






如何批量下载网页的图片?在日常工作中,我们经常会遇到需要从网页上批量下载图片的情况,无论是为了市场调研、设计素材收集,还是内容创作准备,这一需求都显得尤为迫切。面对网页上琳琅满目的图片资源,手动一张一张保存不仅效率低下,而且容易出错。为此,掌握一种高效、便捷的批量下载图片方法显得尤为重要。市面上已经有许多成熟的浏览器插件和第三方软件能够实现这一功能,它们通常具备智能识别网页中的图片、支持多种格式下载、可自定义下载路径等特性。用户只需简单设置,即可一键启动下载,极大地提高了工作效率。
那么用什么方法可以快速批量的下载网页上的图片呢?下面这里将为大家介绍两种方法,两种方法都需要借助工具才能完成,请试着按照步骤一起操作吧,相信你可以立即学会。

方法一:使用“星优图片下载助手”软件批量下载网页图片
软件工具下载地址:https://www.xingyousoft.com/softcenter/XYCapture
步骤1、首次使用“星优图片下载助手”这个软件的小伙伴需要将它安装到电脑上,安装结束后打开使用,随后在左侧列表里选择【其他网址】图片下载功能。(此外软件还支持另外几个特殊图片下载渠道,分别是:天猫、京东、淘宝和阿里巴巴,有需要的自行选择)
