







注:代码完整版可移步Github——https://github.com/florakl/zhihu_spider。
知乎爬虫与数据分析(一)数据爬取篇
知乎爬虫与数据分析(二)pandas+pyecharts数据可视化分析篇(上)
2 数据处理与可视化分析
2.3 回答文本数据分析——“想知道高赞回答通常有多少字?分多少段?配多少张图?有哪些常用的高频词汇?”
(1)数据预处理
同样的,先读取json文件数据,提取出其中的contents部分,再统计相关文本数据。
我们统计了各个赞数区间回答的平均字数、段落数、每段字数(总字数/段落数)和图片数。为便于对比,字数只统计了中文字符数;而经过对原始文本的观察,发现分段有两种形式,可以通过< p > 或< br/ >标记识别;图片数则可通过“data-actualsrc=”关键词读取。

import re
import pandas as pd
import jieba.analyse
from pyecharts import options as opts
from pyecharts.charts import Bar, WordCloud, Page
from util import data_sort
from data_analysis import read_json
def text_statistics(content):
wordnum = [] # 中文字符数
picnum = [] # 图片数
paranum = [] # 段落数
wordnumpp = [] # 每段字数
for text in content:
data = re.sub('[\u4E00-\u9FA5]', "", text)
a = len(text) - len(data) # 中文字符数
b = text.count('data-actualsrc') # 图片数
c = text.count('<p>') # 段落数标记1
if c == 0:
c = text.count('<br/>') // 2 # 段落数标记2
if c == 0:
c = 1 # 其余情况按段落数=1处理
d = int(a / c) # 每段字数
wordnum.append(a)
picnum.append(b)
paranum.append(c)
wordnumpp.append(d)
return wordnum, picnum, paranum, wordnumpp
将数据按赞数区间进行分组。
def text_distribution(voteup, wordnum, picnum, paranum, wordnumpp, content):
cutpoint = [0, 100, 1000, 4000, 10000, 20000, 40000, 400000]
label = ['A', 'B', 'C', 'D', 'E', 'F', 'G']
cut = pd.cut(voteup, cutpoint, right=False, labels=label)
data = {'分类': cut, '赞数': voteup, '回答字数': wordnum, '图片数': picnum,
'段落数': paranum, '每段字数': wordnumpp, '回答内容': content}
df = pd.DataFrame(data)
return df
(2)不同赞数区间内的文本数据分析
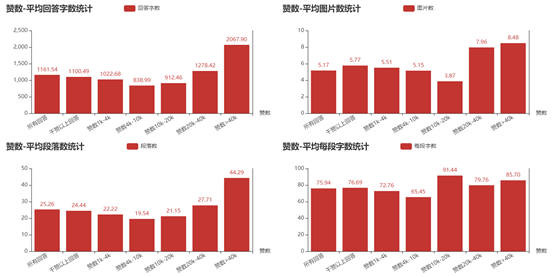
那么,高赞回答在形式上究竟有哪些特征呢?
可以看出,高赞回答平均在千字左右,且赞数越多字数越多(长文预警!),毕竟字数确实能直观地反映出答主的用心程度;
平均一篇回答有5张图,2w赞以上的则是8张左右,看来图片也不是越多越好,保证适当的图量,图文并茂,才更容易吸引关注;
至于平均每段字数这一指标,则罕见地达成了统一:基本每段维持在70-90字。这大概是行文创作的一个普遍段落长度,太长易造成疲劳感,太短又显得过于跳脱,还是适度为好;
而鉴于每段字数的相近,段落数和总字数呈现出了一致的变化趋势。
def text_bar(category, df):
x = ['所有回答', '千赞以上回答', '赞数1k-4k', '赞数4k-10k', '赞数10k-20k', '赞数20k-40k', '赞数>40k']
total_mean = df[category].mean()
part_mean = df[~df['分类'].isin(['A', 'B'])][category].mean()
y = [total_mean, part_mean]
mean = df[category].groupby(df['分类']).mean()
y += list(mean)[2:]
y = ['%.2f' % a for a in y]
bar = (
Bar(init_opts=opts.InitOpts(width="600px", height="300px"))
.add_xaxis(x)
.add_yaxis(category, y)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts()))
.set_series_opts(label_opts=opts.LabelOpts(is_show=True), linestyle_opts=opts.LineStyleOpts(width=2))
.set_global_opts(
title_opts=opts.TitleOpts(title=f'赞数-平均{category}统计'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=30), name='赞数'),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts())
)
)
filename = f'赞数-平均{category}统计.html'
bar.render(filename)
print('图表创建成功')
return bar
(3)万赞以上回答的字数分布统计
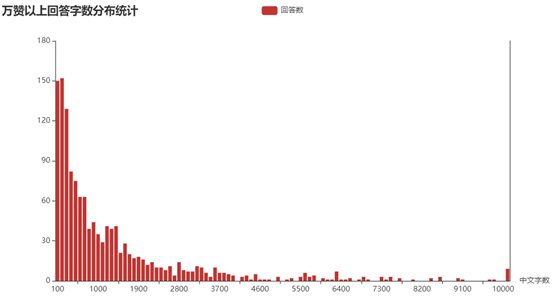
不过单独观察万赞以上回答的字数分布情况,可以看到300字以内的回答占了三分之一,700字以内的超过一半,说明大多数回答仍只是一个小作文的篇幅。
def wordnum_analysis(df):
# 万赞以上回答的字数分布
cutpoint = list(range(0, 10100, 100))
cutpoint.append(24000) # 最大字数在24000字以内
words = list(df[df['分类'].isin(['E', 'F', 'G'])]['回答字数'])
cut = pd.cut(words, cutpoint, right=False)
counts = pd.value_counts(cut)
x = list(counts.index)
y = list(counts)
_, y0 = data_sort(x, y)
labels = []
for i in range(100, 10100, 100):
label = str(i)
labels.append(label)
labels.append('>10000')
bar = (
Bar()
.add_xaxis(labels)
.add_yaxis('回答数', y0)
.extend_axis(yaxis=opts.AxisOpts(axislabel_opts=opts.LabelOpts()))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False), linestyle_opts=opts.LineStyleOpts(width=2))
.set_global_opts(
title_opts=opts.TitleOpts(title='万赞以上回答字数分布统计'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(), name='中文字数'),
yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts())
)
)
filename = '万赞以上回答字数分布统计.html'
bar.render(filename)
print('图表创建成功')
return bar
(4)词云统计

