







说在前面
同一个算法本身存在各种不同的变体,即各种改进版本。一句话+一张图并不能涵盖所有情况,只是尽量用通俗的语言介绍其中经典的算法版本。希望对某算法本身不了解的人看完能迅速get到该算法在干什么;二刷该算法的人能够迅速回忆起算法核心思想和做法,做到能随口讲给别人听。
往期回顾
【机器学习-分类】一句话+一张图 说清楚kNN算法(附案例+代码)
【机器学习-分类】一句话+一张图说清楚决策树算法(附案例+代码)
【机器学习-分类】一句话+一张图说清楚朴素贝叶斯算法(附案例+代码)
一句话
Logistic 回归 或者叫逻辑回归 虽然名字有回归,但是它是用来做分类的。其主要思想是: 根据现有数据对分类边界线(Decision Boundary)建立回归公式,以此进行分类。
一张图
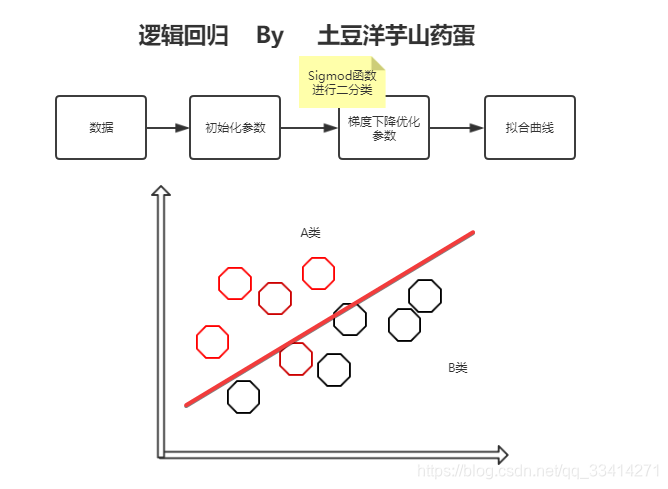
案例
需要进行分类任务的数据如下:
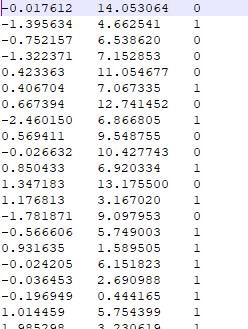
分类代码如下(内含详细注释)
# -*- coding:utf-8 -*-
from numpy import *
###-----------------案例1:简单测试-----------------###
# =============================================================================
# 加载数据
# =============================================================================
def loadDataSet():
dataMat = []; labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
#数据格式为第一列常数1、即X0,第二列为原数据第一列、即X1,同理第三例为X2
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat,labelMat
# =============================================================================
# sigmoid跳跃函数
# =============================================================================
def sigmoid(inX):
return 1.0/(1+exp(-inX))
# =============================================================================
# 改进的随机梯度下降算法
# Args:
# dataMatrix -- 输入数据的数据特征(除去最后一列数据)
# classLabels -- 输入数据的类别标签(最后一列数据)
# numIter=150 -- 迭代次数
# Returns:
# weights -- 得到的最佳回归系数
# =============================================================================
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix) #m行n列数据
weights = ones(n) #初始化权重
# 随机梯度, 循环150,观察是否收敛
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #随着迭代,超参数不断减小
# 随机产生一个 0~len()之间的一个值
# random.uniform(x, y) 方法将随机生成下一个实数,它在[x,y]范围内,x是这个范围内的最小值,y是这个范围内的最大值。
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
# sum(dataMatrix[i]*weights)为了求 f(x)的值, f(x)=a1*x1+b2*x2+..+nn*xn
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
# =============================================================================
# 绘制最好的拟合曲线
# =============================================================================
def plotBestFit(weights):
import matplotlib.pyplot as plt
dataMat,labelMat=loadDataSet()
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(-3.0, 3.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
# =============================================================================
# 分类函数,根据回归系数和特征向量来计算 Sigmoid的值
# =============================================================================
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
# =============================================================================
# 简单测试
# =============================================================================
def simpleTest():
#加载数据
dataArr,labelMat=loadDataSet()
#计算优化权重
weights=stocGradAscent1(array(dataArr),labelMat)
plotBestFit(weights)
#预测一个新样本
#数据为X0,X1,X2
prob=classifyVector([1.0,1.0,9.0], weights)
print(prob)
# =============================================================================
# 主函数
# =============================================================================
if __name__ == "__main__":
simpleTest()
拟合曲线结果如下图
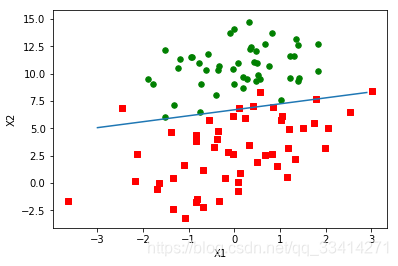
最后一组数据测试分类结果为第0类。














 245
245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