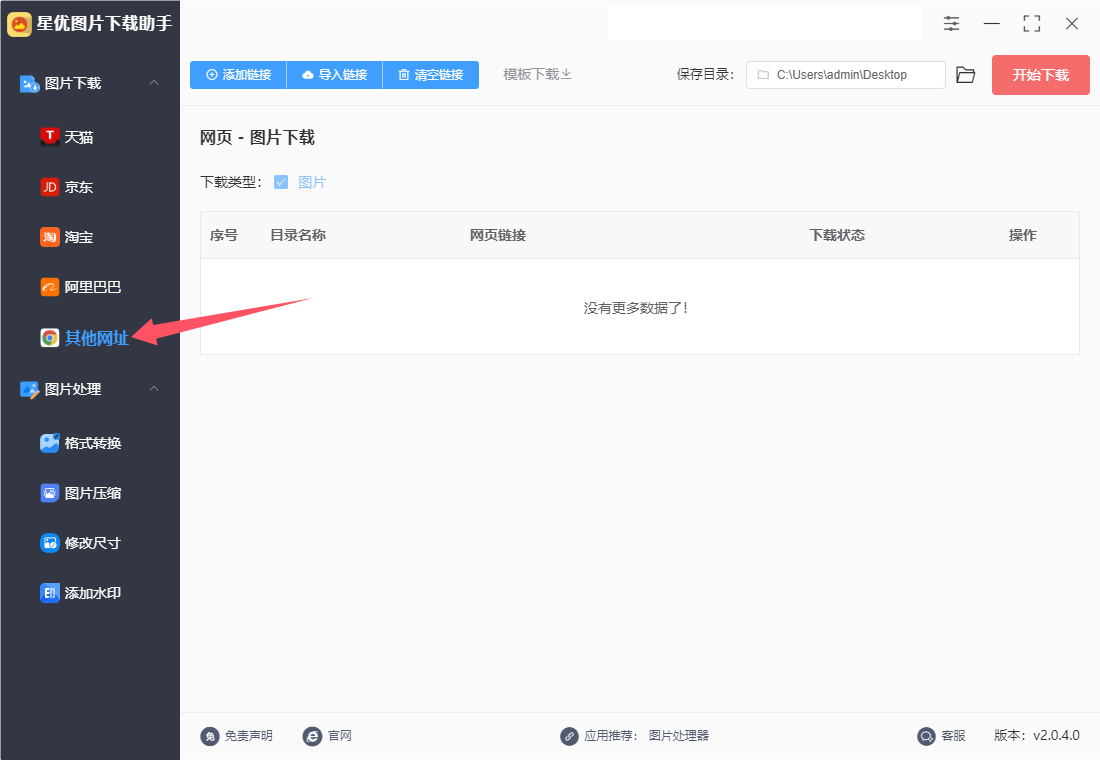
步骤2,然后就需要添加网址链接到软件里,两种方式,下面是详细的介绍。
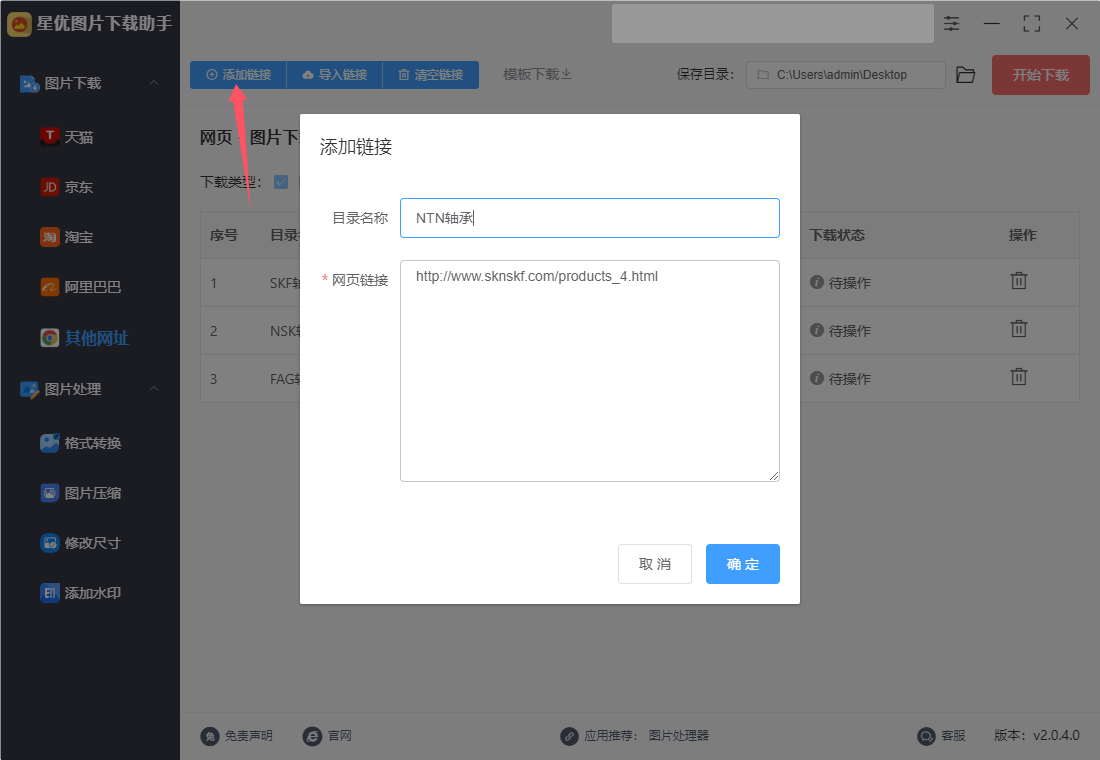
方式①:点击【添加连接】按键后弹出添加窗口,这里你需要输入目录名称(也就是链接名称,随意设置,方便自己识别即可),然后输入链接,最后点击“确定”按键。
方式②:点击【导入链接】按键,随后将包含链接的excel文件导入到软件里,导入成功后会显示连接列表,excel第一列填写目录名称,第二列添加连接,并且软件上有excel模板可以下载。(这个方式适合批量链接添加)
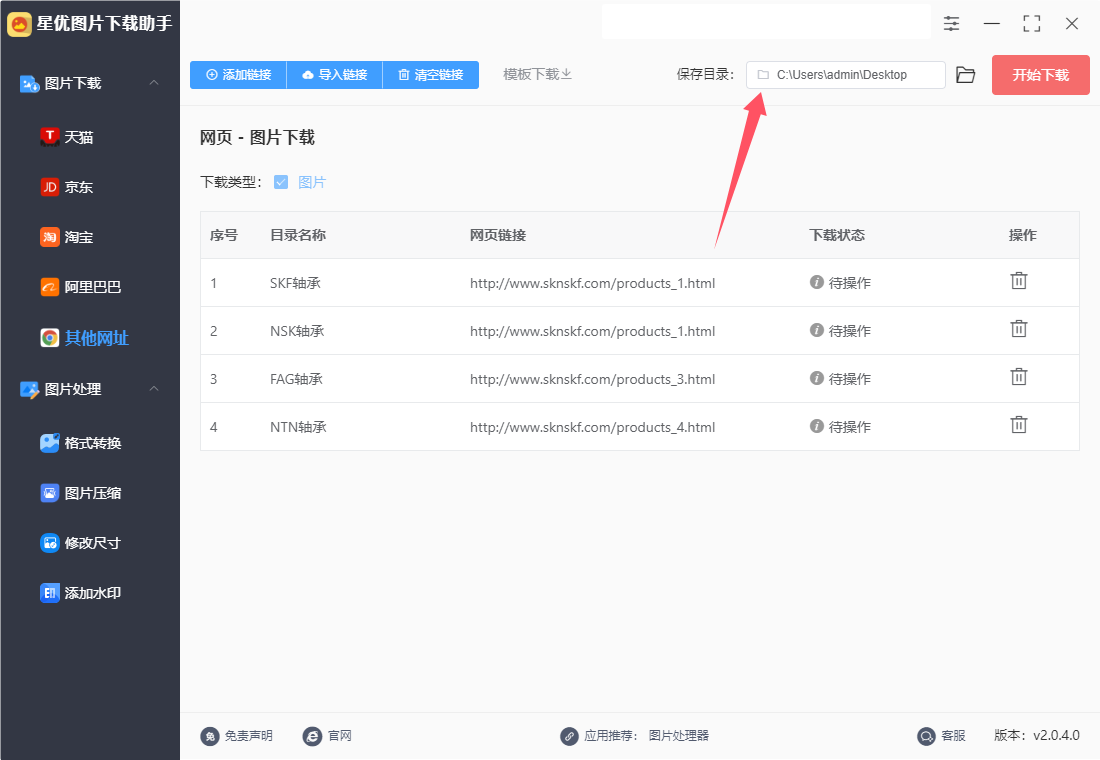
步骤3(可选),你还可以设置一下保存目录,指定电脑上的一个目录用来保存下载下来的图片,当然这一步也可以忽略,默认保存位置是电脑桌面。
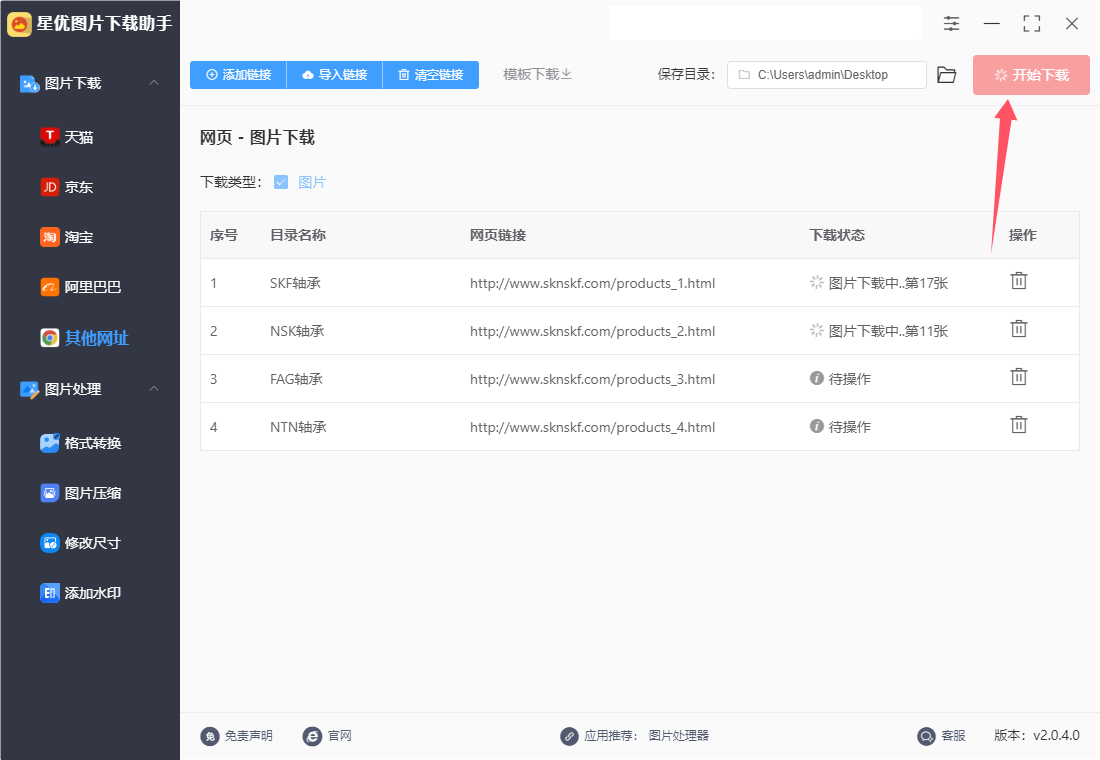
步骤4,最后点击软件右上角的【开始下载】红色按键启动软件,这样图片批量下载程序就被启动了,页面图片越多下载时间就越久,下载完成后状态慢下面会提示下载完成。
