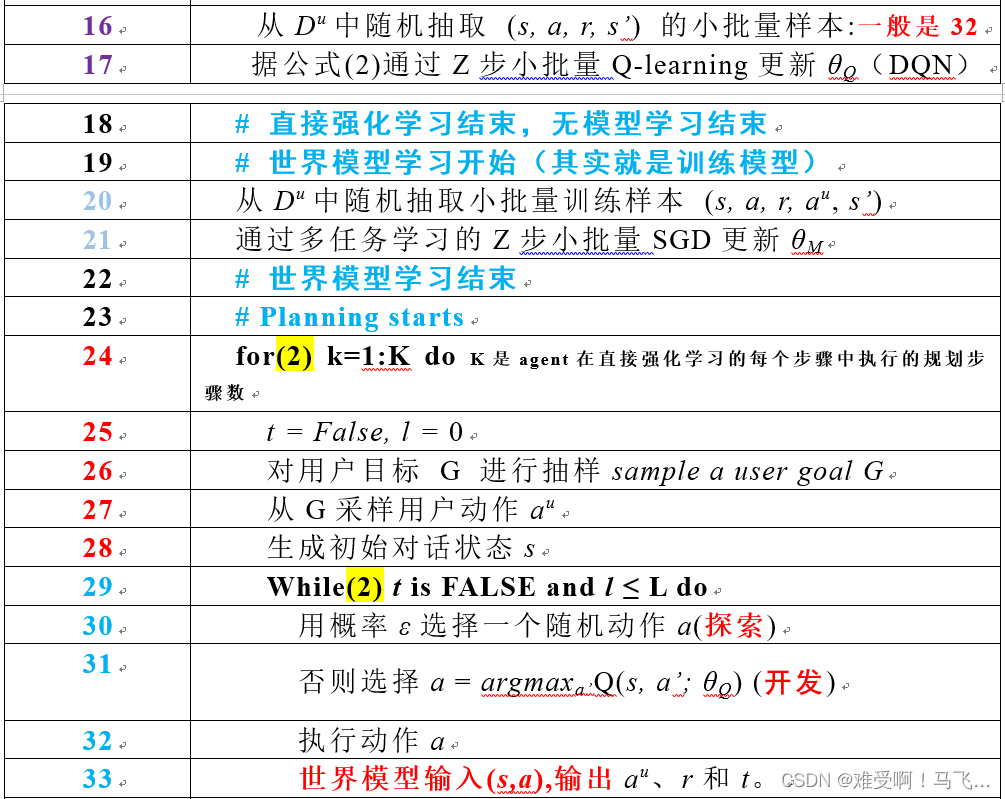
世界模型 M ( s , a ; θ M ) M(s,a;θ_M) M(s,a;θM)从 D u D^u Du提取transition,并训练和更新 θ M θ_M θM。世界模型输入是当前状态 s s s和动作 a a a。输出的是 a u a^u au、 r r r和 t t t。 t t t用于判断当前状态是否是终止状态。
更新好世界模型的参数后,开始Planning阶段。
在分析Planning阶段,需要注意2.2节中的一句话” The first user action au (line 27) can be either a request or an inform dialogueact.”。翻译成中文就是:第一个用户动作au(第27行)可以是请求或通知对话动作。也就是说第一个动作是给定的。然后给定动作 a u a^u au后,得到一个状态 s s s,首先判断该状态是否是终止状态,如果是则结束,不是则在该状态 s s s下随机选择一个动作或者使用argmax选则一个最优动作 a a a。然后将 ( a , s ) (a,s) (a,s)输入到世界模型M中,并生成 a u a^u au、 r r r和 t t t。并得到新的状态 s ’ s’ s’,并将 ( s , a , r , s ’ ) (s, a, r, s’) (s,a,r,s’)存储到 D s D^s Ds中。
当出现终止状态,则世界模型M的Planning过程结束。
然后再从 D s D^s Ds中按批次提取数据,训练策略函数 Q ( s , a ; θ Q ) Q(s,a;θ_Q) Q(s,a;θQ),并更新参数 θ Q θ_Q θQ。
然后查看C的值,当满足次数要求,则执行θQ’ = θQ。否则返回下一个大循环for(1)。
2. 分析算法的四个大循环
具体分析算法的四个循环,两个for循环和两个while循环。
我们将这四个循环的名称命名为:for(1), While(1), for(2),While(2)。下面开始逐个分析:
- for(1)是个大循环,控制算法的训练次数。
- While(1)是直接强化学习的主体部分,是人与智能体进行一次对话,直到对话结束。并保存对话的transition到 D u D^u Du。
- While(1) end
- 对话结束使用中 D u D^u Du的transition更新策略函数 Q ( s , a ; θ Q ) Q(s,a;θ_Q) Q(s,a;θQ)。
- 世界模型也通过 D u D^u Du更新。
- for(2)是对世界模型进行规划。规划次数取决于世界模型M的精度。
- While(2)同样用于对话。是世界模型与agent进行对话。并将对话数据保存到 D s D^s Ds中。
- While(2) end
- 对话结束使用中Ds的transition更新策略函数 Q ( s , a ; θ Q ) Q(s,a;θ_Q) Q(s,a;θQ)。
- for(2) end
- 判断C的值,是否更新 θ Q ’ = θ Q θ_{Q’} = θ_Q θQ’=θQ
- for(1) end
3. 下面是算法的步骤



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