最后,针对千赞以上共380万字的3097个回答,做了一个简单的词云分析。这些高频关键词还是很接地气的,都是些非常生活化的意象。词云使用的utf-8格式停止词txt和代码一起放在了github上。
此外,如此丰富的文本量拿来仅仅做一个词云统计似乎有些浪费,有机会我将进行更多文本分析。
def char_filter(df):
contents = list(df[~df['分类'].isin(['A', 'B'])]['回答内容'])
filename = 'contents.txt'
with open(filename, 'w', encoding='utf-8') as f:
for text in contents:
data = re.sub(u"\\<.*?\\>", "", text)
f.write(data)
print("回答写入完毕")
def wordcloud(path):
with open(path, 'r', encoding='utf-8') as f:
contents = f.read()
jieba.analyse.set_stop_words('stopwords.txt') # 停止词文件路径
weights = jieba.analyse.extract_tags(contents, topK=100, withWeight=True) # 取前100个词汇
data = []
for word, weight in weights:
flag = True
for ch in word:
# 只保留中文分词结果
if not (u'\u4e00' <= ch <= u'\u9fff'):
flag = False
break
if flag:
tup = (word, str(int(weight * 10000)))
data.append(tup)
(
WordCloud()
.add(series_name="高频词语分析", data_pair=data, word_size_range=[12, 100])
.set_global_opts(
title_opts=opts.TitleOpts(title="高频词语分析"),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
.render("高频词语分析.html")
)
3 总结
通过以上分析,现在可以对最初提到的三个问题做个简单的回答了。
①在问题提出后多久去发表回答更容易火起来?
总体来说问题有一定热度后越早越好。
实时热榜问题尽早进去分一杯羹为妙,过了这个村就没这个店了,除非你对自己的粉丝数或者内容质量有绝对的自信;而热度经久不衰的问题则随时可以去回答,不过前提是你确定日常浏览量真的很大,真的经久不衰。
②是不是高赞答主一般都自带粉丝?小透明还有戏吗?
粉丝数对曝光率肯定有很大加成,但小透明也不用泄气,是金子总有发光的一天!
③想知道高赞回答通常有多少字?分多少段?配多少张图?有哪些常用的高频词汇?
回答写几百字就差不多了,千字以内为佳,除非你确定自己写的干货满满,能撑得过“太长不看”;每段字数保持在80字上下,适当配几张图,控制好阅读节奏,保证文字平易近人,不晦涩难懂,偶尔举几个“我朋友/亲戚/同学/…”的例子丰富一下趣味性,至少形式上就不会有大问题啦!
最后的最后,本次分析的样本数据量还是非常小的,因此以上结论也仅供娱乐~















 3401
3401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