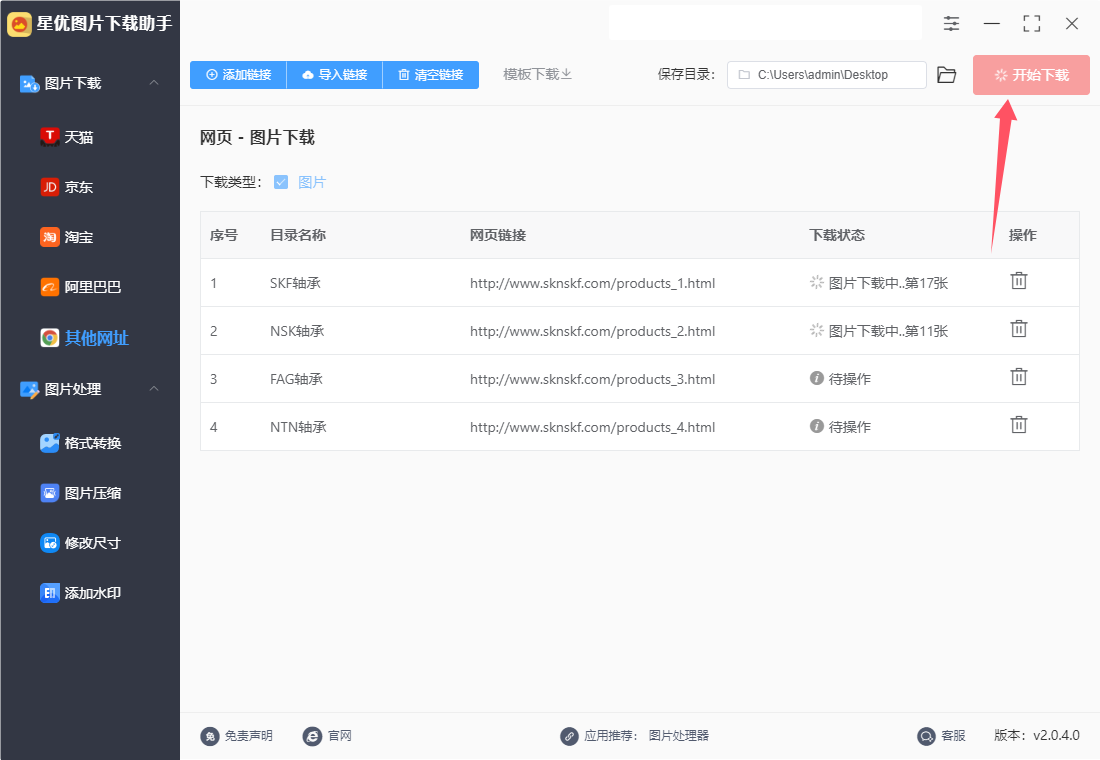
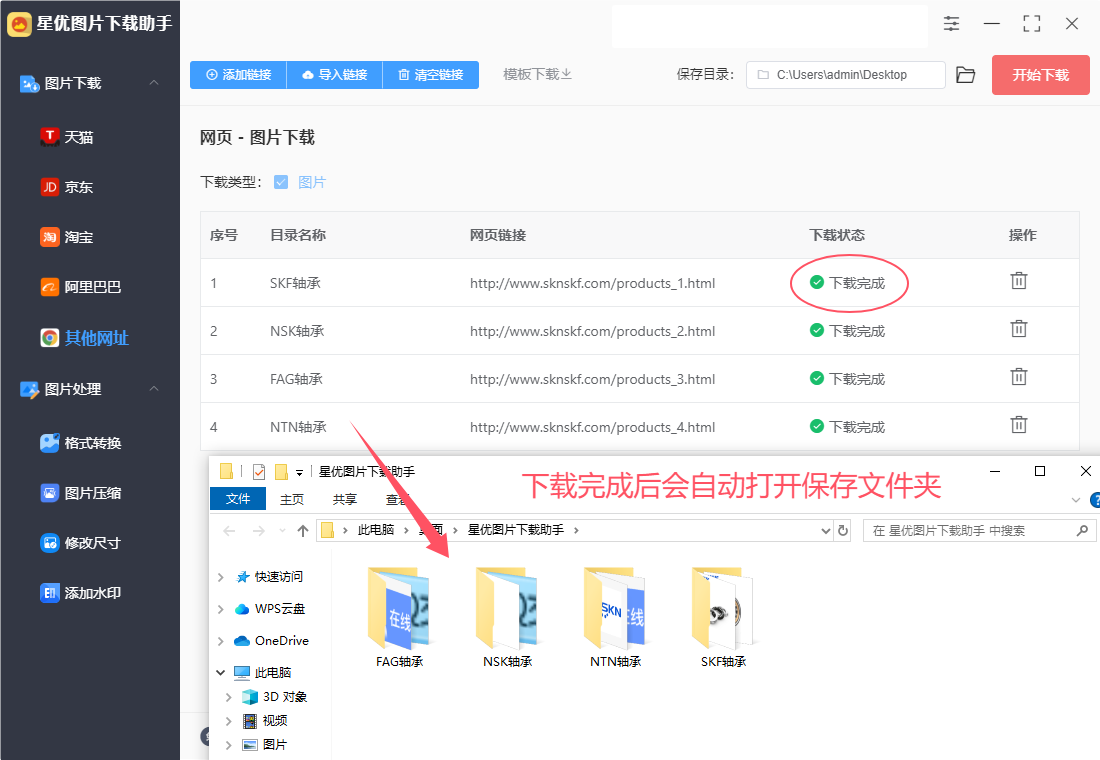
步骤5,下载完成后软件还会自动打开保存目录所在位置,可以看到下载到的图片就保存在这个文件夹里,便于我们查看和使用,一个链接对应一个文件夹,比较清晰。
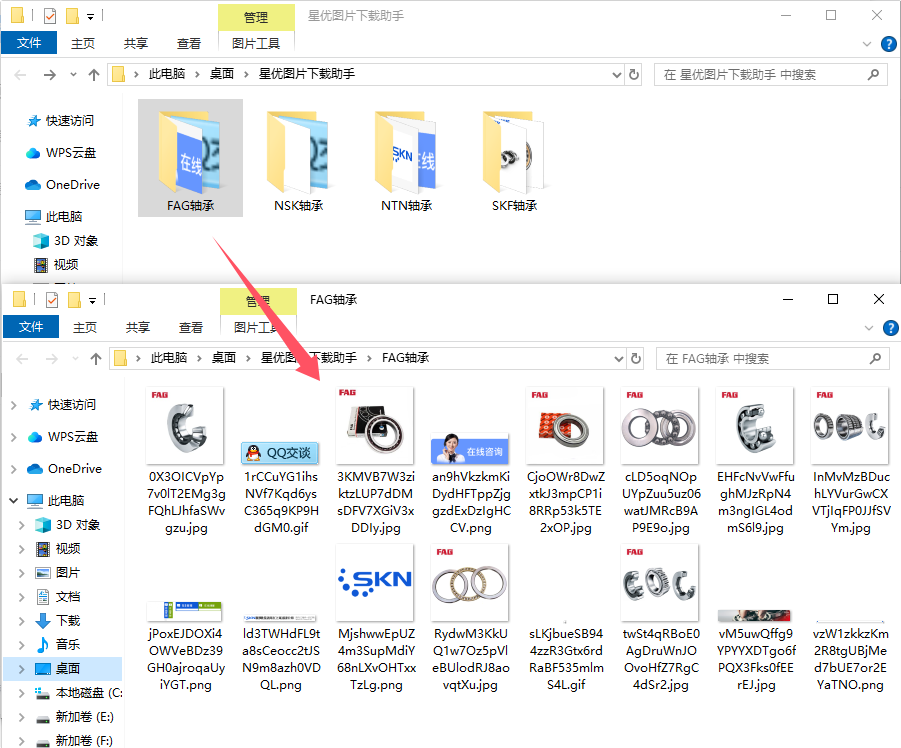
步骤6,打开一个文件夹可以看到,整个页面链接上的图片被全部下载到这里了,批量下载效率非常高。
方法二:编写python代码批量下载京东图片
批量下载网页上的图片,通常需要根据网页的结构(如HTML结构)来定位图片资源,并使用Python中的库如requests来下载这些资源。以下是一个基本的步骤和示例代码,用于演示如何从一个简单的网页中批量下载图片。
一、步骤
① 确定图片资源的URL:首先,你需要确定图片在网页上的具体URL。这通常可以通过查看网页的HTML源代码来完成。
② 使用requests库下载图片:使用Python的requests库来下载图片。
③ 保存图片到本地:将下载的图片保存到本地文件系统中。
