









有个数据的论文seesee GoEmotions: A Dataset of Fine-Grained Emotions
SpanEmo: Casting Multi-label Emotion Classification as Span-prediction
代码地址:https://github.com/fp674018495/SpanEmo

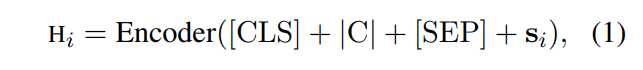
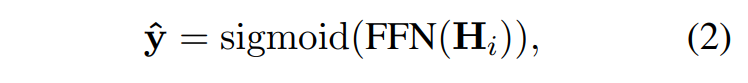
对于下面中的公式理解,在 |y0| 表示0标号个数,|y1| 表示1标签的个数, 可能对于和
太理解
这个我举个例子 : 如果这是一个十种分类的问题 真实的 y_ture=[0,0,0,0,0,1,1,1,1,1] ,那对应的的值就是模型预测的y_pre[0:5]的值,
就是 y_pre[5:10].unsqueeze(-1) 其中进行了扩维的处理是能够让数据减的时候彼此都能相减 这个叫做 broadcasting ,其实这个函数用了一个先验概率。
这损失函数的目的是通过隐式保留标签依赖性信息,使积极标签和消极标签之间的距离最大化。换句话说,当模型预测了一对不应该共存给定示例中的标签时,它应该受到惩罚。
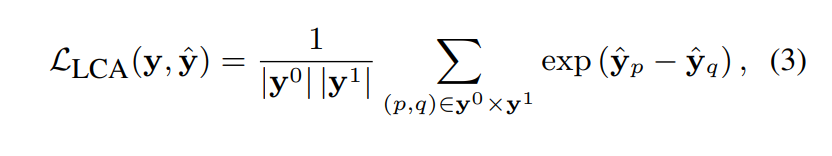
















 667
667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