④ 遍历所有图片:如果网页上有多个图片,你需要遍历所有图片资源并重复上述过程。
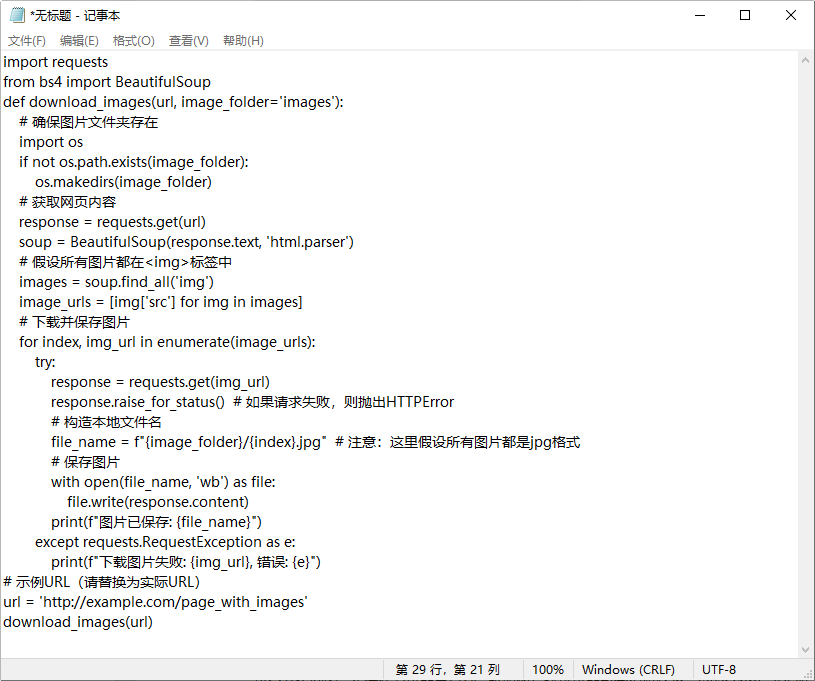
二、示例代码
这里提供一个简单的示例,假设我们已知一个网页上所有图片的URL都在一个特定的HTML标签内(例如<img src="...">),并且这些URL可以直接用于下载。
import requests
from bs4 import BeautifulSoup
def download_images(url, image_folder='images'):
# 确保图片文件夹存在
import os
if not os.path.exists(image_folder):
os.makedirs(image_folder)
# 获取网页内容
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# 假设所有图片都在<img>标签中
images = soup.find_all('img')
image_urls = [img['src'] for img in images]
# 下载并保存图片
for index, img_url in enumerate(image_urls):
try:
response = requests.get(img_url)
response.raise_for_status() # 如果请求失败,则抛出HTTPError
# 构造本地文件名
file_name = f"{image_folder}/{index}.jpg" # 注意:这里假设所有图片都是jpg格式
# 保存图片
with open(file_name, 'wb') as file:
file.write(response.content)
print(f"图片已保存: {file_name}")
except requests.RequestException as e:
print(f"下载图片失败: {img_url}, 错误: {e}")
# 示例URL(请替换为实际URL)
url = 'http://example.com/page_with_images'
download_images(url)
注意:
① 这个示例假设所有图片都是直接通过<img src="...">标签的src属性链接的,并且都是可公开访问的。实际情况可能更复杂,比如图片链接可能包含相对路径、JavaScript动态加载、或是需要通过登录认证等。
② 在实际使用时,你可能需要处理多种图片格式,因此可能需要根据URL或响应头来确定文件的实际扩展名,而不是像示例中那样简单地假设所有图片都是.jpg格式。
③ 示例中使用了BeautifulSoup来解析HTML,它是一个非常强大的库,能够方便地处理复杂的HTML结构。
④ 确保遵守网站的robots.txt文件和版权政策,不要非法下载或滥用图片资源。
当你需要批量下载网页上的图片时,效率和方法至关重要。尤其在涉及大量图像时,手动保存每张图片不仅繁琐,而且耗时。因此,掌握一些有效的批量下载技巧可以显著提高工作效率。总之,批量下载网页上的图片是现代工作中不可或缺的一项技能。通过合理利用相关工具,我们可以轻松应对这一挑战,为工作带来便利与高效。上面小编分享的两个“如何批量下载网页的图片?”操作技巧分享就全部到这里就结束了,感谢大家的支持,感兴趣的朋友赶紧去试试看吧。















 2655
2655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









